Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Meta-Theory of Boundary Detection Benchmarks
Paper and Code
Feb 25, 2013
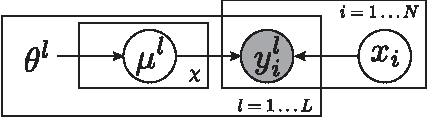

Human labeled datasets, along with their corresponding evaluation algorithms, play an important role in boundary detection. We here present a psychophysical experiment that addresses the reliability of such benchmarks. To find better remedies to evaluate the performance of any boundary detection algorithm, we propose a computational framework to remove inappropriate human labels and estimate the intrinsic properties of boundaries.
* NIPS 2012 Workshop on Human Computation for Science and Computational
Sustainability
View paper on