 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-based Legged Robots Terrain Traversability Modeling via Deep Inverse Reinforcement Learning
Jul 07, 2022
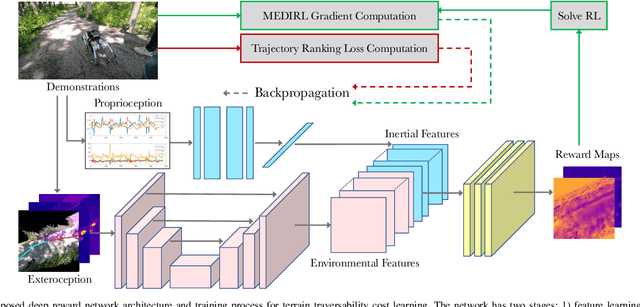

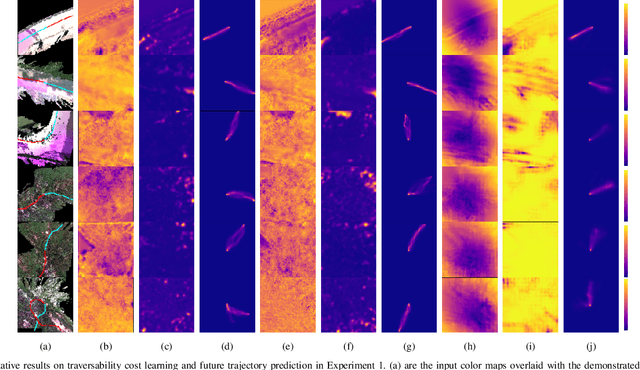
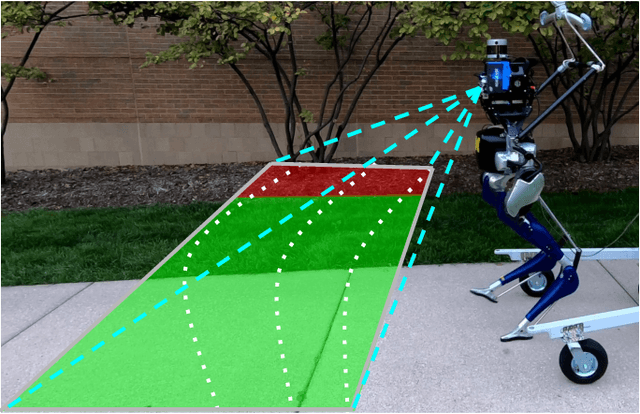
This work reports on developing a deep inverse reinforcement learning method for legged robots terrain traversability modeling that incorporates both exteroceptive and proprioceptive sensory data. Existing works use robot-agnostic exteroceptive environmental features or handcrafted kinematic features; instead, we propose to also learn robot-specific inertial features from proprioceptive sensory data for reward approximation in a single deep neural network. Incorporating the inertial features can improve the model fidelity and provide a reward that depends on the robot's state during deployment. We train the reward network using the Maximum Entropy Deep Inverse Reinforcement Learning (MEDIRL) algorithm and propose simultaneously minimizing a trajectory ranking loss to deal with the suboptimality of legged robot demonstrations. The demonstrated trajectories are ranked by locomotion energy consumption, in order to learn an energy-aware reward function and a more energy-efficient policy than demonstration. We evaluate our method using a dataset collected by an MIT Mini-Cheetah robot and a Mini-Cheetah simulator. The code is publicly available at https://github.com/ganlumomo/minicheetah-traversability-irl.
Multi-Task Learning for Scalable and Dense Multi-Layer Bayesian Map Inference
Jun 28, 2021


This paper presents a novel and flexible multi-task multi-layer Bayesian mapping framework with readily extendable attribute layers. The proposed framework goes beyond modern metric-semantic maps to provide even richer environmental information for robots in a single mapping formalism while exploiting existing inter-layer correlations. It removes the need for a robot to access and process information from many separate maps when performing a complex task and benefits from the correlation between map layers, advancing the way robots interact with their environments. To this end, we design a multi-task deep neural network with attention mechanisms as our front-end to provide multiple observations for multiple map layers simultaneously. Our back-end runs a scalable closed-form Bayesian inference with only logarithmic time complexity. We apply the framework to build a dense robotic map including metric-semantic occupancy and traversability layers. Traversability ground truth labels are automatically generated from exteroceptive sensory data in a self-supervised manner. We present extensive experimental results on publicly available data sets and data collected by a 3D bipedal robot platform on the University of Michigan North Campus and show reliable mapping performance in different environments. Finally, we also discuss how the current framework can be extended to incorporate more information such as friction, signal strength, temperature, and physical quantity concentration using Gaussian map layers. The software for reproducing the presented results or running on customized data is made publicly available.
Monocular Depth Prediction Through Continuous 3D Loss
Mar 21, 2020



This paper reports a new continuous 3D loss function for learning depth from monocular images. The dense depth prediction from a monocular image is supervised using sparse LIDAR points, exploiting available data from camera-LIDAR sensor suites during training. Currently, accurate and affordable range sensor is not available. Stereo cameras and LIDARs measure depth either inaccurately or sparsely/costly. In contrast to the current point-to-point loss evaluation approach, the proposed 3D loss treats point clouds as continuous objects; and therefore, it overcomes the lack of dense ground truth depth due to the sparsity of LIDAR measurements. Experimental evaluations show that the proposed method achieves accurate depth measurement with consistent 3D geometric structures through a monocular camera.
DeepLocNet: Deep Observation Classification and Ranging Bias Regression for Radio Positioning Systems
Feb 02, 2020

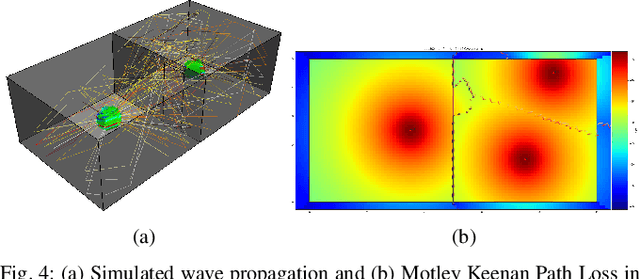
WiFi technology has been used pervasively in fine-grained indoor localization, gesture recognition, and adaptive communication. Achieving better performance in these tasks generally boils down to differentiating Line-Of-Sight (LOS) from Non-Line-Of-Sight (NLOS) signal propagation reliably which generally requires expensive/specialized hardware due to the complex nature of indoor environments. Hence, the development of low-cost accurate positioning systems that exploit available infrastructure is not entirely solved. In this paper, we develop a framework for indoor localization and tracking of ubiquitous mobile devices such as smartphones using on-board sensors. We present a novel deep LOS/NLOS classifier which uses the Received Signal Strength Indicator (RSSI), and can classify the input signal with an accuracy of 85\%. The proposed algorithm can globally localize and track a smartphone (or robot) with a priori unknown location, and with a semi-accurate prior map (error within 0.8 m) of the WiFi Access Points (AP). Through simultaneously solving for the trajectory and the map of access points, we recover a trajectory of the device and corrected locations for the access points. Experimental evaluations of the framework show that localization accuracy is increased by using the trained deep network; furthermore, the system becomes robust to any error in the map of APs.
A Keyframe-based Continuous Visual SLAM for RGB-D Cameras via Nonparametric Joint Geometric and Appearance Representation
Dec 02, 2019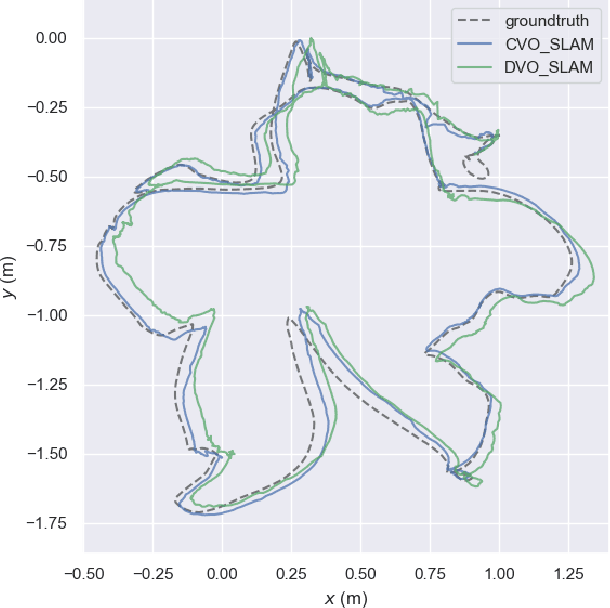
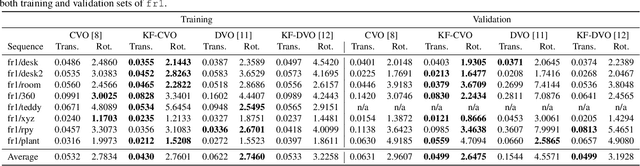
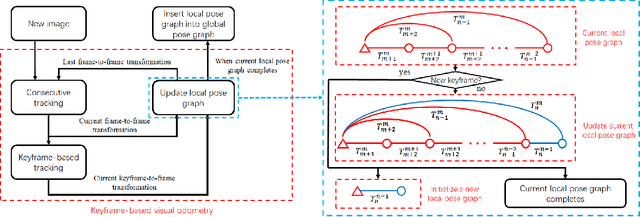

This paper reports on a robust RGB-D SLAM system that performs well in scarcely textured and structured environments. We present a novel keyframe-based continuous visual odometry that builds on the recently developed continuous sensor registration framework. A joint geometric and appearance representation is the result of transforming the RGB-D images into functions that live in a Reproducing Kernel Hilbert Space (RKHS). We solve both registration and keyframe selection problems via the inner product structure available in the RKHS. We also extend the proposed keyframe-based odometry method to a SLAM system using indirect ORB loop-closure constraints. The experimental evaluations using publicly available RGB-D benchmarks show that the developed keyframe selection technique using continuous visual odometry outperforms its robust dense (and direct) visual odometry equivalent. In addition, the developed SLAM system has better generalization across different training and validation sequences; it is robust to the lack of texture and structure in the scene; and shows comparable performance with the state-of-the-art SLAM systems.
Adaptive Continuous Visual Odometry from RGB-D Images
Oct 01, 2019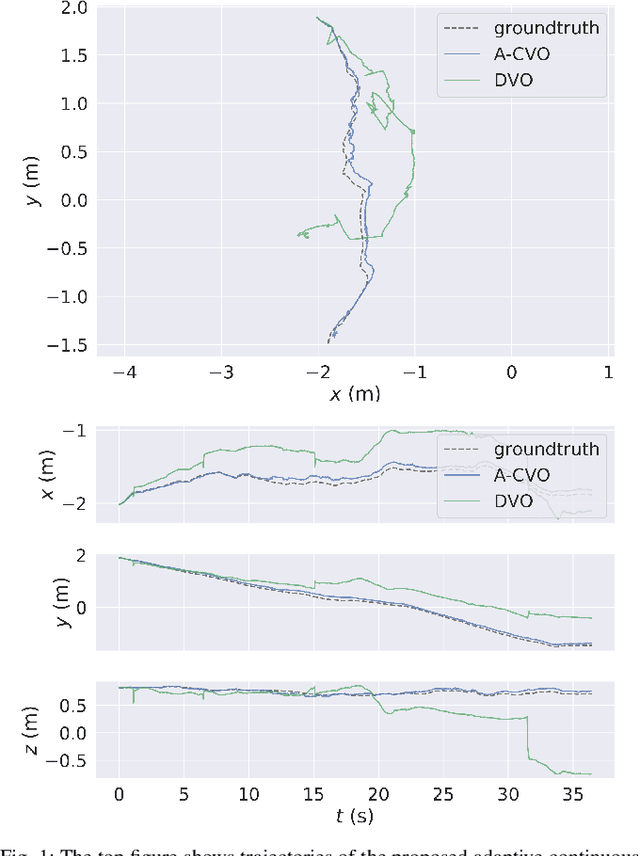
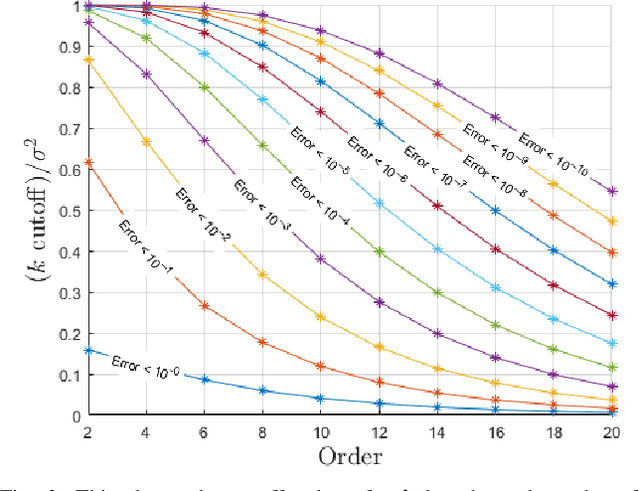

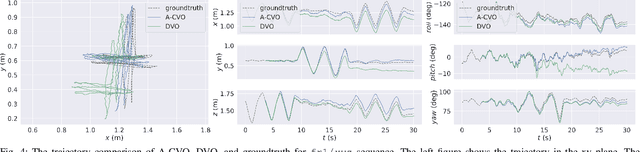
In this paper, we extend the recently developed continuous visual odometry framework for RGB-D cameras to an adaptive framework via online hyperparameter learning. We focus on the case of isotropic kernels with a scalar as the length-scale. In practice and as expected, the length-scale has remarkable impacts on the performance of the original framework. Previously it was handled using a fixed set of conditions within the solver to reduce the length-scale as the algorithm reaches a local minimum. We automate this process by a greedy gradient descent step at each iteration to find the next-best length-scale. Furthermore, to handle failure cases in the gradient descent step where the gradient is not well-behaved, such as the absence of structure or texture in the scene, we use a search interval for the length-scale and guide it gradually toward the smaller values. This latter strategy reverts the adaptive framework to the original setup. The experimental evaluations using publicly available RGB-D benchmarks show the proposed adaptive continuous visual odometry outperforms the original framework and the current state-of-the-art. We also make the software for the developed algorithm publicly available.
Bayesian Spatial Kernel Smoothing for ScalableDense Semantic Mapping
Sep 10, 2019
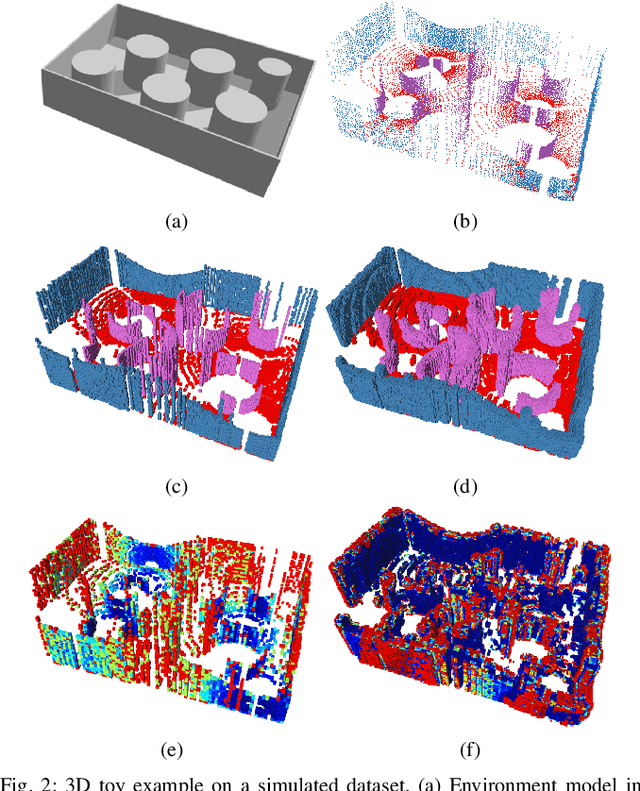


This paper develops a Bayesian continuous 3D semantic occupancy map from noisy point cloud measurements. In particular, we generalize the Bayesian kernel inference model for occupancy (binary) map building to semantic (multi-class) maps. The method nicely reverts to the original occupancy mapping framework when only one occupied class exists in obtained measurements. First, using Categorical likelihood and its conjugate prior distribution, we extend the counting sensor model for binary classification to a multi-class classification problem which results in a unified probabilistic model for both occupancy and semantic probabilities. Secondly, by applying a Bayesian spatial kernel inference to the semantic counting sensor model, we relax the independent grid assumption and bring smoothness and continuity to the map inference. These latter properties enable the method to exploit local correlations present in the environment to predict semantic probabilities in regions unobserved by the sensor while increasing the performance. Lastly, computational efficiency and scalability are achieved by leveraging sparse kernels and a test-data octrees data structure. The evaluations using multiple sequences of stereo camera and LiDAR datasets show that the proposed method consistently outperforms the compared baselines. We also present a qualitative evaluation using data collected by a biped robot platform on the University of Michigan - North Campus.
LiDARTag: A Real-Time Fiducial Tag using Point Clouds
Aug 23, 2019
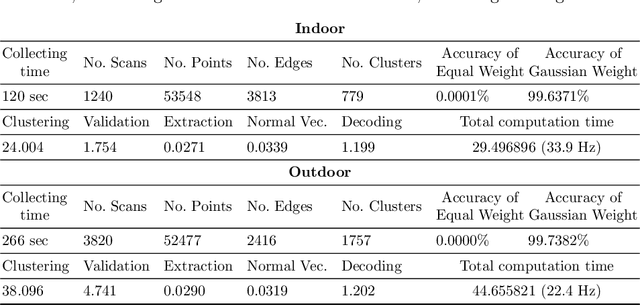

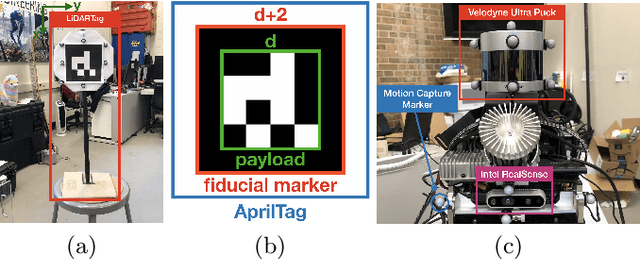
Image-based fiducial markers are widely used in robotics and computer vision problems such as object tracking in cluttered or textureless environments, camera (and multi-sensor) calibration tasks, or vision-based simultaneous localization and mapping (SLAM). The state-of-the-art fiducial marker detection algorithms rely on consistency of the ambient lighting. This paper introduces LiDARTag, a novel fiducial tag design and detection algorithm suitable for light detection and ranging (LiDAR) point clouds. The proposed tag runs in real-time and can process data faster than the currently available LiDAR sensors frequencies. Due to the nature of the LiDAR's sensor, rapidly changing ambient lighting will not affect detection of a LiDARTag; hence, the proposed fiducial marker can operate in a completely dark environment. In addition, the LiDARTag nicely complements available visual fiducial markers as the tag design is compatible with available techniques, such as AprilTags, allowing for efficient multi-sensor fusion and calibration tasks. The experimental results, verified by a motion capture system, confirm the proposed technique can reliably provide a tag's pose and its unique ID code. All implementations are done in C++ and will be available soon at: https://github.com/brucejk/LiDARTag
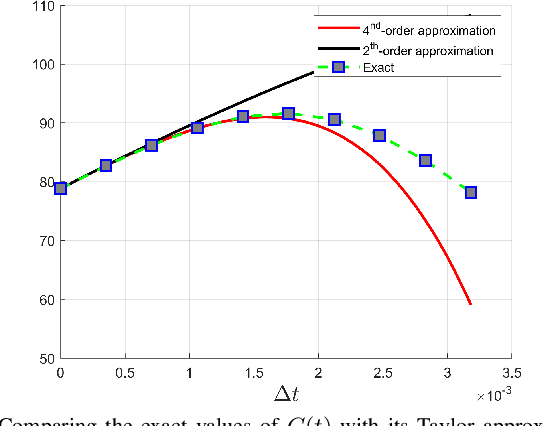
Characterizing the Uncertainty of Jointly Distributed Poses in the Lie Algebra
Jun 18, 2019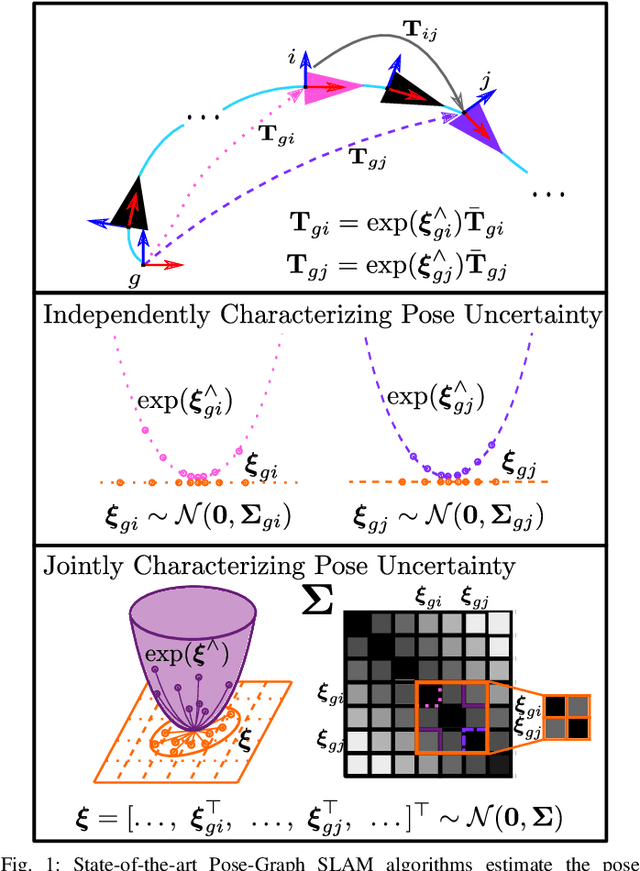
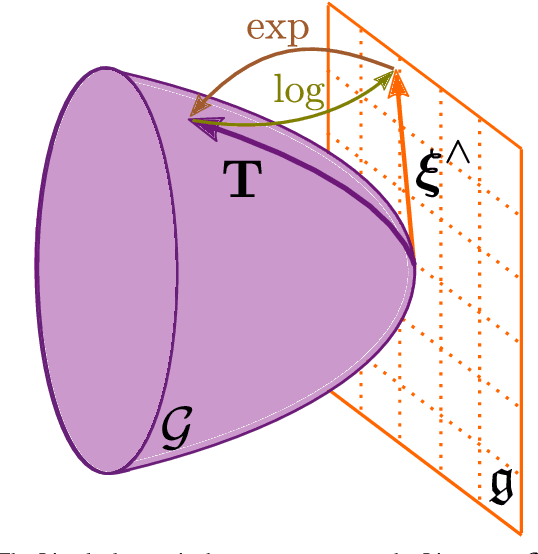
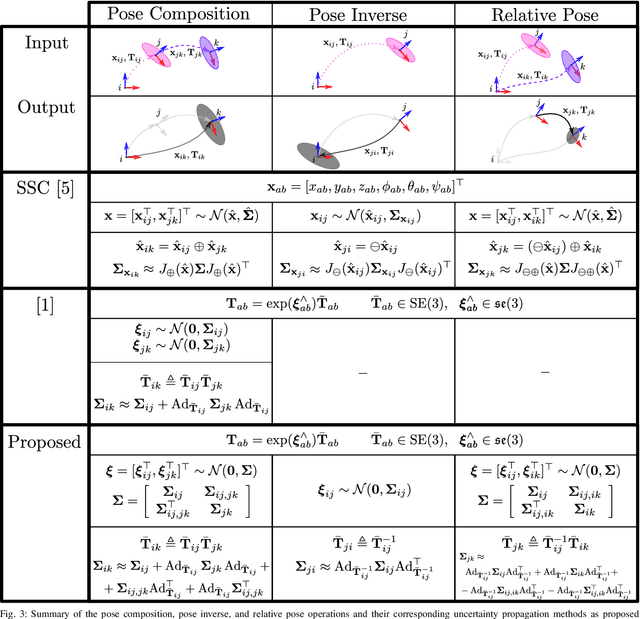
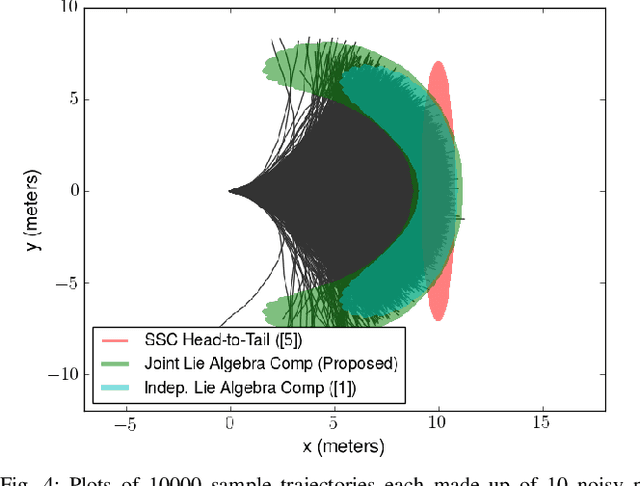
An accurate characterization of pose uncertainty is essential for safe autonomous navigation. Early pose uncertainty characterization methods proposed by Smith, Self, and Cheeseman (SCC), used coordinate-based first-order methods to propagate uncertainty through non-linear functions such as pose composition (head-to-tail), pose inversion, and relative pose extraction (tail-to-tail). Characterizing uncertainty in the Lie Algebra of the special Euclidean group results in better uncertainty estimates. However, existing approaches assume that individual poses are independent. Since factors in a pose graph induce correlation, this independence assumption is usually not reflected in reality. In addition, prior work has focused primarily on the pose composition operation. This paper develops a framework for modeling the uncertainty of jointly distributed poses and describes how to perform the equivalent of the SSC pose operations while characterizing uncertainty in the Lie Algebra. Evaluation on simulated and open-source datasets shows that the proposed methods result in more accurate uncertainty estimates. An accompanying C++ library implementation is also released. This is a pre-print of a paper submitted to IEEE TRO in 2019.
Continuous Direct Sparse Visual Odometry from RGB-D Images
May 21, 2019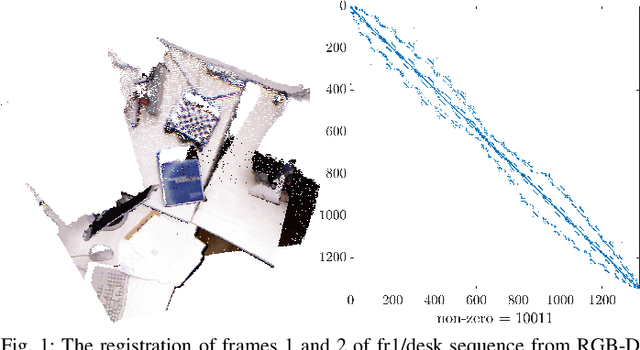
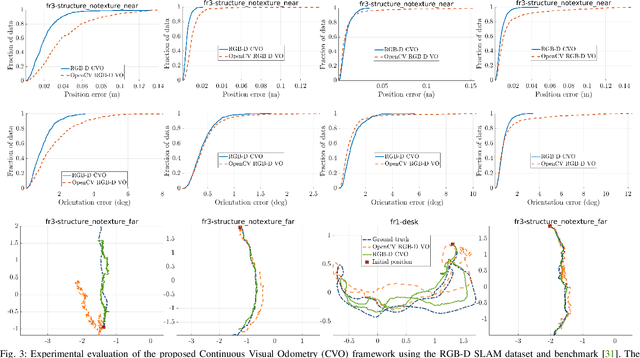

This paper reports on a novel formulation and evaluation of visual odometry from RGB-D images. Assuming a static scene, the developed theoretical framework generalizes the widely used direct energy formulation (photometric error minimization) technique for obtaining a rigid body transformation that aligns two overlapping RGB-D images to a continuous formulation. The continuity is achieved through functional treatment of the problem and representing the process models over RGB-D images in a reproducing kernel Hilbert space; consequently, the registration is not limited to the specific image resolution and the framework is fully analytical with a closed-form derivation of the gradient. We solve the problem by maximizing the inner product between two functions defined over RGB-D images, while the continuous action of the rigid body motion Lie group is captured through the integration of the flow in the corresponding Lie algebra. Energy-based approaches have been extremely successful and the developed framework in this paper shares many of their desired properties such as the parallel structure on both CPUs and GPUs, sparsity, semi-dense tracking, avoiding explicit data association which is computationally expensive, and possible extensions to the simultaneous localization and mapping frameworks. The evaluations on experimental data and comparison with the equivalent energy-based formulation of the problem confirm the effectiveness of the proposed technique, especially, when the lack of structure and texture in the environment is evident.