 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Semantic 3D Dense Occupancy Mapping with Efficient Free Space Representations
Jul 07, 2021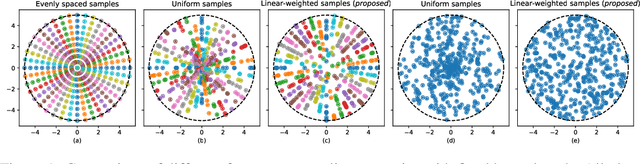

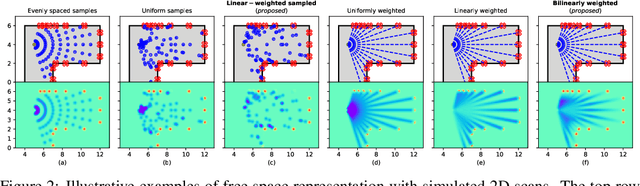
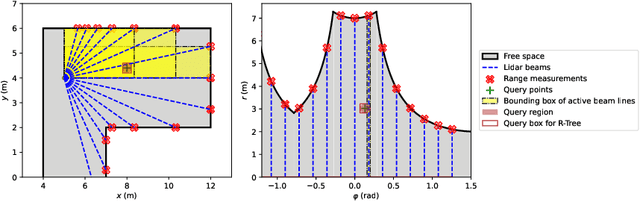
A real-time semantic 3D occupancy mapping framework is proposed in this paper. The mapping framework is based on the Bayesian kernel inference strategy from the literature. Two novel free space representations are proposed to efficiently construct training data and improve the mapping speed, which is a major bottleneck for real-world deployments. Our method achieves real-time mapping even on a consumer-grade CPU. Another important benefit is that our method can handle dynamic scenarios, thanks to the coverage completeness of the proposed algorithm. Experiments on real-world point cloud scan datasets are presented.
VIN: Voxel-based Implicit Network for Joint 3D Object Detection and Segmentation for Lidars
Jul 07, 2021
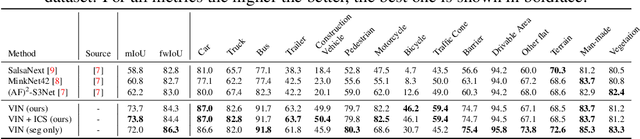
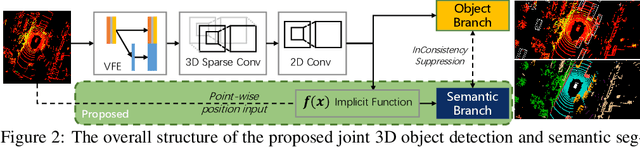
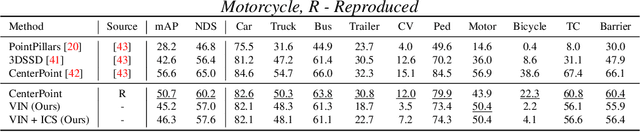
A unified neural network structure is presented for joint 3D object detection and point cloud segmentation in this paper. We leverage rich supervision from both detection and segmentation labels rather than using just one of them. In addition, an extension based on single-stage object detectors is proposed based on the implicit function widely used in 3D scene and object understanding. The extension branch takes the final feature map from the object detection module as input, and produces an implicit function that generates semantic distribution for each point for its corresponding voxel center. We demonstrated the performance of our structure on nuScenes-lidarseg, a large-scale outdoor dataset. Our solution achieves competitive results against state-of-the-art methods in both 3D object detection and point cloud segmentation with little additional computation load compared with object detection solutions. The capability of efficient weakly supervision semantic segmentation of the proposed method is also validated by experiments.
Monocular 3D Vehicle Detection Using Uncalibrated Traffic Cameras through Homography
Mar 29, 2021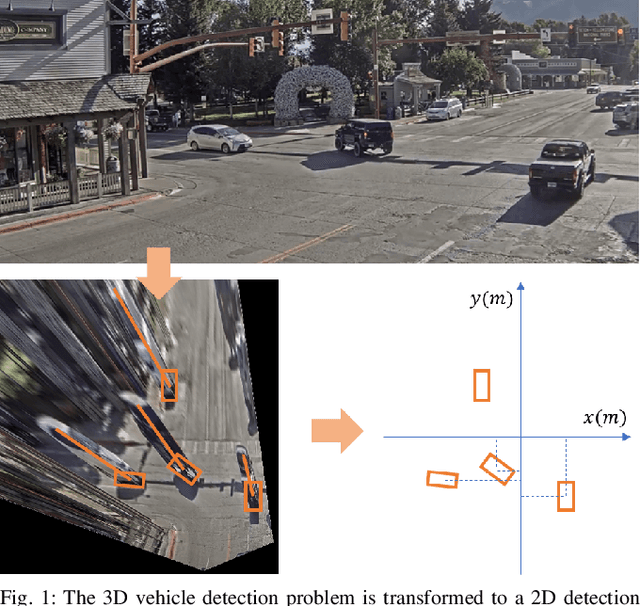
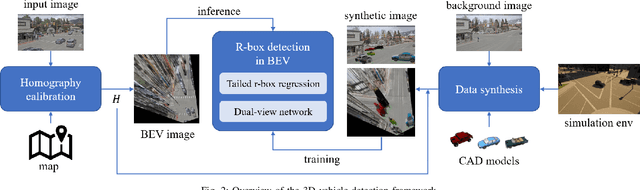

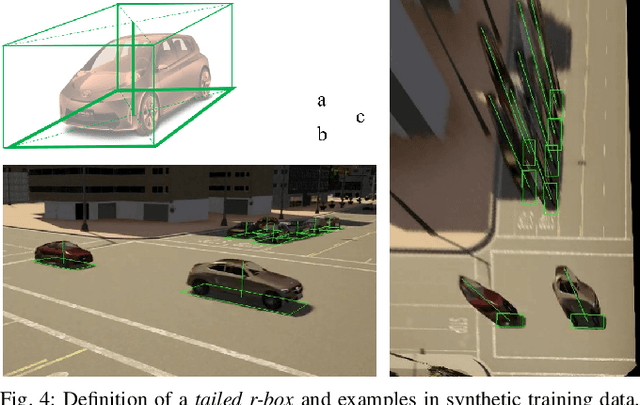
This paper proposes a method to extract the position and pose of vehicles in the 3D world from a single traffic camera. Most previous monocular 3D vehicle detection algorithms focused on cameras on vehicles from the perspective of a driver, and assumed known intrinsic and extrinsic calibration. On the contrary, this paper focuses on the same task using uncalibrated monocular traffic cameras. We observe that the homography between the road plane and the image plane is essential to 3D vehicle detection and the data synthesis for this task, and the homography can be estimated without the camera intrinsics and extrinsics. We conduct 3D vehicle detection by estimating the rotated bounding boxes (r-boxes) in the bird's eye view (BEV) images generated from inverse perspective mapping. We propose a new regression target called \textit{tailed~r-box} and a \textit{dual-view} network architecture which boosts the detection accuracy on warped BEV images. Experiments show that the proposed method can generalize to new camera and environment setups despite not seeing imaged from them during training.
Differentiable Computational Geometry for 2D and 3D machine learning
Nov 22, 2020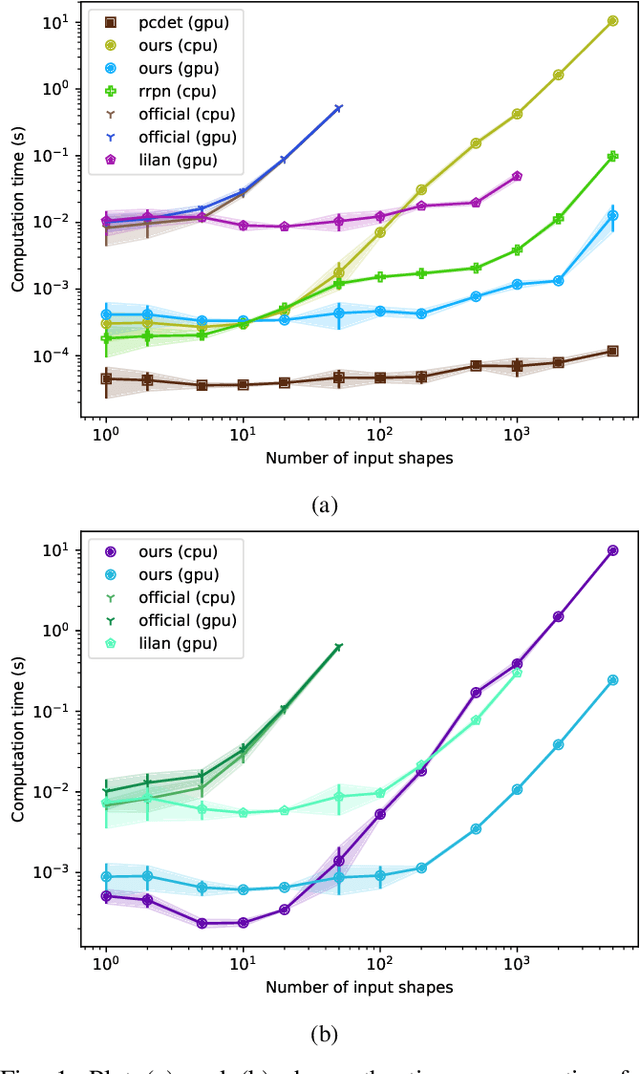
With the growth of machine learning algorithms with geometry primitives, a high-efficiency library with differentiable geometric operators are desired. We present an optimized Differentiable Geometry Algorithm Library (DGAL) loaded with implementations of differentiable operators for geometric primitives like lines and polygons. The library is a header-only templated C++ library with GPU support. We discuss the internal design of the library and benchmark its performance on some tasks with other implementations.
Uncertainty-Aware Voxel based 3D Object Detection and Tracking with von-Mises Loss
Nov 04, 2020
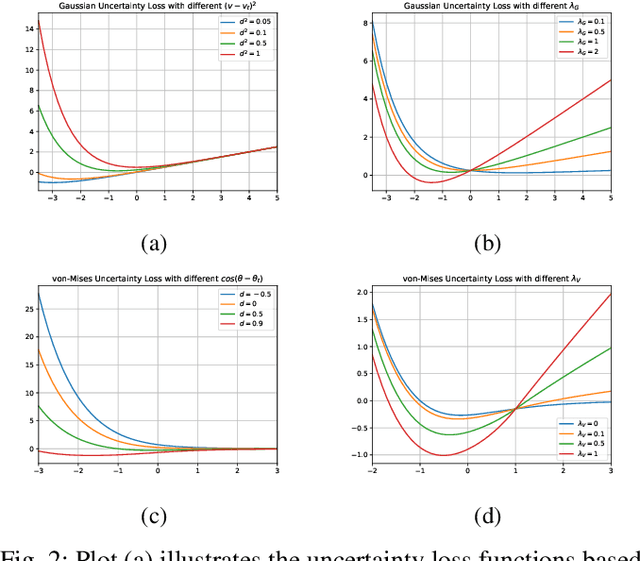

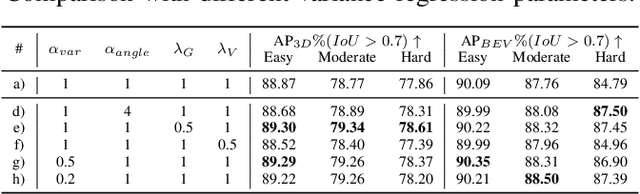
Object detection and tracking is a key task in autonomy. Specifically, 3D object detection and tracking have been an emerging hot topic recently. Although various methods have been proposed for object detection, uncertainty in the 3D detection and tracking tasks has been less explored. Uncertainty helps us tackle the error in the perception system and improve robustness. In this paper, we propose a method for improving target tracking performance by adding uncertainty regression to the SECOND detector, which is one of the most representative algorithms of 3D object detection. Our method estimates positional and dimensional uncertainties with Gaussian Negative Log-Likelihood (NLL) Loss for estimation and introduces von-Mises NLL Loss for angular uncertainty estimation. We fed the uncertainty output into a classical object tracking framework and proved that our method increased the tracking performance compared against the vanilla tracker with constant covariance assumption.
Monocular Depth Prediction Through Continuous 3D Loss
Mar 21, 2020



This paper reports a new continuous 3D loss function for learning depth from monocular images. The dense depth prediction from a monocular image is supervised using sparse LIDAR points, exploiting available data from camera-LIDAR sensor suites during training. Currently, accurate and affordable range sensor is not available. Stereo cameras and LIDARs measure depth either inaccurately or sparsely/costly. In contrast to the current point-to-point loss evaluation approach, the proposed 3D loss treats point clouds as continuous objects; and therefore, it overcomes the lack of dense ground truth depth due to the sparsity of LIDAR measurements. Experimental evaluations show that the proposed method achieves accurate depth measurement with consistent 3D geometric structures through a monocular camera.
Mcity Data Collection for Automated Vehicles Study
Dec 12, 2019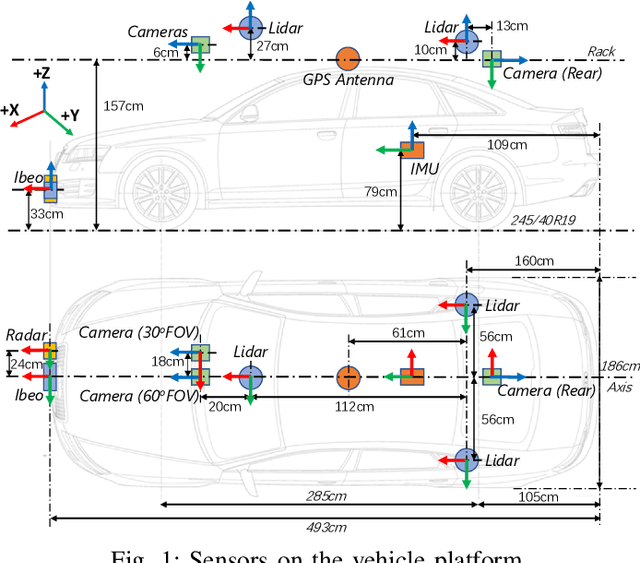
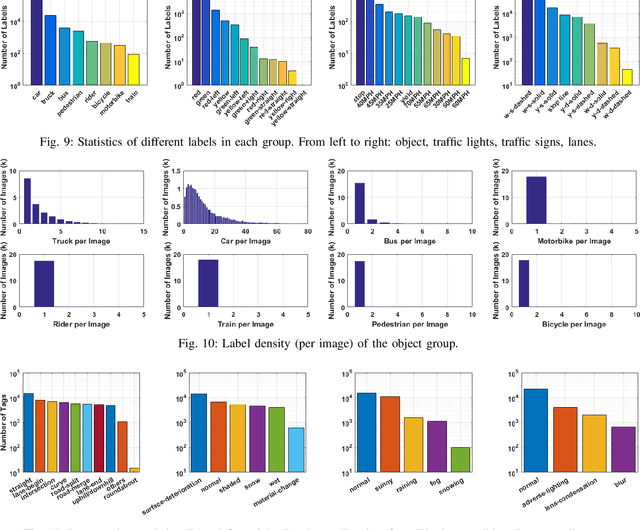
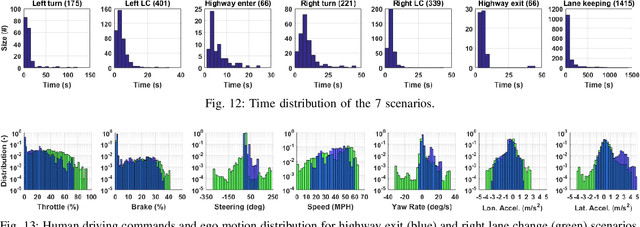
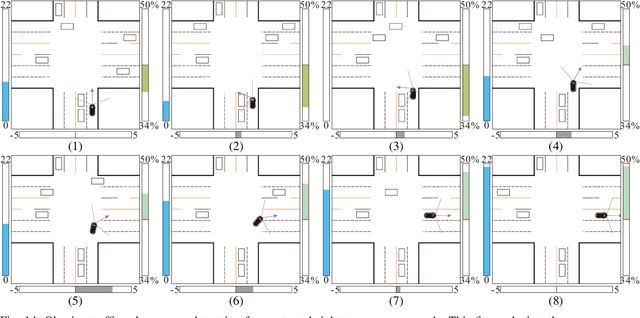
The main goal of this paper is to introduce the data collection effort at Mcity targeting automated vehicle development. We captured a comprehensive set of data from a set of perception sensors (Lidars, Radars, Cameras) as well as vehicle steering/brake/throttle inputs and an RTK unit. Two in-cabin cameras record the human driver's behaviors for possible future use. The naturalistic driving on selected open roads is recorded at different time of day and weather conditions. We also perform designed choreography data collection inside the Mcity test facility focusing on vehicle to vehicle, and vehicle to vulnerable road user interactions which is quite unique among existing open-source datasets. The vehicle platform, data content, tags/labels, and selected analysis results are shown in this paper.