 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Learning-based Model for Cardiac Image Reconstruction: Summary of the CMRxRecon2024 Challenge
Mar 05, 2025Cardiovascular magnetic resonance (CMR) offers diverse imaging contrasts for assessment of cardiac function and tissue characterization. However, acquiring each single CMR modality is often time-consuming, and comprehensive clinical protocols require multiple modalities with various sampling patterns, further extending the overall acquisition time and increasing susceptibility to motion artifacts. Existing deep learning-based reconstruction methods are often designed for specific acquisition parameters, which limits their ability to generalize across a variety of scan scenarios. As part of the CMRxRecon Series, the CMRxRecon2024 challenge provides diverse datasets encompassing multi-modality multi-view imaging with various sampling patterns, and a platform for the international community to develop and benchmark reconstruction solutions in two well-crafted tasks. Task 1 is a modality-universal setting, evaluating the out-of-distribution generalization of the reconstructed model, while Task 2 follows sampling-universal setting assessing the one-for-all adaptability of the universal model. Main contributions include providing the first and largest publicly available multi-modality, multi-view cardiac k-space dataset; developing a benchmarking platform that simulates clinical acceleration protocols, with a shared code library and tutorial for various k-t undersampling patterns and data processing; giving technical insights of enhanced data consistency based on physic-informed networks and adaptive prompt-learning embedding to be versatile to different clinical settings; additional finding on evaluation metrics to address the limitations of conventional ground-truth references in universal reconstruction tasks.
VerSe: Integrating Multiple Queries as Prompts for Versatile Cardiac MRI Segmentation
Dec 20, 2024Despite the advances in learning-based image segmentation approach, the accurate segmentation of cardiac structures from magnetic resonance imaging (MRI) remains a critical challenge. While existing automatic segmentation methods have shown promise, they still require extensive manual corrections of the segmentation results by human experts, particularly in complex regions such as the basal and apical parts of the heart. Recent efforts have been made on developing interactive image segmentation methods that enable human-in-the-loop learning. However, they are semi-automatic and inefficient, due to their reliance on click-based prompts, especially for 3D cardiac MRI volumes. To address these limitations, we propose VerSe, a Versatile Segmentation framework to unify automatic and interactive segmentation through mutiple queries. Our key innovation lies in the joint learning of object and click queries as prompts for a shared segmentation backbone. VerSe supports both fully automatic segmentation, through object queries, and interactive mask refinement, by providing click queries when needed. With the proposed integrated prompting scheme, VerSe demonstrates significant improvement in performance and efficiency over existing methods, on both cardiac MRI and out-of-distribution medical imaging datasets. The code is available at https://github.com/bangwayne/Verse.
Learning Volumetric Neural Deformable Models to Recover 3D Regional Heart Wall Motion from Multi-Planar Tagged MRI
Nov 21, 2024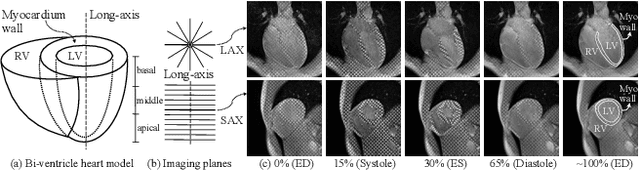
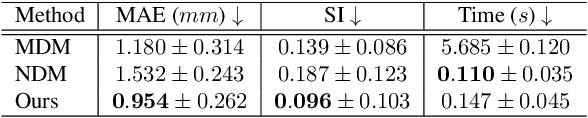
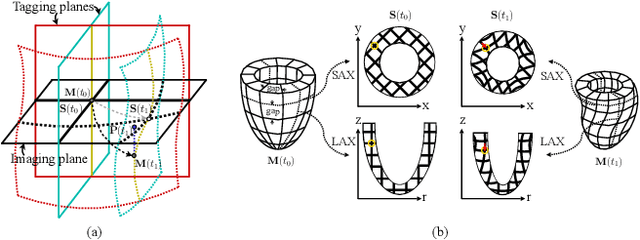
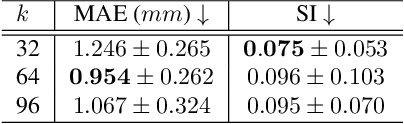
Multi-planar tagged MRI is the gold standard for regional heart wall motion evaluation. However, accurate recovery of the 3D true heart wall motion from a set of 2D apparent motion cues is challenging, due to incomplete sampling of the true motion and difficulty in information fusion from apparent motion cues observed on multiple imaging planes. To solve these challenges, we introduce a novel class of volumetric neural deformable models ($\upsilon$NDMs). Our $\upsilon$NDMs represent heart wall geometry and motion through a set of low-dimensional global deformation parameter functions and a diffeomorphic point flow regularized local deformation field. To learn such global and local deformation for 2D apparent motion mapping to 3D true motion, we design a hybrid point transformer, which incorporates both point cross-attention and self-attention mechanisms. While use of point cross-attention can learn to fuse 2D apparent motion cues into material point true motion hints, point self-attention hierarchically organised as an encoder-decoder structure can further learn to refine these hints and map them into 3D true motion. We have performed experiments on a large cohort of synthetic 3D regional heart wall motion dataset. The results demonstrated the high accuracy of our method for the recovery of dense 3D true motion from sparse 2D apparent motion cues. Project page is at https://github.com/DeepTag/VolumetricNeuralDeformableModels.
Continuous Spatio-Temporal Memory Networks for 4D Cardiac Cine MRI Segmentation
Oct 30, 2024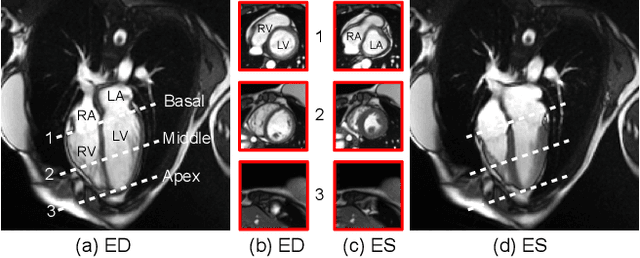
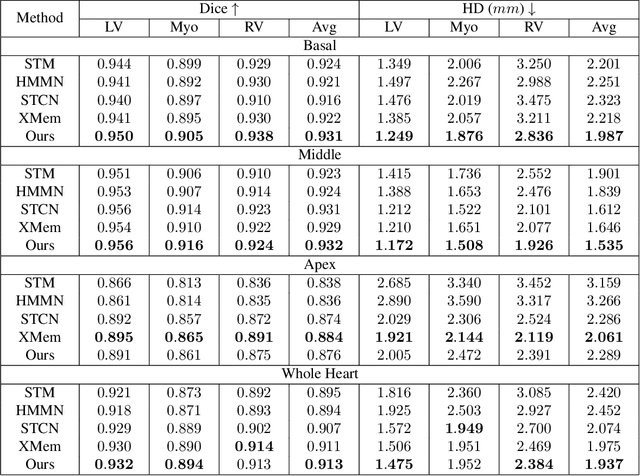
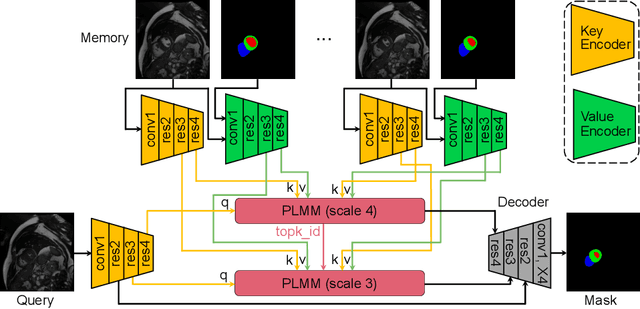
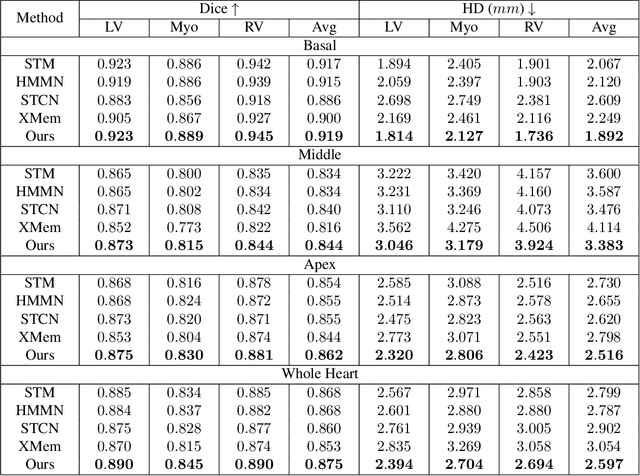
Current cardiac cine magnetic resonance image (cMR) studies focus on the end diastole (ED) and end systole (ES) phases, while ignoring the abundant temporal information in the whole image sequence. This is because whole sequence segmentation is currently a tedious process and inaccurate. Conventional whole sequence segmentation approaches first estimate the motion field between frames, which is then used to propagate the mask along the temporal axis. However, the mask propagation results could be prone to error, especially for the basal and apex slices, where through-plane motion leads to significant morphology and structural change during the cardiac cycle. Inspired by recent advances in video object segmentation (VOS), based on spatio-temporal memory (STM) networks, we propose a continuous STM (CSTM) network for semi-supervised whole heart and whole sequence cMR segmentation. Our CSTM network takes full advantage of the spatial, scale, temporal and through-plane continuity prior of the underlying heart anatomy structures, to achieve accurate and fast 4D segmentation. Results of extensive experiments across multiple cMR datasets show that our method can improve the 4D cMR segmentation performance, especially for the hard-to-segment regions.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024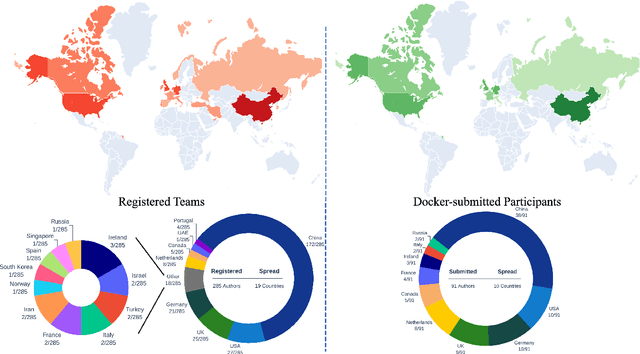
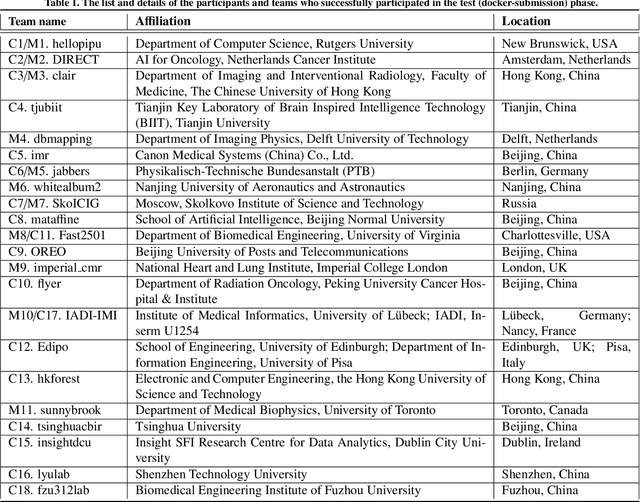
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
Fill the K-Space and Refine the Image: Prompting for Dynamic and Multi-Contrast MRI Reconstruction
Sep 25, 2023



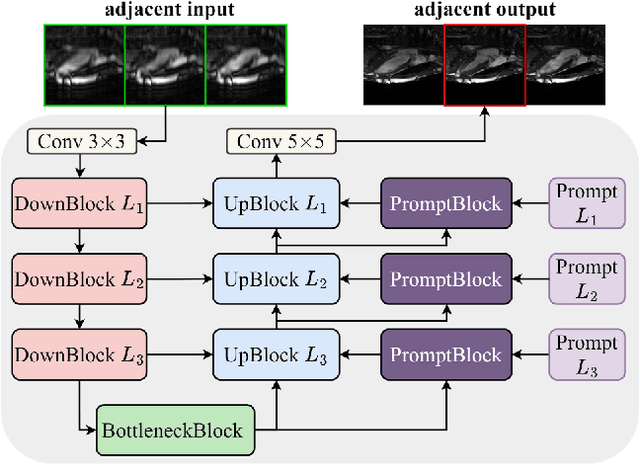
The key to dynamic or multi-contrast magnetic resonance imaging (MRI) reconstruction lies in exploring inter-frame or inter-contrast information. Currently, the unrolled model, an approach combining iterative MRI reconstruction steps with learnable neural network layers, stands as the best-performing method for MRI reconstruction. However, there are two main limitations to overcome: firstly, the unrolled model structure and GPU memory constraints restrict the capacity of each denoising block in the network, impeding the effective extraction of detailed features for reconstruction; secondly, the existing model lacks the flexibility to adapt to variations in the input, such as different contrasts, resolutions or views, necessitating the training of separate models for each input type, which is inefficient and may lead to insufficient reconstruction. In this paper, we propose a two-stage MRI reconstruction pipeline to address these limitations. The first stage involves filling the missing k-space data, which we approach as a physics-based reconstruction problem. We first propose a simple yet efficient baseline model, which utilizes adjacent frames/contrasts and channel attention to capture the inherent inter-frame/-contrast correlation. Then, we extend the baseline model to a prompt-based learning approach, PromptMR, for all-in-one MRI reconstruction from different views, contrasts, adjacent types, and acceleration factors. The second stage is to refine the reconstruction from the first stage, which we treat as a general video restoration problem to further fuse features from neighboring frames/contrasts in the image domain. Extensive experiments show that our proposed method significantly outperforms previous state-of-the-art accelerated MRI reconstruction methods.
Learned Half-Quadratic Splitting Network for Magnetic Resonance Image Reconstruction
Dec 21, 2021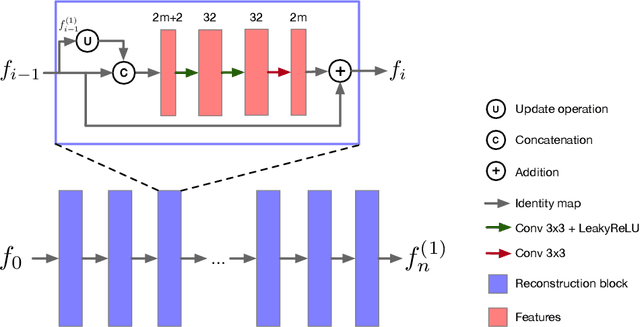
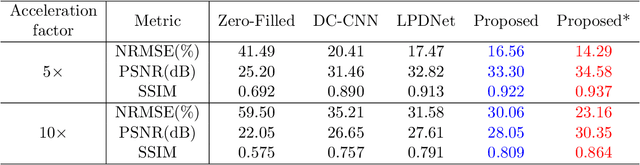
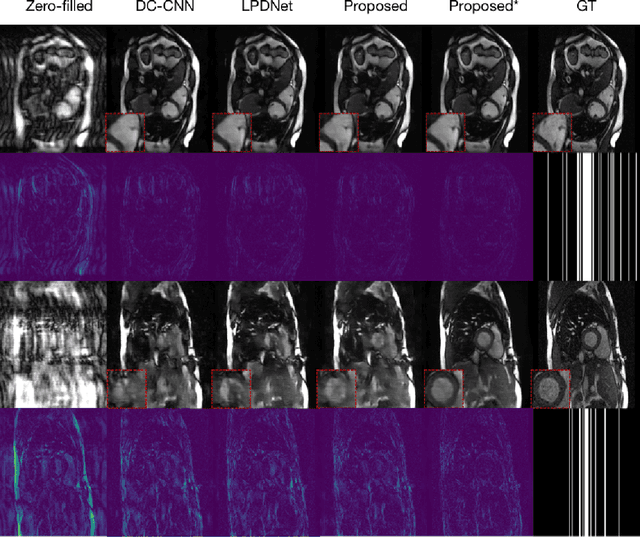

Magnetic Resonance (MR) image reconstruction from highly undersampled $k$-space data is critical in accelerated MR imaging (MRI) techniques. In recent years, deep learning-based methods have shown great potential in this task. This paper proposes a learned half-quadratic splitting algorithm for MR image reconstruction and implements the algorithm in an unrolled deep learning network architecture. We compare the performance of our proposed method on a public cardiac MR dataset against DC-CNN and LPDNet, and our method outperforms other methods in both quantitative results and qualitative results with fewer model parameters and faster reconstruction speed. Finally, we enlarge our model to achieve superior reconstruction quality, and the improvement is $1.76$ dB and $2.74$ dB over LPDNet in peak signal-to-noise ratio on $5\times$ and $10\times$ acceleration, respectively. Code for our method is publicly available at https://github.com/hellopipu/HQS-Net.
Multi-Modality Generative Adversarial Networks with Tumor Consistency Loss for Brain MR Image Synthesis
May 02, 2020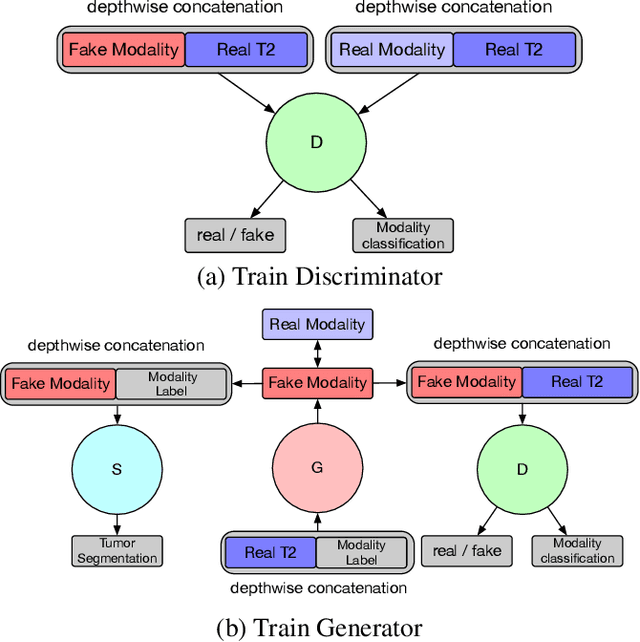
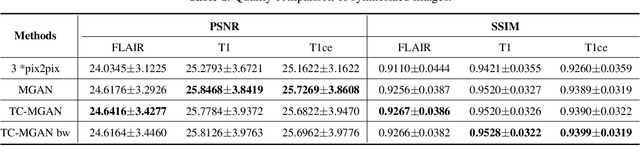
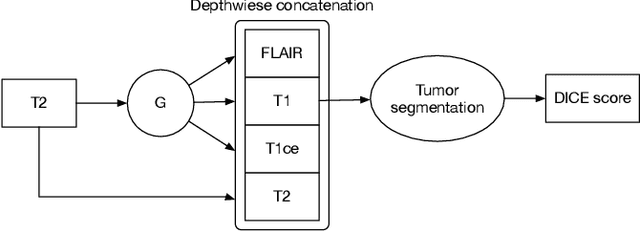
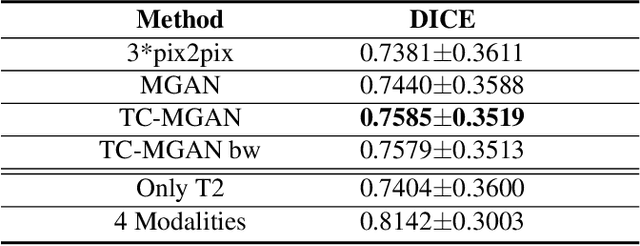
Magnetic Resonance (MR) images of different modalities can provide complementary information for clinical diagnosis, but whole modalities are often costly to access. Most existing methods only focus on synthesizing missing images between two modalities, which limits their robustness and efficiency when multiple modalities are missing. To address this problem, we propose a multi-modality generative adversarial network (MGAN) to synthesize three high-quality MR modalities (FLAIR, T1 and T1ce) from one MR modality T2 simultaneously. The experimental results show that the quality of the synthesized images by our proposed methods is better than the one synthesized by the baseline model, pix2pix. Besides, for MR brain image synthesis, it is important to preserve the critical tumor information in the generated modalities, so we further introduce a multi-modality tumor consistency loss to MGAN, called TC-MGAN. We use the synthesized modalities by TC-MGAN to boost the tumor segmentation accuracy, and the results demonstrate its effectiveness.