 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
Jan 26, 2026Cooperative reasoning under incomplete information remains challenging for both humans and multi-agent systems. The card game Hanabi embodies this challenge, requiring theory-of-mind reasoning and strategic communication. We benchmark 17 state-of-the-art LLM agents in 2-5 player games and study the impact of context engineering across model scales (4B to 600B+) to understand persistent coordination failures and robustness to scaffolding: from a minimal prompt with only explicit card details (Watson setting), to scaffolding with programmatic, Bayesian-motivated deductions (Sherlock setting), to multi-turn state tracking via working memory (Mycroft setting). We show that (1) agents can maintain an internal working memory for state tracking and (2) cross-play performance between different LLMs smoothly interpolates with model strength. In the Sherlock setting, the strongest reasoning models exceed 15 points on average across player counts, yet still trail experienced humans and specialist Hanabi agents, both consistently scoring above 20. We release the first public Hanabi datasets with annotated trajectories and move utilities: (1) HanabiLogs, containing 1,520 full game logs for instruction tuning, and (2) HanabiRewards, containing 560 games with dense move-level value annotations for all candidate moves. Supervised and RL finetuning of a 4B open-weight model (Qwen3-Instruct) on our datasets improves cooperative Hanabi play by 21% and 156% respectively, bringing performance to within ~3 points of a strong proprietary reasoning model (o4-mini) and surpassing the best non-reasoning model (GPT-4.1) by 52%. The HanabiRewards RL-finetuned model further generalizes beyond Hanabi, improving performance on a cooperative group-guessing benchmark by 11%, temporal reasoning on EventQA by 6.4%, instruction-following on IFBench-800K by 1.7 Pass@10, and matching AIME 2025 mathematical reasoning Pass@10.
Building Robust and Scalable Multilingual ASR for Indian Languages
Nov 19, 2025This paper describes the systems developed by SPRING Lab, Indian Institute of Technology Madras, for the ASRU MADASR 2.0 challenge. The systems developed focuses on adapting ASR systems to improve in predicting the language and dialect of the utterance among 8 languages across 33 dialects. We participated in Track 1 and Track 2, which restricts the use of additional data and develop from-the-scratch multilingual systems. We presented a novel training approach using Multi-Decoder architecture with phonemic Common Label Set (CLS) as intermediate representation. It improved the performance over the baseline (in the CLS space). We also discuss various methods used to retain the gain obtained in the phonemic space while converting them back to the corresponding grapheme representations. Our systems beat the baseline in 3 languages (Track 2) in terms of WER/CER and achieved the highest language ID and dialect ID accuracy among all participating teams (Track 2).
The Tag-Team Approach: Leveraging CLS and Language Tagging for Enhancing Multilingual ASR
May 31, 2023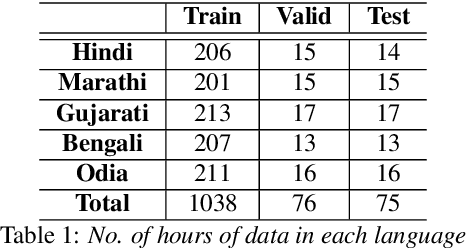

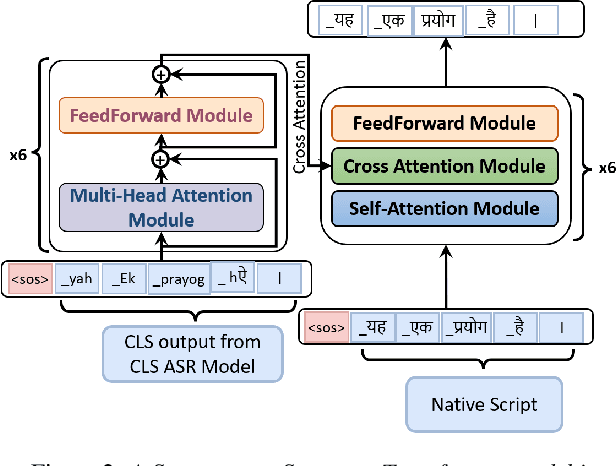

Building a multilingual Automated Speech Recognition (ASR) system in a linguistically diverse country like India can be a challenging task due to the differences in scripts and the limited availability of speech data. This problem can be solved by exploiting the fact that many of these languages are phonetically similar. These languages can be converted into a Common Label Set (CLS) by mapping similar sounds to common labels. In this paper, new approaches are explored and compared to improve the performance of CLS based multilingual ASR model. Specific language information is infused in the ASR model by giving Language ID or using CLS to Native script converter on top of the CLS Multilingual model. These methods give a significant improvement in Word Error Rate (WER) compared to the CLS baseline. These methods are further tried on out-of-distribution data to check their robustness.