 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Convolution for Semantic Segmentation
Jun 01, 2018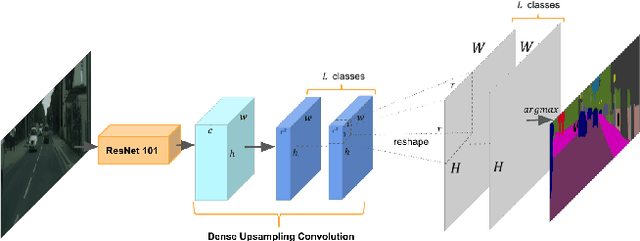
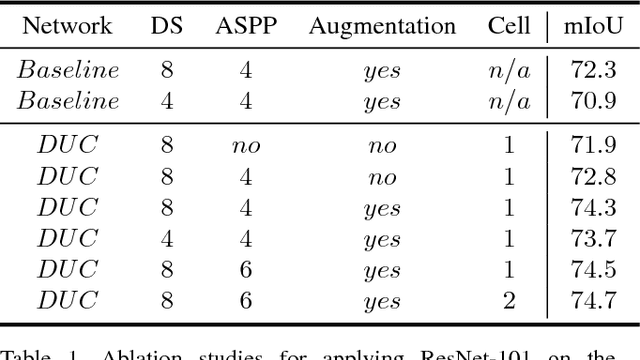
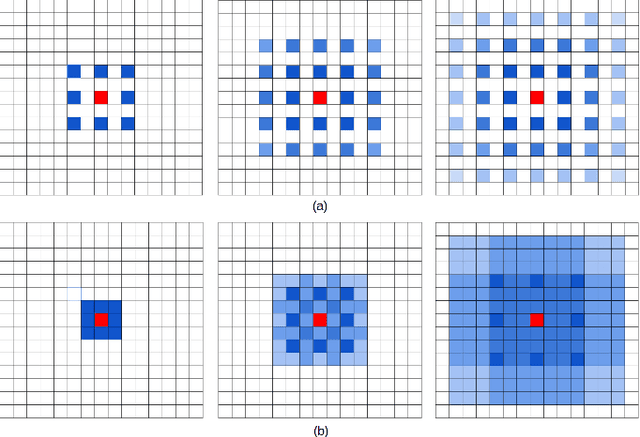
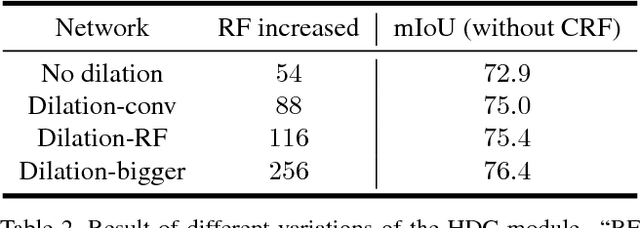
Recent advances in deep learning, especially deep convolutional neural networks (CNNs), have led to significant improvement over previous semantic segmentation systems. Here we show how to improve pixel-wise semantic segmentation by manipulating convolution-related operations that are of both theoretical and practical value. First, we design dense upsampling convolution (DUC) to generate pixel-level prediction, which is able to capture and decode more detailed information that is generally missing in bilinear upsampling. Second, we propose a hybrid dilated convolution (HDC) framework in the encoding phase. This framework 1) effectively enlarges the receptive fields (RF) of the network to aggregate global information; 2) alleviates what we call the "gridding issue" caused by the standard dilated convolution operation. We evaluate our approaches thoroughly on the Cityscapes dataset, and achieve a state-of-art result of 80.1% mIOU in the test set at the time of submission. We also have achieved state-of-the-art overall on the KITTI road estimation benchmark and the PASCAL VOC2012 segmentation task. Our source code can be found at https://github.com/TuSimple/TuSimple-DUC .
Factorized Bilinear Models for Image Recognition
Sep 04, 2017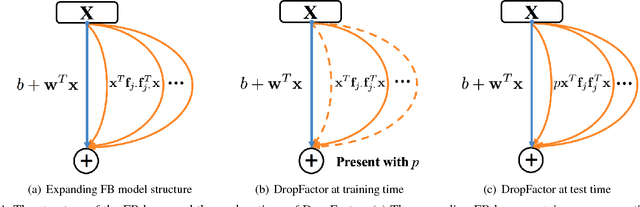

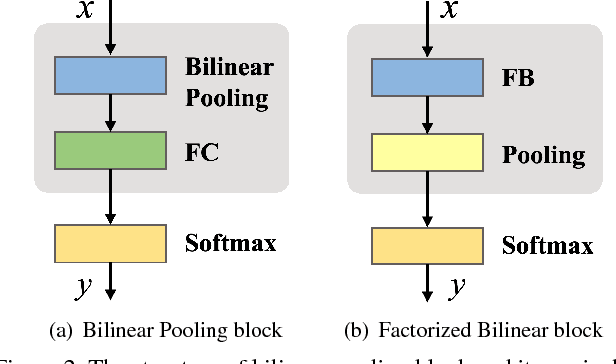
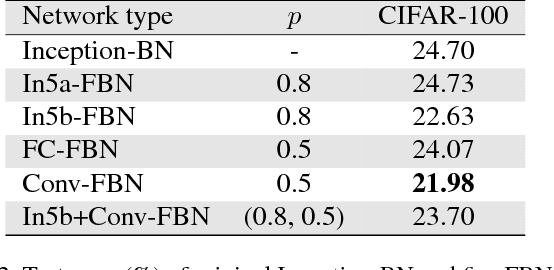
Although Deep Convolutional Neural Networks (CNNs) have liberated their power in various computer vision tasks, the most important components of CNN, convolutional layers and fully connected layers, are still limited to linear transformations. In this paper, we propose a novel Factorized Bilinear (FB) layer to model the pairwise feature interactions by considering the quadratic terms in the transformations. Compared with existing methods that tried to incorporate complex non-linearity structures into CNNs, the factorized parameterization makes our FB layer only require a linear increase of parameters and affordable computational cost. To further reduce the risk of overfitting of the FB layer, a specific remedy called DropFactor is devised during the training process. We also analyze the connection between FB layer and some existing models, and show FB layer is a generalization to them. Finally, we validate the effectiveness of FB layer on several widely adopted datasets including CIFAR-10, CIFAR-100 and ImageNet, and demonstrate superior results compared with various state-of-the-art deep models.
Demystifying Neural Style Transfer
Jul 01, 2017



Neural Style Transfer has recently demonstrated very exciting results which catches eyes in both academia and industry. Despite the amazing results, the principle of neural style transfer, especially why the Gram matrices could represent style remains unclear. In this paper, we propose a novel interpretation of neural style transfer by treating it as a domain adaptation problem. Specifically, we theoretically show that matching the Gram matrices of feature maps is equivalent to minimize the Maximum Mean Discrepancy (MMD) with the second order polynomial kernel. Thus, we argue that the essence of neural style transfer is to match the feature distributions between the style images and the generated images. To further support our standpoint, we experiment with several other distribution alignment methods, and achieve appealing results. We believe this novel interpretation connects these two important research fields, and could enlighten future researches.
Revisiting Batch Normalization For Practical Domain Adaptation
Nov 08, 2016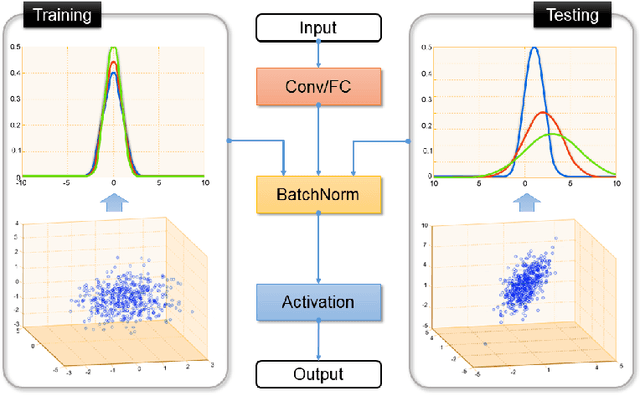


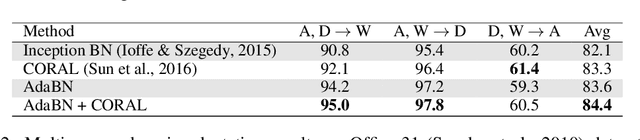
Deep neural networks (DNN) have shown unprecedented success in various computer vision applications such as image classification and object detection. However, it is still a common annoyance during the training phase, that one has to prepare at least thousands of labeled images to fine-tune a network to a specific domain. Recent study (Tommasi et al. 2015) shows that a DNN has strong dependency towards the training dataset, and the learned features cannot be easily transferred to a different but relevant task without fine-tuning. In this paper, we propose a simple yet powerful remedy, called Adaptive Batch Normalization (AdaBN) to increase the generalization ability of a DNN. By modulating the statistics in all Batch Normalization layers across the network, our approach achieves deep adaptation effect for domain adaptation tasks. In contrary to other deep learning domain adaptation methods, our method does not require additional components, and is parameter-free. It archives state-of-the-art performance despite its surprising simplicity. Furthermore, we demonstrate that our method is complementary with other existing methods. Combining AdaBN with existing domain adaptation treatments may further improve model performance.
The Secrets of Salient Object Segmentation
Jun 12, 2014
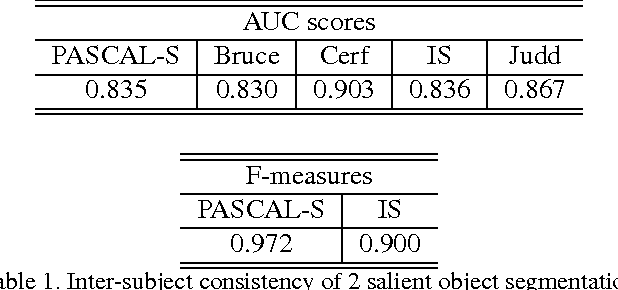
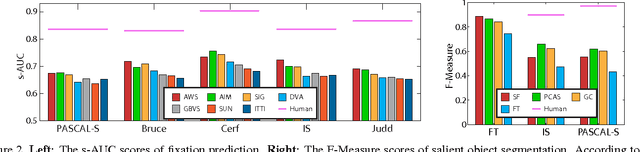
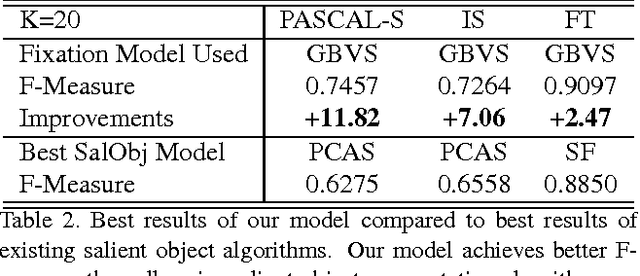
In this paper we provide an extensive evaluation of fixation prediction and salient object segmentation algorithms as well as statistics of major datasets. Our analysis identifies serious design flaws of existing salient object benchmarks, called the dataset design bias, by over emphasizing the stereotypical concepts of saliency. The dataset design bias does not only create the discomforting disconnection between fixations and salient object segmentation, but also misleads the algorithm designing. Based on our analysis, we propose a new high quality dataset that offers both fixation and salient object segmentation ground-truth. With fixations and salient object being presented simultaneously, we are able to bridge the gap between fixations and salient objects, and propose a novel method for salient object segmentation. Finally, we report significant benchmark progress on three existing datasets of segmenting salient objects
A Meta-Theory of Boundary Detection Benchmarks
Feb 25, 2013
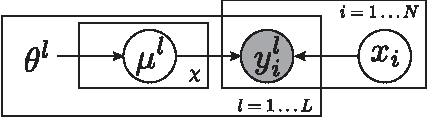

Human labeled datasets, along with their corresponding evaluation algorithms, play an important role in boundary detection. We here present a psychophysical experiment that addresses the reliability of such benchmarks. To find better remedies to evaluate the performance of any boundary detection algorithm, we propose a computational framework to remove inappropriate human labels and estimate the intrinsic properties of boundaries.