 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCLAP: Improving Zero Shot Audio Classification by Describing Sounds
Paper and Code
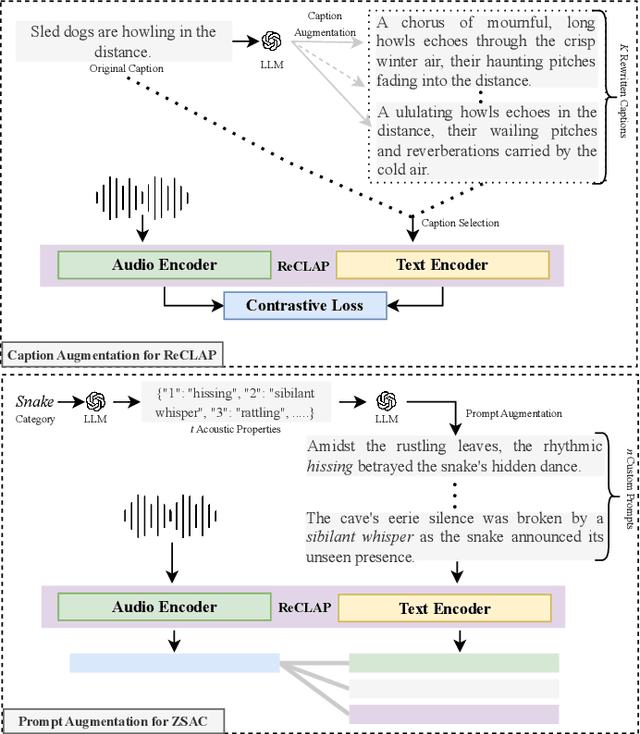

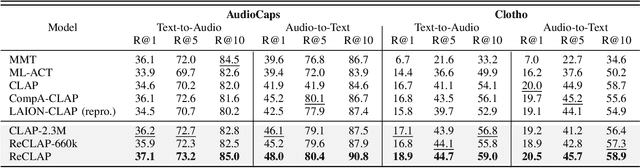
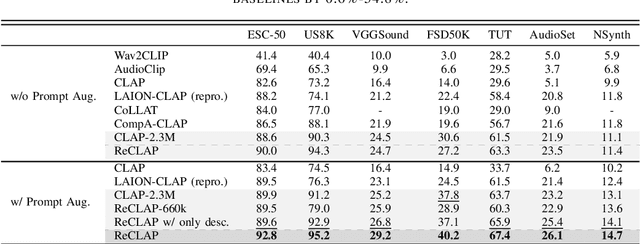
Open-vocabulary audio-language models, like CLAP, offer a promising approach for zero-shot audio classification (ZSAC) by enabling classification with any arbitrary set of categories specified with natural language prompts. In this paper, we propose a simple but effective method to improve ZSAC with CLAP. Specifically, we shift from the conventional method of using prompts with abstract category labels (e.g., Sound of an organ) to prompts that describe sounds using their inherent descriptive features in a diverse context (e.g.,The organ's deep and resonant tones filled the cathedral.). To achieve this, we first propose ReCLAP, a CLAP model trained with rewritten audio captions for improved understanding of sounds in the wild. These rewritten captions describe each sound event in the original caption using their unique discriminative characteristics. ReCLAP outperforms all baselines on both multi-modal audio-text retrieval and ZSAC. Next, to improve zero-shot audio classification with ReCLAP, we propose prompt augmentation. In contrast to the traditional method of employing hand-written template prompts, we generate custom prompts for each unique label in the dataset. These custom prompts first describe the sound event in the label and then employ them in diverse scenes. Our proposed method improves ReCLAP's performance on ZSAC by 1%-18% and outperforms all baselines by 1% - 55%.