 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Generation of High Fidelity RGB-D Images by Deep-Learning with Adaptive Convolution
Paper and Code

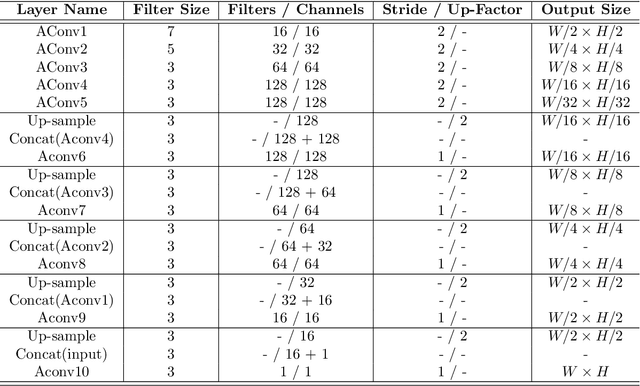
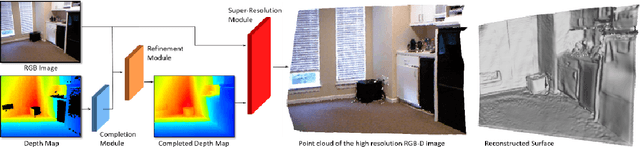
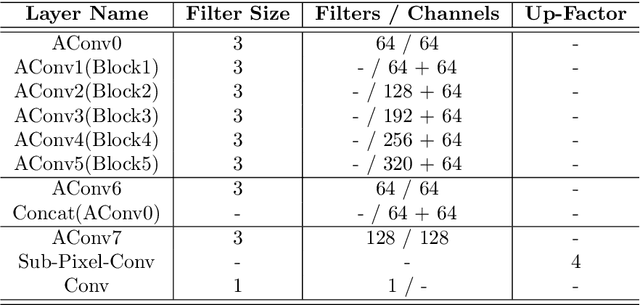
Using the raw data from consumer-level RGB-D cameras as input, we propose a deep-learning based approach to efficiently generate RGB-D images with completed information in high resolution. To process the input images in low resolution with missing regions, new operators for adaptive convolution are introduced in our deep-learning network that consists of three cascaded modules -- the completion module, the refinement module and the super-resolution module. The completion module is based on an architecture of encoder-decoder, where the features of input raw RGB-D will be automatically extracted by the encoding layers of a deep neural-network. The decoding layers are applied to reconstruct the completed depth map, which is followed by a refinement module to sharpen the boundary of different regions. For the super-resolution module, we generate RGB-D images in high resolution by multiple layers for feature extraction and a layer for up-sampling. Benefited from the adaptive convolution operators newly proposed in this paper, our results outperform the existing deep-learning based approaches for RGB-D image complete and super-resolution. As an end-to-end approach, high fidelity RGB-D images can be generated efficiently at the rate of around 21 frames per second.