 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Planning for Air-Ground Robot Considering Modal Switching Point Optimization
May 14, 2023



An innovative sort of mobility platform that can both drive and fly is the air-ground robot. The need for an agile flight cannot be satisfied by traditional path planning techniques for air-ground robots. Prior studies had mostly focused on improving the energy efficiency of paths, seldom taking the seeking speed and optimizing take-off and landing places into account. A robot for the field application environment was proposed, and a lightweight global spatial planning technique for the robot based on the graph-search algorithm taking mode switching point optimization into account, with an emphasis on energy efficiency, searching speed, and the viability of real deployment. The fundamental concept is to lower the computational burden by employing an interchangeable search approach that combines planar and spatial search. Furthermore, to safeguard the health of the power battery and the integrity of the mission execution, a trap escape approach was also provided. Simulations are run to test the effectiveness of the suggested model based on the field DEM map. The simulation results show that our technology is capable of producing finished, plausible 3D paths with a high degree of believability. Additionally, the mode-switching point optimization method efficiently identifies additional acceptable places for mode switching, and the improved paths use less time and energy.
Monocular 3D Vehicle Detection Using Uncalibrated Traffic Cameras through Homography
Mar 29, 2021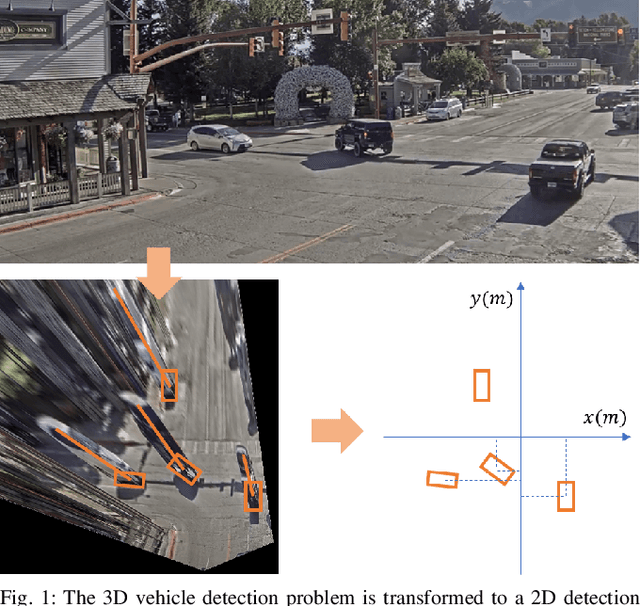
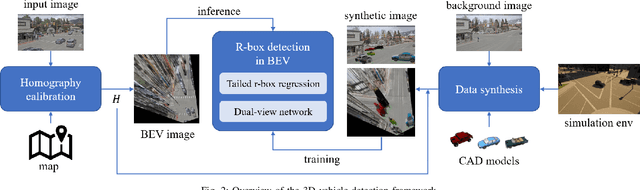

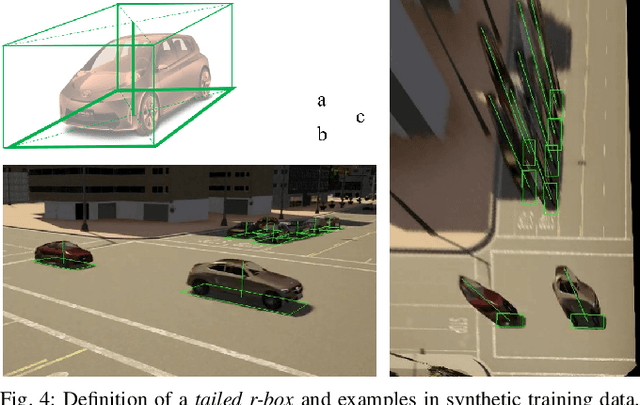
This paper proposes a method to extract the position and pose of vehicles in the 3D world from a single traffic camera. Most previous monocular 3D vehicle detection algorithms focused on cameras on vehicles from the perspective of a driver, and assumed known intrinsic and extrinsic calibration. On the contrary, this paper focuses on the same task using uncalibrated monocular traffic cameras. We observe that the homography between the road plane and the image plane is essential to 3D vehicle detection and the data synthesis for this task, and the homography can be estimated without the camera intrinsics and extrinsics. We conduct 3D vehicle detection by estimating the rotated bounding boxes (r-boxes) in the bird's eye view (BEV) images generated from inverse perspective mapping. We propose a new regression target called \textit{tailed~r-box} and a \textit{dual-view} network architecture which boosts the detection accuracy on warped BEV images. Experiments show that the proposed method can generalize to new camera and environment setups despite not seeing imaged from them during training.
SUPER: A Novel Lane Detection System
May 14, 2020

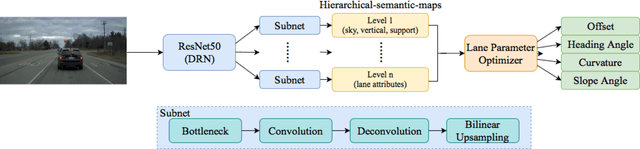
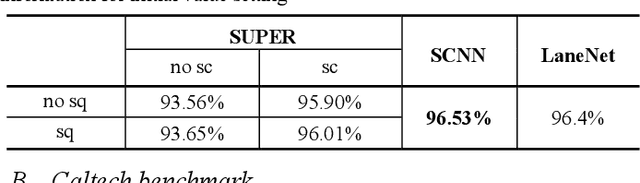
AI-based lane detection algorithms were actively studied over the last few years. Many have demonstrated superior performance compared with traditional feature-based methods. The accuracy, however, is still generally in the low 80% or high 90%, or even lower when challenging images are used. In this paper, we propose a real-time lane detection system, called Scene Understanding Physics-Enhanced Real-time (SUPER) algorithm. The proposed method consists of two main modules: 1) a hierarchical semantic segmentation network as the scene feature extractor and 2) a physics enhanced multi-lane parameter optimization module for lane inference. We train the proposed system using heterogeneous data from Cityscapes, Vistas and Apollo, and evaluate the performance on four completely separate datasets (that were never seen before), including Tusimple, Caltech, URBAN KITTI-ROAD, and X-3000. The proposed approach performs the same or better than lane detection models already trained on the same dataset and performs well even on datasets it was never trained on. Real-world vehicle tests were also conducted. Preliminary test results show promising real-time lane-detection performance compared with the Mobileye.
Monocular Depth Prediction Through Continuous 3D Loss
Mar 21, 2020



This paper reports a new continuous 3D loss function for learning depth from monocular images. The dense depth prediction from a monocular image is supervised using sparse LIDAR points, exploiting available data from camera-LIDAR sensor suites during training. Currently, accurate and affordable range sensor is not available. Stereo cameras and LIDARs measure depth either inaccurately or sparsely/costly. In contrast to the current point-to-point loss evaluation approach, the proposed 3D loss treats point clouds as continuous objects; and therefore, it overcomes the lack of dense ground truth depth due to the sparsity of LIDAR measurements. Experimental evaluations show that the proposed method achieves accurate depth measurement with consistent 3D geometric structures through a monocular camera.
Mcity Data Collection for Automated Vehicles Study
Dec 12, 2019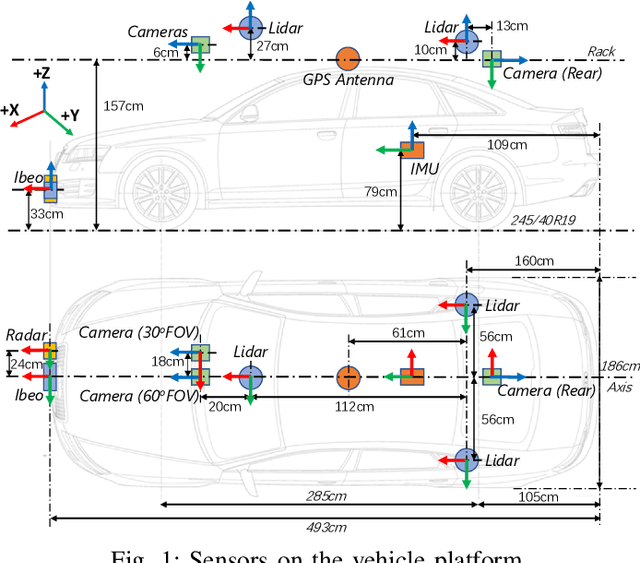
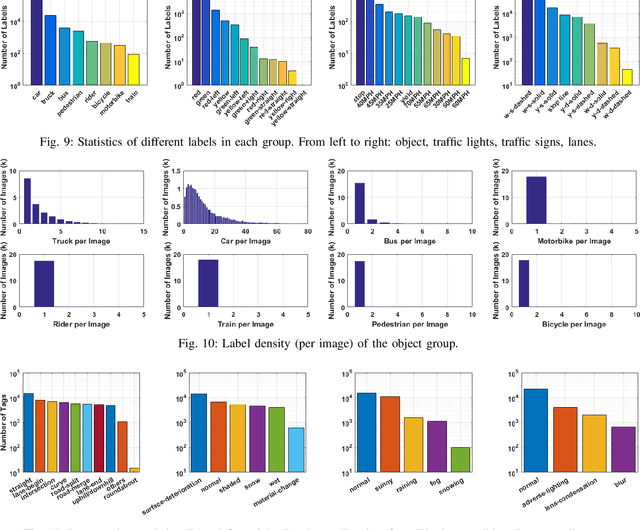
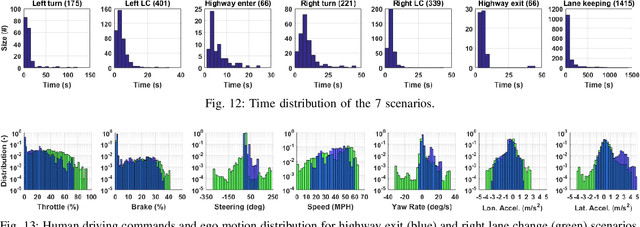
The main goal of this paper is to introduce the data collection effort at Mcity targeting automated vehicle development. We captured a comprehensive set of data from a set of perception sensors (Lidars, Radars, Cameras) as well as vehicle steering/brake/throttle inputs and an RTK unit. Two in-cabin cameras record the human driver's behaviors for possible future use. The naturalistic driving on selected open roads is recorded at different time of day and weather conditions. We also perform designed choreography data collection inside the Mcity test facility focusing on vehicle to vehicle, and vehicle to vulnerable road user interactions which is quite unique among existing open-source datasets. The vehicle platform, data content, tags/labels, and selected analysis results are shown in this paper.