 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTask: Task Aware Multi-Faceted Single Model for Multi-Task Ads Relevance
Jul 09, 2024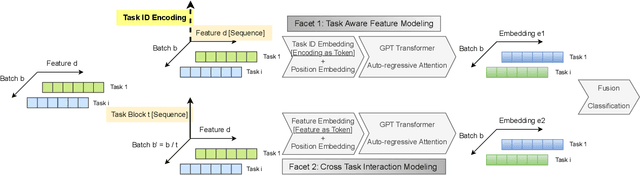


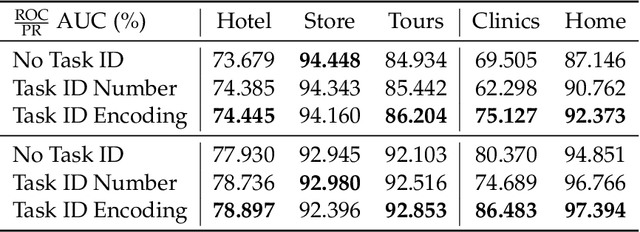
Ads relevance models are crucial in determining the relevance between user search queries and ad offers, often framed as a classification problem. The complexity of modeling increases significantly with multiple ad types and varying scenarios that exhibit both similarities and differences. In this work, we introduce a novel multi-faceted attention model that performs task aware feature combination and cross task interaction modeling. Our technique formulates the feature combination problem as "language" modeling with auto-regressive attentions across both feature and task dimensions. Specifically, we introduce a new dimension of task ID encoding for task representations, thereby enabling precise relevance modeling across diverse ad scenarios with substantial improvement in generality capability for unseen tasks. We demonstrate that our model not only effectively handles the increased computational and maintenance demands as scenarios proliferate, but also outperforms generalized DNN models and even task-specific models across a spectrum of ad applications using a single unified model.
Novel Models for High-Dimensional Imaging: High-Resolution fMRI Acceleration and Quantification
Jul 08, 2024



The goals of functional Magnetic Resonance Imaging (fMRI) include high spatial and temporal resolutions with a high signal-to-noise ratio (SNR). To simultaneously improve spatial and temporal resolutions and maintain the high SNR advantage of OSSI, we present novel pipelines for fast acquisition and high-resolution fMRI reconstruction and physics parameter quantification. We propose a patch-tensor low-rank model, a physics-based manifold model, and a voxel-wise attention network. With novel models for acquisition and reconstruction, we demonstrate that we can improve SNR and resolution simultaneously without compromising scan time. All the proposed models outperform other comparison approaches with higher resolution and more functional information.
LoPT: Low-Rank Prompt Tuning for Parameter Efficient Language Models
Jun 27, 2024In prompt tuning, a prefix or suffix text is added to the prompt, and the embeddings (soft prompts) or token indices (hard prompts) of the prefix/suffix are optimized to gain more control over language models for specific tasks. This approach eliminates the need for hand-crafted prompt engineering or explicit model fine-tuning. Prompt tuning is significantly more parameter-efficient than model fine-tuning, as it involves optimizing partial inputs of language models to produce desired outputs. In this work, we aim to further reduce the amount of trainable parameters required for a language model to perform well on specific tasks. We propose Low-rank Prompt Tuning (LoPT), a low-rank model for prompts that achieves efficient prompt optimization. The proposed method demonstrates similar outcomes to full parameter prompt tuning while reducing the number of trainable parameters by a factor of 5. It also provides promising results compared to the state-of-the-art methods that would require 10 to 20 times more parameters.
Paying U-Attention to Textures: Multi-Stage Hourglass Vision Transformer for Universal Texture Synthesis
Feb 23, 2022

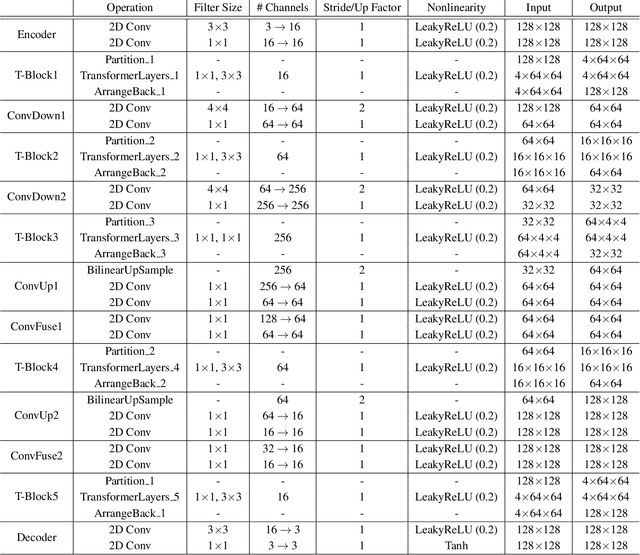

We present a novel U-Attention vision Transformer for universal texture synthesis. We exploit the natural long-range dependencies enabled by the attention mechanism to allow our approach to synthesize diverse textures while preserving their structures in a single inference. We propose a multi-stage hourglass backbone that attends to the global structure and performs patch mapping at varying scales in a coarse-to-fine-to-coarse stream. Further completed by skip connection and convolution designs that propagate and fuse information at different scales, our U-Attention architecture unifies attention to microstructures, mesostructures and macrostructures, and progressively refines synthesis results at successive stages. We show that our method achieves stronger 2$\times$ synthesis than previous work on both stochastic and structured textures while generalizing to unseen textures without fine-tuning. Ablation studies demonstrate the effectiveness of each component of our architecture.
Manifold Model for High-Resolution fMRI Joint Reconstruction and Dynamic Quantification
Apr 16, 2021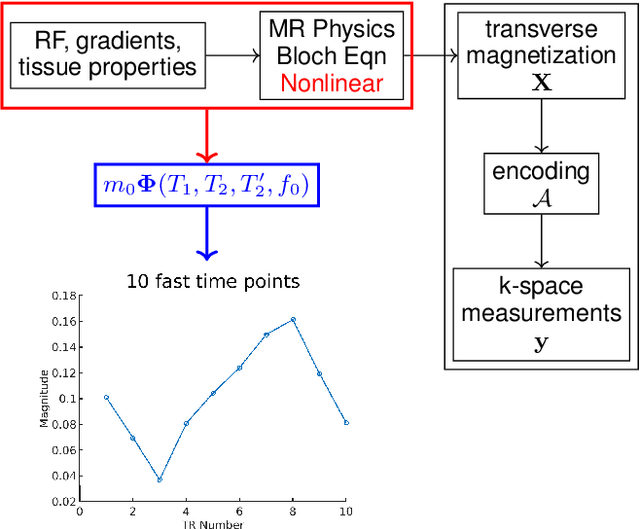
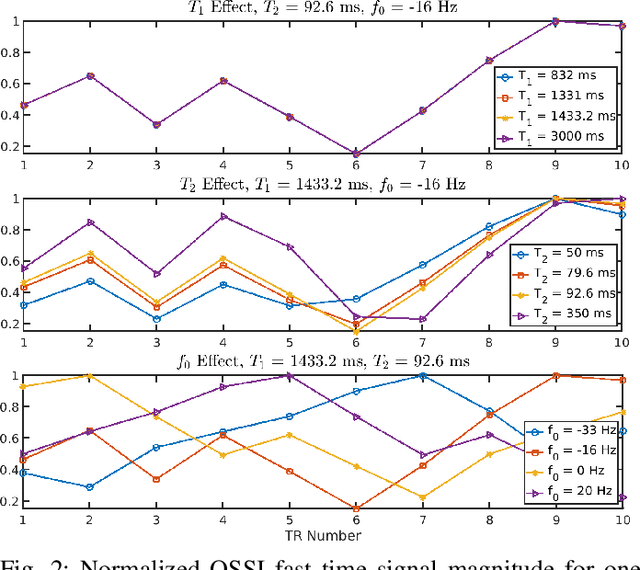
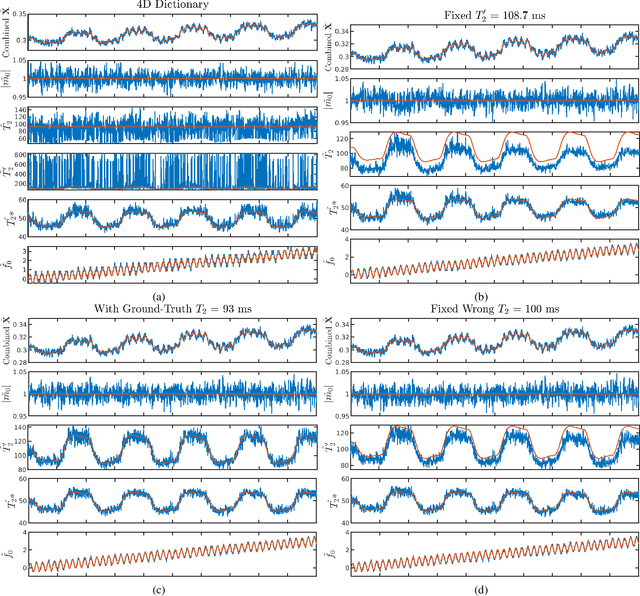
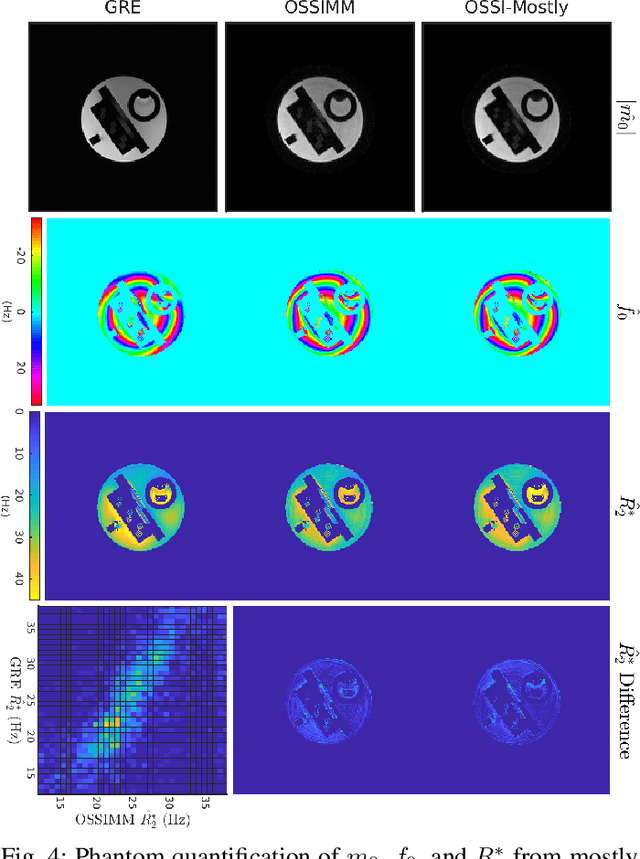
Oscillating Steady-State Imaging (OSSI) is a recent fMRI acquisition method that exploits a large and oscillating signal, and can provide high SNR fMRI. However, the oscillatory nature of the signal leads to an increased number of acquisitions. To improve temporal resolution and accurately model the nonlinearity of OSSI signals, we build the MR physics for OSSI signal generation as a regularizer for the undersampled reconstruction rather than using subspace models that are not well suited for the data. Our proposed physics-based manifold model turns the disadvantages of OSSI acquisition into advantages and enables joint reconstruction and quantification. OSSI manifold model (OSSIMM) outperforms subspace models and reconstructs high-resolution fMRI images with a factor of 12 acceleration and without spatial or temporal resolution smoothing. Furthermore, OSSIMM can dynamically quantify important physics parameters, including $R_2^*$ maps, with a temporal resolution of 150 ms.