 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABEX: Data Augmentation for Low-Resource NLU via Expanding Abstract Descriptions
Jun 06, 2024



We present ABEX, a novel and effective generative data augmentation methodology for low-resource Natural Language Understanding (NLU) tasks. ABEX is based on ABstract-and-EXpand, a novel paradigm for generating diverse forms of an input document -- we first convert a document into its concise, abstract description and then generate new documents based on expanding the resultant abstraction. To learn the task of expanding abstract descriptions, we first train BART on a large-scale synthetic dataset with abstract-document pairs. Next, to generate abstract descriptions for a document, we propose a simple, controllable, and training-free method based on editing AMR graphs. ABEX brings the best of both worlds: by expanding from abstract representations, it preserves the original semantic properties of the documents, like style and meaning, thereby maintaining alignment with the original label and data distribution. At the same time, the fundamental process of elaborating on abstract descriptions facilitates diverse generations. We demonstrate the effectiveness of ABEX on 4 NLU tasks spanning 12 datasets and 4 low-resource settings. ABEX outperforms all our baselines qualitatively with improvements of 0.04% - 38.8%. Qualitatively, ABEX outperforms all prior methods from literature in terms of context and length diversity.
DALE: Generative Data Augmentation for Low-Resource Legal NLP
Oct 24, 2023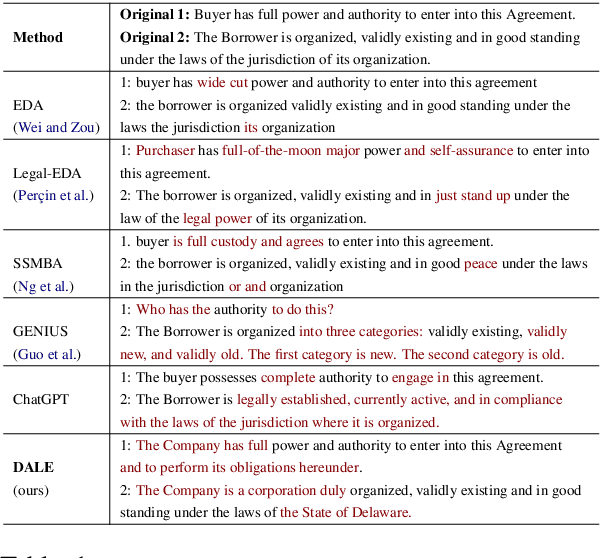

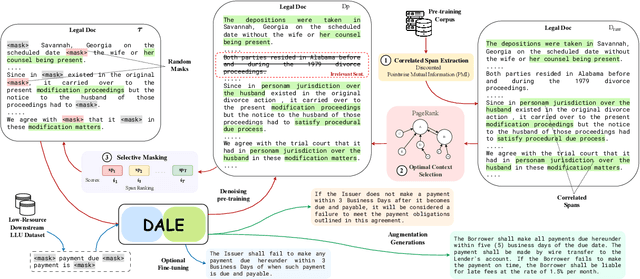

We present DALE, a novel and effective generative Data Augmentation framework for low-resource LEgal NLP. DALE addresses the challenges existing frameworks pose in generating effective data augmentations of legal documents - legal language, with its specialized vocabulary and complex semantics, morphology, and syntax, does not benefit from data augmentations that merely rephrase the source sentence. To address this, DALE, built on an Encoder-Decoder Language Model, is pre-trained on a novel unsupervised text denoising objective based on selective masking - our masking strategy exploits the domain-specific language characteristics of templatized legal documents to mask collocated spans of text. Denoising these spans helps DALE acquire knowledge about legal concepts, principles, and language usage. Consequently, it develops the ability to generate coherent and diverse augmentations with novel contexts. Finally, DALE performs conditional generation to generate synthetic augmentations for low-resource Legal NLP tasks. We demonstrate the effectiveness of DALE on 13 datasets spanning 6 tasks and 4 low-resource settings. DALE outperforms all our baselines, including LLMs, qualitatively and quantitatively, with improvements of 1%-50%.
ACLM: A Selective-Denoising based Generative Data Augmentation Approach for Low-Resource Complex NER
Jun 01, 2023



Complex Named Entity Recognition (NER) is the task of detecting linguistically complex named entities in low-context text. In this paper, we present ACLM Attention-map aware keyword selection for Conditional Language Model fine-tuning), a novel data augmentation approach based on conditional generation to address the data scarcity problem in low-resource complex NER. ACLM alleviates the context-entity mismatch issue, a problem existing NER data augmentation techniques suffer from and often generates incoherent augmentations by placing complex named entities in the wrong context. ACLM builds on BART and is optimized on a novel text reconstruction or denoising task - we use selective masking (aided by attention maps) to retain the named entities and certain keywords in the input sentence that provide contextually relevant additional knowledge or hints about the named entities. Compared with other data augmentation strategies, ACLM can generate more diverse and coherent augmentations preserving the true word sense of complex entities in the sentence. We demonstrate the effectiveness of ACLM both qualitatively and quantitatively on monolingual, cross-lingual, and multilingual complex NER across various low-resource settings. ACLM outperforms all our neural baselines by a significant margin (1%-36%). In addition, we demonstrate the application of ACLM to other domains that suffer from data scarcity (e.g., biomedical). In practice, ACLM generates more effective and factual augmentations for these domains than prior methods. Code: https://github.com/Sreyan88/ACLM