 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChildren's Speech Recognition through Discrete Token Enhancement
Jun 19, 2024Children's speech recognition is considered a low-resource task mainly due to the lack of publicly available data. There are several reasons for such data scarcity, including expensive data collection and annotation processes, and data privacy, among others. Transforming speech signals into discrete tokens that do not carry sensitive information but capture both linguistic and acoustic information could be a solution for privacy concerns. In this study, we investigate the integration of discrete speech tokens into children's speech recognition systems as input without significantly degrading the ASR performance. Additionally, we explored single-view and multi-view strategies for creating these discrete labels. Furthermore, we tested the models for generalization capabilities with unseen domain and nativity dataset. Results reveal that the discrete token ASR for children achieves nearly equivalent performance with an approximate 83% reduction in parameters.
The Tag-Team Approach: Leveraging CLS and Language Tagging for Enhancing Multilingual ASR
May 31, 2023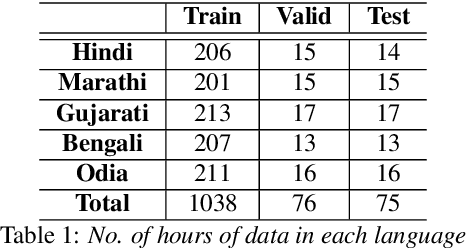

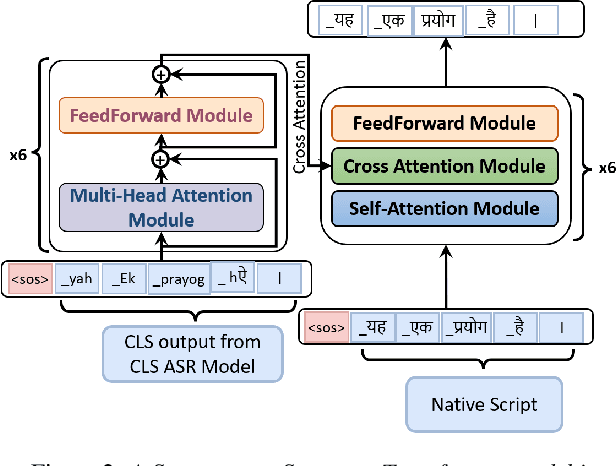

Building a multilingual Automated Speech Recognition (ASR) system in a linguistically diverse country like India can be a challenging task due to the differences in scripts and the limited availability of speech data. This problem can be solved by exploiting the fact that many of these languages are phonetically similar. These languages can be converted into a Common Label Set (CLS) by mapping similar sounds to common labels. In this paper, new approaches are explored and compared to improve the performance of CLS based multilingual ASR model. Specific language information is infused in the ASR model by giving Language ID or using CLS to Native script converter on top of the CLS Multilingual model. These methods give a significant improvement in Word Error Rate (WER) compared to the CLS baseline. These methods are further tried on out-of-distribution data to check their robustness.
Channel-Aware Pretraining of Joint Encoder-Decoder Self-Supervised Model for Telephonic-Speech ASR
Nov 03, 2022



This paper proposes a novel technique to obtain better downstream ASR performance from a joint encoder-decoder self-supervised model when trained with speech pooled from two different channels (narrow and wide band). The joint encoder-decoder self-supervised model extends the HuBERT model with a Transformer decoder. HuBERT performs clustering of features and predicts the class of every input frame. In simple pooling, which is our baseline, there is no way to identify the channel information. To incorporate channel information, we have proposed non-overlapping cluster IDs for speech from different channels. Our method gives a relative improvement of ~ 5% over the joint encoder-decoder self-supervised model built with simple pooling of data, which serves as our baseline.
Domain Adaptation of low-resource Target-Domain models using well-trained ASR Conformer Models
Feb 18, 2022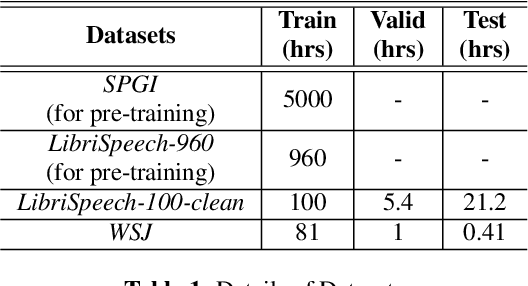
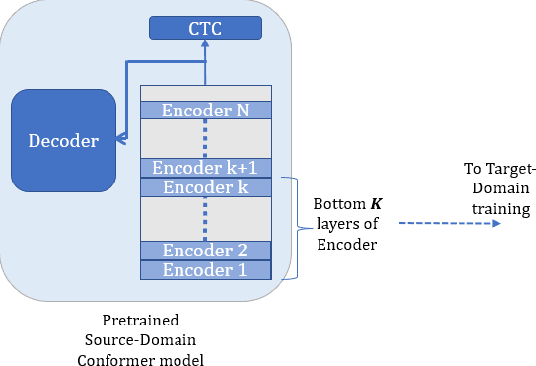

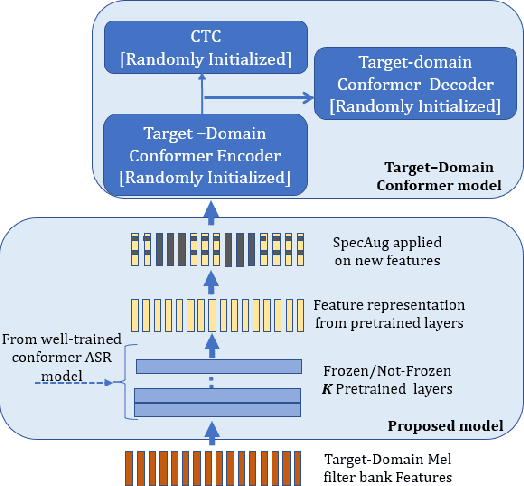
In this paper, we investigate domain adaptation for low-resource Automatic Speech Recognition (ASR) of target-domain data, when a well-trained ASR model trained with a large dataset is available. We argue that in the encoder-decoder framework, the decoder of the well-trained ASR model is largely tuned towards the source-domain, hurting the performance of target-domain models in vanilla transfer-learning. On the other hand, the encoder layers of the well-trained ASR model mostly capture the acoustic characteristics. We, therefore, propose to use the embeddings tapped from these encoder layers as features for a downstream Conformer target-domain model and show that they provide significant improvements. We do ablation studies on which encoder layer is optimal to tap the embeddings, as well as the effect of freezing or updating the well-trained ASR model's encoder layers. We further show that applying Spectral Augmentation (SpecAug) on the proposed features (this is in addition to default SpecAug on input spectral features) provides a further improvement on the target-domain performance. For the LibriSpeech-100-clean data as target-domain and SPGI-5000 as a well-trained model, we get 30% relative improvement over baseline. Similarly, with WSJ data as target-domain and LibriSpeech-960 as a well-trained model, we get 50% relative improvement over baseline.