 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuick Learner Automated Vehicle Adapting its Roadmanship to Varying Traffic Cultures with Meta Reinforcement Learning
Paper and Code
Apr 18, 2021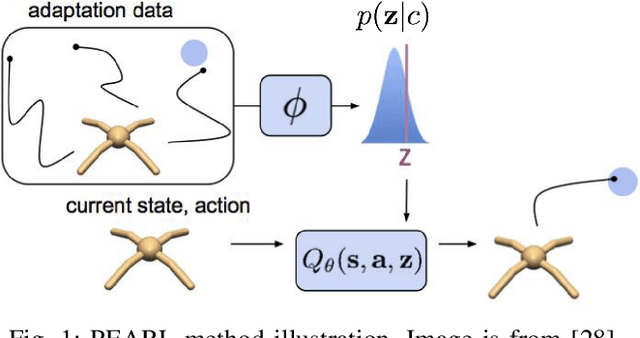

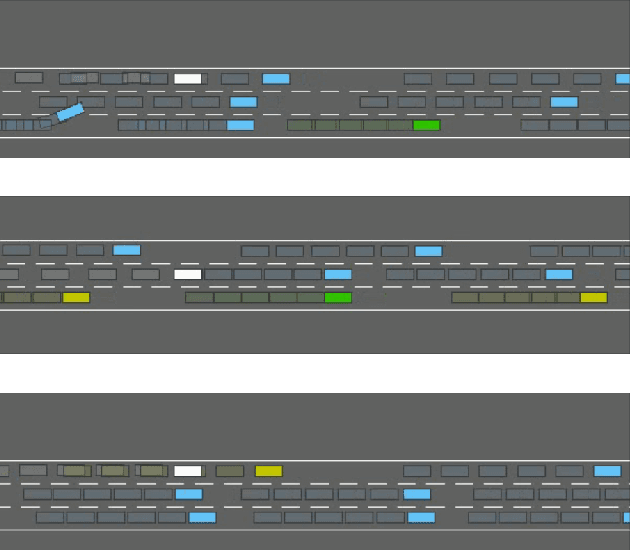
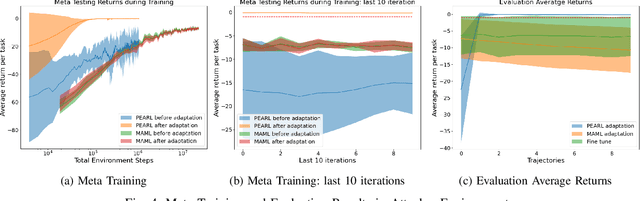
It is essential for an automated vehicle in the field to perform discretionary lane changes with appropriate roadmanship - driving safely and efficiently without annoying or endangering other road users - under a wide range of traffic cultures and driving conditions. While deep reinforcement learning methods have excelled in recent years and been applied to automated vehicle driving policy, there are concerns about their capability to quickly adapt to unseen traffic with new environment dynamics. We formulate this challenge as a multi-Markov Decision Processes (MDPs) adaptation problem and developed Meta Reinforcement Learning (MRL) driving policies to showcase their quick learning capability. Two types of distribution variation in environments were designed and simulated to validate the fast adaptation capability of resulting MRL driving policies which significantly outperform a baseline RL.