 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Reduction based Experience Replay for Policy Optimization
Aug 25, 2022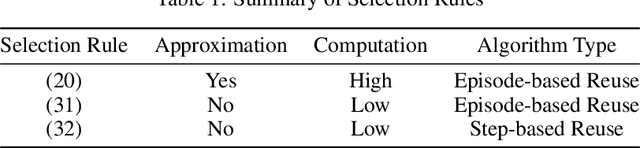
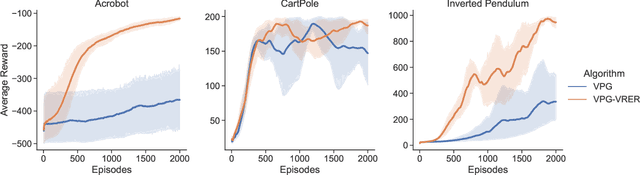
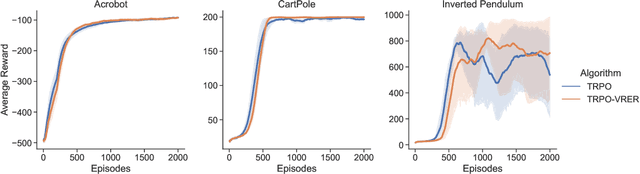
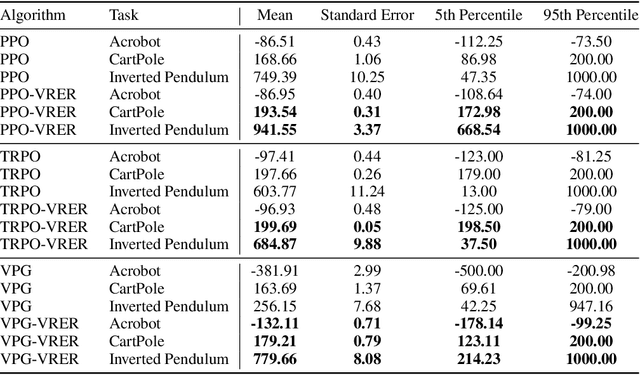
For reinforcement learning on complex stochastic systems where many factors dynamically impact the output trajectories, it is desirable to effectively leverage the information from historical samples collected in previous iterations to accelerate policy optimization. Classical experience replay allows agents to remember by reusing historical observations. However, the uniform reuse strategy that treats all observations equally overlooks the relative importance of different samples. To overcome this limitation, we propose a general variance reduction based experience replay (VRER) framework that can selectively reuse the most relevant samples to improve policy gradient estimation. This selective mechanism can adaptively put more weight on past samples that are more likely to be generated by the current target distribution. Our theoretical and empirical studies show that the proposed VRER can accelerate the learning of optimal policy and enhance the performance of state-of-the-art policy optimization approaches.
Green Simulation Assisted Policy Gradient to Accelerate Stochastic Process Control
Oct 17, 2021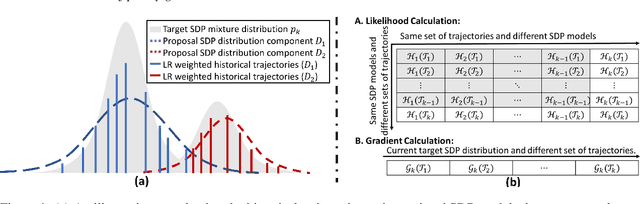

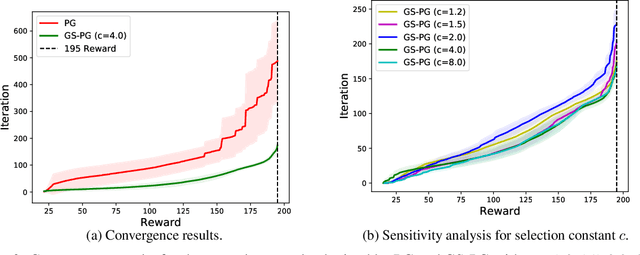
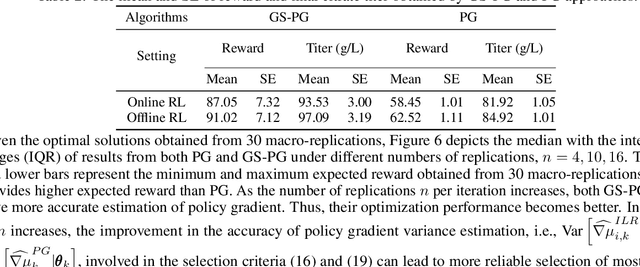
This study is motivated by the critical challenges in the biopharmaceutical manufacturing, including high complexity, high uncertainty, and very limited process data. Each experiment run is often very expensive. To support the optimal and robust process control, we propose a general green simulation assisted policy gradient (GS-PG) framework for both online and offline learning settings. Basically, to address the key limitations of state-of-art reinforcement learning (RL), such as sample inefficiency and low reliability, we create a mixture likelihood ratio based policy gradient estimation that can leverage on the information from historical experiments conducted under different inputs, including process model coefficients and decision policy parameters. Then, to accelerate the learning of optimal and robust policy, we further propose a variance reduction based sample selection method that allows GS-PG to intelligently select and reuse most relevant historical trajectories. The selection rule automatically updates the samples to be reused during the learning of process mechanisms and the search for optimal policy. Our theoretical and empirical studies demonstrate that the proposed framework can perform better than the state-of-art policy gradient approach and accelerate the optimal robust process control for complex stochastic systems under high uncertainty.