 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence Over Plans: Online Trajectory Verification for Skill Distillation
May 09, 2026Agent skills can remarkably improve task success rates by using human-written procedural documents, but their quality is difficult to assess without environment-grounded verification. Existing skill generation methods heavily rely on preference logs rather than direct environment interaction, often yielding negligible or even degraded gains. We identify that it is a fundamental timing bottleneck: robust skills should be posterior-based, distilled from empirical environment interaction rather than prior plans. In this study, we introduce the Posterior Distillation Index (PDI), a trajectory-level metric that quantifies how well a distilled skill is grounded in the task-environment evidence. To operationalize PDI, we present SPARK (Structured Pipelines for Autonomous Runnable tasKs and sKill generation) for preserving task execution evidence towards full trajectory-level analysis. SPARK generates environment-verified trajectories used to compute PDI, and it applies PDI as an online diagnostic and intervention signal to ensure posterior skill formation. Across 86 runnable tasks, SPARK-generated skills consistently surpass no-skill baselines and outperform human-written skills on student models (inference cost up to 1,000x cheaper than teacher models). These findings show that PDI-guided distillation produces efficient and transferable skills grounded in the task-environment interaction. We release our code at https://github.com/EtaYang10th/spark-skills .
Can Cross-Layer Transcoders Replace Vision Transformer Activations? An Interpretable Perspective on Vision
Apr 14, 2026Understanding the internal activations of Vision Transformers (ViTs) is critical for building interpretable and trustworthy models. While Sparse Autoencoders (SAEs) have been used to extract human-interpretable features, they operate on individual layers and fail to capture the cross-layer computational structure of Transformers, as well as the relative significance of each layer in forming the last-layer representation. Alternatively, we introduce the adoption of Cross-Layer Transcoders (CLTs) as reliable, sparse, and depth-aware proxy models for MLP blocks in ViTs. CLTs use an encoder-decoder scheme to reconstruct each post-MLP activation from learned sparse embeddings of preceding layers, yielding a linear decomposition that transforms the final representation of ViTs from an opaque embedding into an additive, layer-resolved construction that enables faithful attribution and process-level interpretability. We train CLTs on CLIP ViT-B/32 and ViT-B/16 across CIFAR-100, COCO, and ImageNet-100. We show that CLTs achieve high reconstruction fidelity with post-MLP activations while preserving and even improving, in some cases, CLIP zero-shot classification accuracy. In terms of interpretability, we show that the cross-layer contribution scores provide faithful attribution, revealing that the final representation is concentrated in a smaller set of dominant layer-wise terms whose removal degrades performance and whose retention largely preserves it. These results showcase the significance of adopting CLTs as an alternative interpretable proxy of ViTs in the vision domain.
LUCID-SAE: Learning Unified Vision-Language Sparse Codes for Interpretable Concept Discovery
Feb 07, 2026Sparse autoencoders (SAEs) offer a natural path toward comparable explanations across different representation spaces. However, current SAEs are trained per modality, producing dictionaries whose features are not directly understandable and whose explanations do not transfer across domains. In this study, we introduce LUCID (Learning Unified vision-language sparse Codes for Interpretable concept Discovery), a unified vision-language sparse autoencoder that learns a shared latent dictionary for image patch and text token representations, while reserving private capacity for modality-specific details. We achieve feature alignment by coupling the shared codes with a learned optimal transport matching objective without the need of labeling. LUCID yields interpretable shared features that support patch-level grounding, establish cross-modal neuron correspondence, and enhance robustness against the concept clustering problem in similarity-based evaluation. Leveraging the alignment properties, we develop an automated dictionary interpretation pipeline based on term clustering without manual observations. Our analysis reveals that LUCID's shared features capture diverse semantic categories beyond objects, including actions, attributes, and abstract concepts, demonstrating a comprehensive approach to interpretable multimodal representations.
Anatomy-VLM: A Fine-grained Vision-Language Model for Medical Interpretation
Nov 11, 2025Accurate disease interpretation from radiology remains challenging due to imaging heterogeneity. Achieving expert-level diagnostic decisions requires integration of subtle image features with clinical knowledge. Yet major vision-language models (VLMs) treat images as holistic entities and overlook fine-grained image details that are vital for disease diagnosis. Clinicians analyze images by utilizing their prior medical knowledge and identify anatomical structures as important region of interests (ROIs). Inspired from this human-centric workflow, we introduce Anatomy-VLM, a fine-grained, vision-language model that incorporates multi-scale information. First, we design a model encoder to localize key anatomical features from entire medical images. Second, these regions are enriched with structured knowledge for contextually-aware interpretation. Finally, the model encoder aligns multi-scale medical information to generate clinically-interpretable disease prediction. Anatomy-VLM achieves outstanding performance on both in- and out-of-distribution datasets. We also validate the performance of Anatomy-VLM on downstream image segmentation tasks, suggesting that its fine-grained alignment captures anatomical and pathology-related knowledge. Furthermore, the Anatomy-VLM's encoder facilitates zero-shot anatomy-wise interpretation, providing its strong expert-level clinical interpretation capabilities.
RadAlign: Advancing Radiology Report Generation with Vision-Language Concept Alignment
Jan 13, 2025Automated chest radiographs interpretation requires both accurate disease classification and detailed radiology report generation, presenting a significant challenge in the clinical workflow. Current approaches either focus on classification accuracy at the expense of interpretability or generate detailed but potentially unreliable reports through image captioning techniques. In this study, we present RadAlign, a novel framework that combines the predictive accuracy of vision-language models (VLMs) with the reasoning capabilities of large language models (LLMs). Inspired by the radiologist's workflow, RadAlign first employs a specialized VLM to align visual features with key medical concepts, achieving superior disease classification with an average AUC of 0.885 across multiple diseases. These recognized medical conditions, represented as text-based concepts in the aligned visual-language space, are then used to prompt LLM-based report generation. Enhanced by a retrieval-augmented generation mechanism that grounds outputs in similar historical cases, RadAlign delivers superior report quality with a GREEN score of 0.678, outperforming state-of-the-art methods' 0.634. Our framework maintains strong clinical interpretability while reducing hallucinations, advancing automated medical imaging and report analysis through integrated predictive and generative AI. Code is available at https://github.com/difeigu/RadAlign.
Aligning Human Knowledge with Visual Concepts Towards Explainable Medical Image Classification
Jun 08, 2024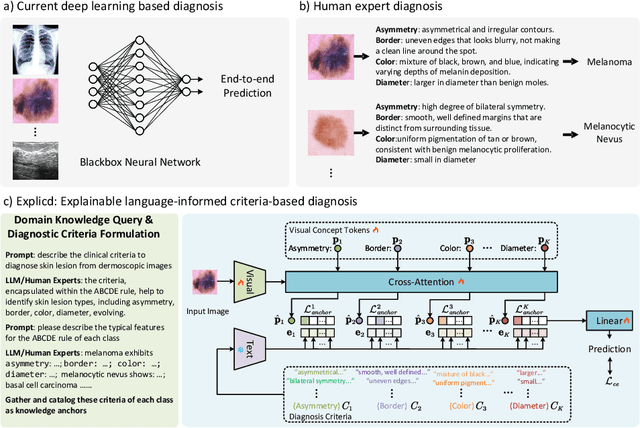
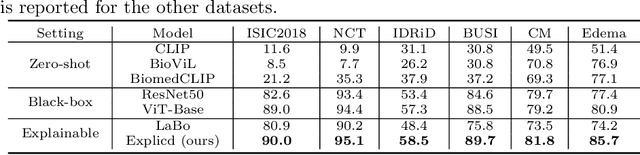
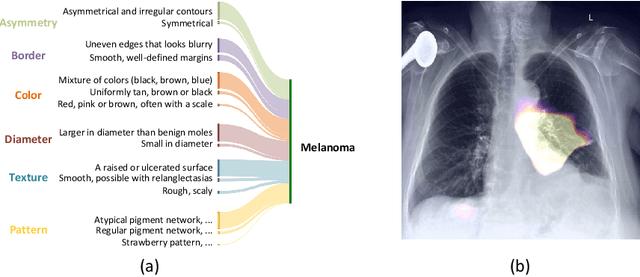
Although explainability is essential in the clinical diagnosis, most deep learning models still function as black boxes without elucidating their decision-making process. In this study, we investigate the explainable model development that can mimic the decision-making process of human experts by fusing the domain knowledge of explicit diagnostic criteria. We introduce a simple yet effective framework, Explicd, towards Explainable language-informed criteria-based diagnosis. Explicd initiates its process by querying domain knowledge from either large language models (LLMs) or human experts to establish diagnostic criteria across various concept axes (e.g., color, shape, texture, or specific patterns of diseases). By leveraging a pretrained vision-language model, Explicd injects these criteria into the embedding space as knowledge anchors, thereby facilitating the learning of corresponding visual concepts within medical images. The final diagnostic outcome is determined based on the similarity scores between the encoded visual concepts and the textual criteria embeddings. Through extensive evaluation of five medical image classification benchmarks, Explicd has demonstrated its inherent explainability and extends to improve classification performance compared to traditional black-box models.