 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Saving Adversarial Training: Reinforcing Multi-Perturbation Robustness via Hypernetworks
Sep 28, 2023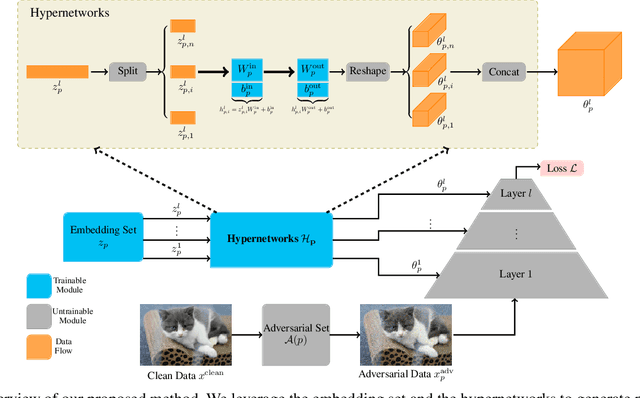


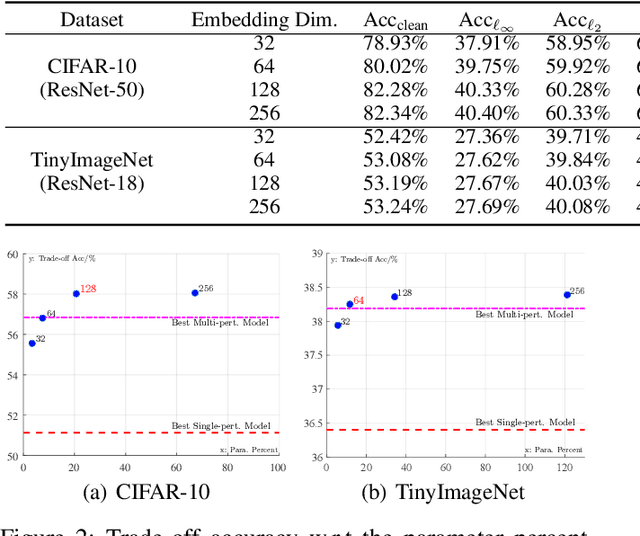
Adversarial training serves as one of the most popular and effective methods to defend against adversarial perturbations. However, most defense mechanisms only consider a single type of perturbation while various attack methods might be adopted to perform stronger adversarial attacks against the deployed model in real-world scenarios, e.g., $\ell_2$ or $\ell_\infty$. Defending against various attacks can be a challenging problem since multi-perturbation adversarial training and its variants only achieve suboptimal robustness trade-offs, due to the theoretical limit to multi-perturbation robustness for a single model. Besides, it is impractical to deploy large models in some storage-efficient scenarios. To settle down these drawbacks, in this paper we propose a novel multi-perturbation adversarial training framework, parameter-saving adversarial training (PSAT), to reinforce multi-perturbation robustness with an advantageous side effect of saving parameters, which leverages hypernetworks to train specialized models against a single perturbation and aggregate these specialized models to defend against multiple perturbations. Eventually, we extensively evaluate and compare our proposed method with state-of-the-art single/multi-perturbation robust methods against various latest attack methods on different datasets, showing the robustness superiority and parameter efficiency of our proposed method, e.g., for the CIFAR-10 dataset with ResNet-50 as the backbone, PSAT saves approximately 80\% of parameters with achieving the state-of-the-art robustness trade-off accuracy.
Reducing Adversarial Training Cost with Gradient Approximation
Sep 18, 2023



Deep learning models have achieved state-of-the-art performances in various domains, while they are vulnerable to the inputs with well-crafted but small perturbations, which are named after adversarial examples (AEs). Among many strategies to improve the model robustness against AEs, Projected Gradient Descent (PGD) based adversarial training is one of the most effective methods. Unfortunately, the prohibitive computational overhead of generating strong enough AEs, due to the maximization of the loss function, sometimes makes the regular PGD adversarial training impractical when using larger and more complicated models. In this paper, we propose that the adversarial loss can be approximated by the partial sum of Taylor series. Furthermore, we approximate the gradient of adversarial loss and propose a new and efficient adversarial training method, adversarial training with gradient approximation (GAAT), to reduce the cost of building up robust models. Additionally, extensive experiments demonstrate that this efficiency improvement can be achieved without any or with very little loss in accuracy on natural and adversarial examples, which show that our proposed method saves up to 60\% of the training time with comparable model test accuracy on MNIST, CIFAR-10 and CIFAR-100 datasets.
Stealthy Physical Masked Face Recognition Attack via Adversarial Style Optimization
Sep 18, 2023



Deep neural networks (DNNs) have achieved state-of-the-art performance on face recognition (FR) tasks in the last decade. In real scenarios, the deployment of DNNs requires taking various face accessories into consideration, like glasses, hats, and masks. In the COVID-19 pandemic era, wearing face masks is one of the most effective ways to defend against the novel coronavirus. However, DNNs are known to be vulnerable to adversarial examples with a small but elaborated perturbation. Thus, a facial mask with adversarial perturbations may pose a great threat to the widely used deep learning-based FR models. In this paper, we consider a challenging adversarial setting: targeted attack against FR models. We propose a new stealthy physical masked FR attack via adversarial style optimization. Specifically, we train an adversarial style mask generator that hides adversarial perturbations inside style masks. Moreover, to ameliorate the phenomenon of sub-optimization with one fixed style, we propose to discover the optimal style given a target through style optimization in a continuous relaxation manner. We simultaneously optimize the generator and the style selection for generating strong and stealthy adversarial style masks. We evaluated the effectiveness and transferability of our proposed method via extensive white-box and black-box digital experiments. Furthermore, we also conducted physical attack experiments against local FR models and online platforms.