 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Agentic Reasoning in LLM Judges via Tool-Integrated Reinforcement Learning
Oct 27, 2025
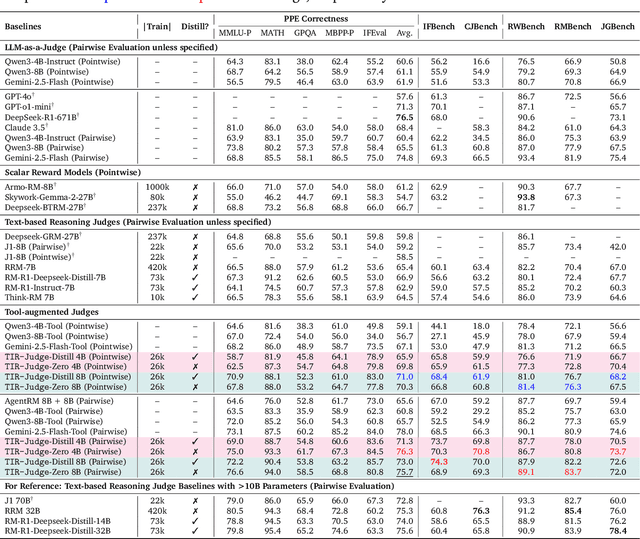
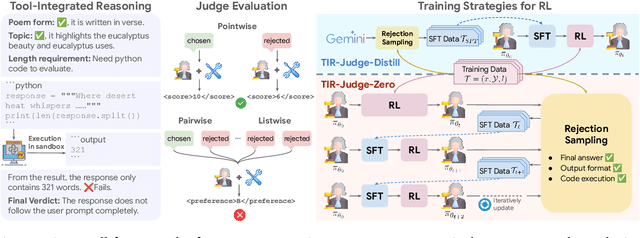
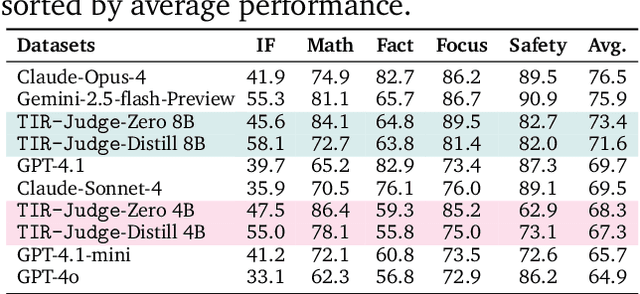
Large Language Models (LLMs) are widely used as judges to evaluate response quality, providing a scalable alternative to human evaluation. However, most LLM judges operate solely on intrinsic text-based reasoning, limiting their ability to verify complex constraints or perform accurate computation. Motivated by the success of tool-integrated reasoning (TIR) in numerous tasks, we propose TIR-Judge, an end-to-end RL framework for training LLM judges that integrates a code executor for precise evaluation. TIR-Judge is built on three principles: (i) diverse training across verifiable and non-verifiable domains, (ii) flexible judgment formats (pointwise, pairwise, listwise), and (iii) iterative RL that bootstraps directly from the initial model without distillation. On seven public benchmarks, TIR-Judge surpasses strong reasoning-based judges by up to 6.4% (pointwise) and 7.7% (pairwise), and achieves listwise performance comparable to Claude-Opus-4 despite having only 8B parameters. Remarkably, TIR-Judge-Zero - trained entirely without distilled judge trajectories, matches the performance of distilled variants, demonstrating that tool-augmented judges can self-evolve through iterative reinforcement learning.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
UT5: Pretraining Non autoregressive T5 with unrolled denoising
Nov 14, 2023Recent advances in Transformer-based Large Language Models have made great strides in natural language generation. However, to decode K tokens, an autoregressive model needs K sequential forward passes, which may be a performance bottleneck for large language models. Many non-autoregressive (NAR) research are aiming to address this sequentiality bottleneck, albeit many have focused on a dedicated architecture in supervised benchmarks. In this work, we studied unsupervised pretraining for non auto-regressive T5 models via unrolled denoising and shown its SoTA results in downstream generation tasks such as SQuAD question generation and XSum.
Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
Sep 25, 2019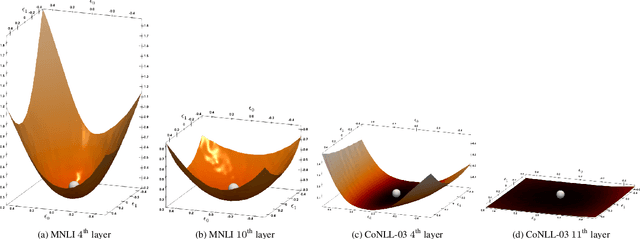
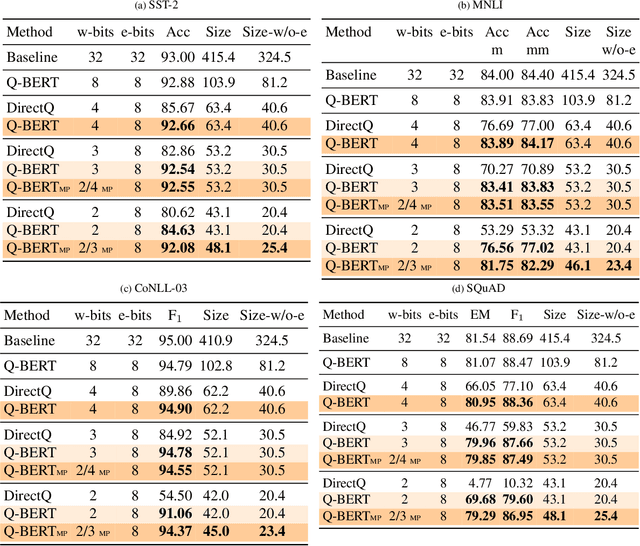
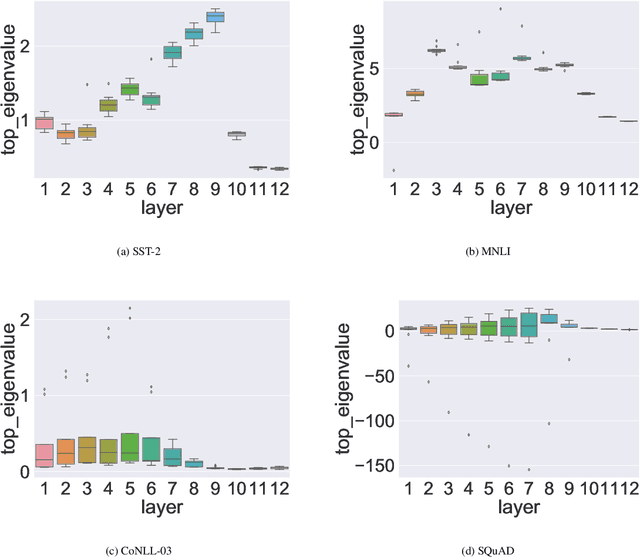
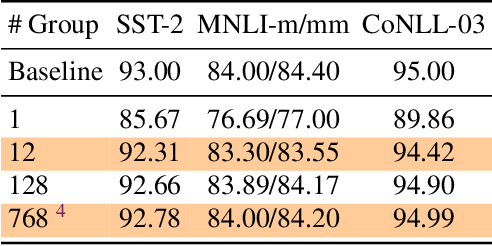
Transformer based architectures have become de-facto models used for a range of Natural Language Processing tasks. In particular, the BERT based models achieved significant accuracy gain for GLUE tasks, CoNLL-03 and SQuAD. However, BERT based models have a prohibitive memory footprint and latency. As a result, deploying BERT based models in resource constrained environments has become a challenging task. In this work, we perform an extensive analysis of fine-tuned BERT models using second order Hessian information, and we use our results to propose a novel method for quantizing BERT models to ultra low precision. In particular, we propose a new group-wise quantization scheme, and we use a Hessian based mix-precision method to compress the model further. We extensively test our proposed method on BERT downstream tasks of SST-2, MNLI, CoNLL-03, and SQuAD. We can achieve comparable performance to baseline with at most $2.3\%$ performance degradation, even with ultra-low precision quantization down to 2 bits, corresponding up to $13\times$ compression of the model parameters, and up to $4\times$ compression of the embedding table as well as activations. Among all tasks, we observed the highest performance loss for BERT fine-tuned on SQuAD. By probing into the Hessian based analysis as well as visualization, we show that this is related to the fact that current training/fine-tuning strategy of BERT does not converge for SQuAD.
Inefficiency of K-FAC for Large Batch Size Training
Mar 14, 2019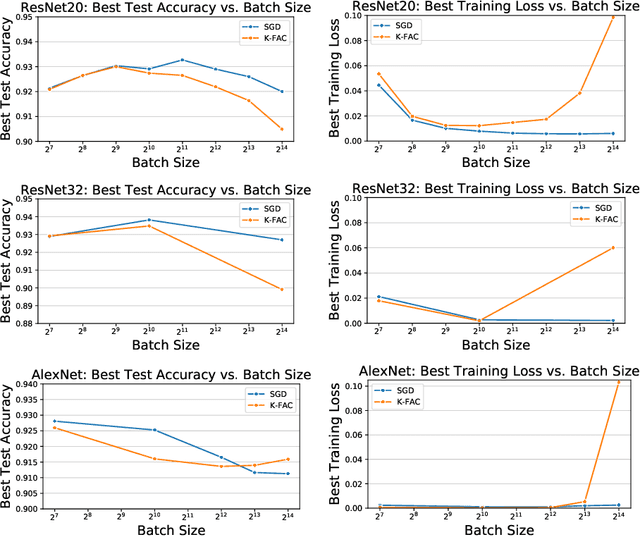
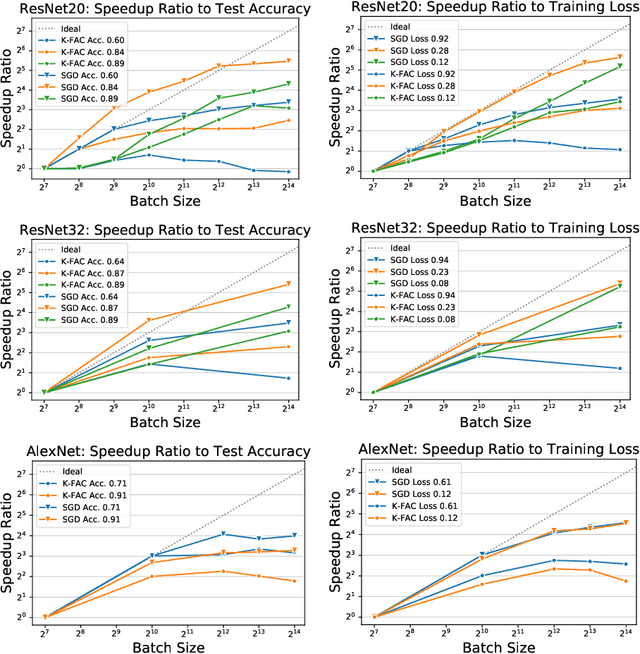
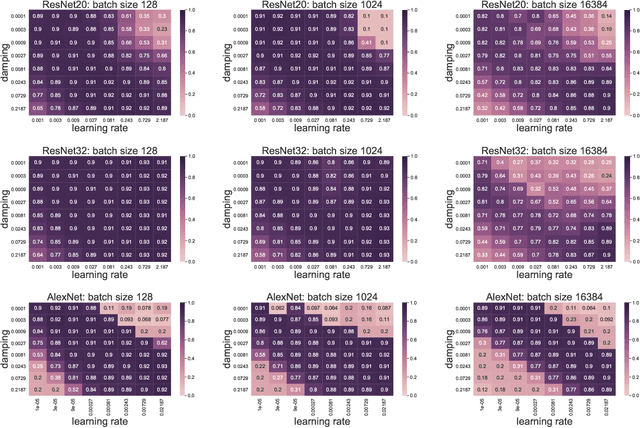
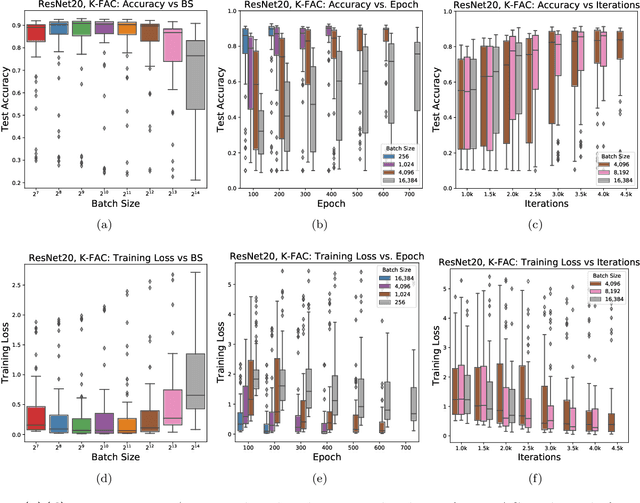
In stochastic optimization, large batch training can leverage parallel resources to produce faster wall-clock training times per epoch. However, for both training loss and testing error, recent results analyzing large batch Stochastic Gradient Descent (SGD) have found sharp diminishing returns beyond a certain critical batch size. In the hopes of addressing this, the Kronecker-Factored Approximate Curvature (\mbox{K-FAC}) method has been hypothesized to allow for greater scalability to large batch sizes for non-convex machine learning problems, as well as greater robustness to variation in hyperparameters. Here, we perform a detailed empirical analysis of these two hypotheses, evaluating performance in terms of both wall-clock time and aggregate computational cost. Our main results are twofold: first, we find that \mbox{K-FAC} does not exhibit improved large-batch scalability behavior, as compared to SGD; and second, we find that \mbox{K-FAC}, in addition to requiring more hyperparameters to tune, suffers from the same hyperparameter sensitivity patterns as SGD. We discuss extensive results using residual networks on \mbox{CIFAR-10}, as well as more general implications of our findings.