 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugment, Drop & Swap: Improving Diversity in LLM Captions for Efficient Music-Text Representation Learning
Paper and Code
Sep 17, 2024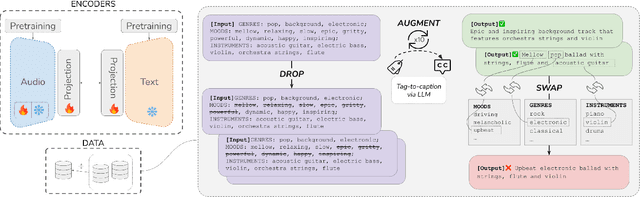
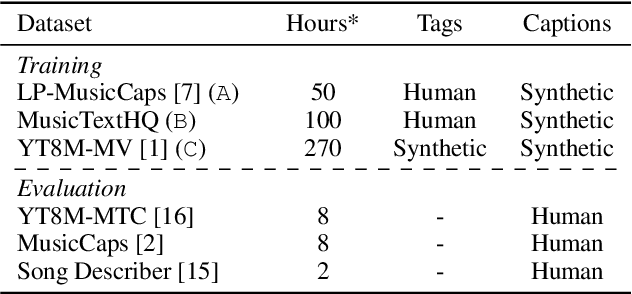
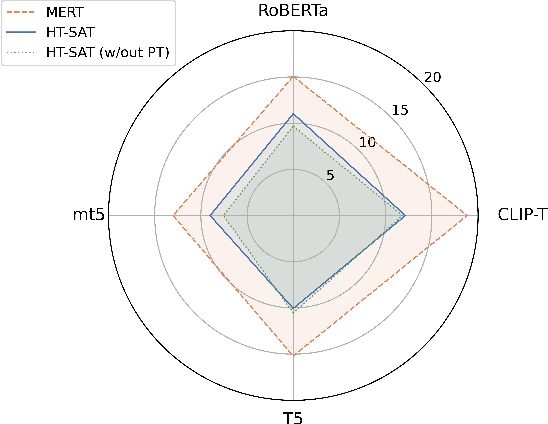

Audio-text contrastive models have become a powerful approach in music representation learning. Despite their empirical success, however, little is known about the influence of key design choices on the quality of music-text representations learnt through this framework. In this work, we expose these design choices within the constraints of limited data and computation budgets, and establish a more solid understanding of their impact grounded in empirical observations along three axes: the choice of base encoders, the level of curation in training data, and the use of text augmentation. We find that data curation is the single most important factor for music-text contrastive training in resource-constrained scenarios. Motivated by this insight, we introduce two novel techniques, Augmented View Dropout and TextSwap, which increase the diversity and descriptiveness of text inputs seen in training. Through our experiments we demonstrate that these are effective at boosting performance across different pre-training regimes, model architectures, and downstream data distributions, without incurring higher computational costs or requiring additional training data.