 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTkvr: KV Cache Retrieval for Long-Context LLMs via Centroid then Token Indexing
Dec 17, 2025Large language models (LLMs) are increasingly applied in long-context scenarios such as multi-turn conversations. However, long contexts pose significant challenges for inference efficiency, including high memory overhead from Key-Value (KV) cache and increased latency due to excessive memory accesses. Recent methods for dynamic KV selection struggle with trade-offs: block-level indexing degrades accuracy by retrieving irrelevant KV entries, while token-level indexing incurs high latency from inefficient retrieval mechanisms. In this paper, we propose CTKVR, a novel centroid-then-token KV retrieval scheme that addresses these limitations. CTKVR leverages a key observation: query vectors adjacent in position exhibit high similarity after Rotary Position Embedding (RoPE) and share most of their top-k KV cache entries. Based on this insight, CTKVR employs a two-stage retrieval strategy: lightweight centroids are precomputed during prefilling for centroid-grained indexing, followed by token-level refinement for precise KV retrieval. This approach balances retrieval efficiency and accuracy. To further enhance performance, we implement an optimized system for indexing construction and search using CPU-GPU co-execution. Experimentally, CTKVR achieves superior performance across multiple benchmarks with less than 1% accuracy degradation. Meanwhile, CTKVR delivers 3 times and 4 times throughput speedups on Llama-3-8B and Yi-9B at 96K context length across diverse GPU hardware.
CDSM: Cascaded Deep Semantic Matching on Textual Graphs Leveraging Ad-hoc Neighbor Selection
Dec 07, 2022Deep semantic matching aims to discriminate the relationship between documents based on deep neural networks. In recent years, it becomes increasingly popular to organize documents with a graph structure, then leverage both the intrinsic document features and the extrinsic neighbor features to derive discrimination. Most of the existing works mainly care about how to utilize the presented neighbors, whereas limited effort is made to filter appropriate neighbors. We argue that the neighbor features could be highly noisy and partially useful. Thus, a lack of effective neighbor selection will not only incur a great deal of unnecessary computation cost, but also restrict the matching accuracy severely. In this work, we propose a novel framework, Cascaded Deep Semantic Matching (CDSM), for accurate and efficient semantic matching on textual graphs. CDSM is highlighted for its two-stage workflow. In the first stage, a lightweight CNN-based ad-hod neighbor selector is deployed to filter useful neighbors for the matching task with a small computation cost. We design both one-step and multi-step selection methods. In the second stage, a high-capacity graph-based matching network is employed to compute fine-grained relevance scores based on the well-selected neighbors. It is worth noting that CDSM is a generic framework which accommodates most of the mainstream graph-based semantic matching networks. The major challenge is how the selector can learn to discriminate the neighbors usefulness which has no explicit labels. To cope with this problem, we design a weak-supervision strategy for optimization, where we train the graph-based matching network at first and then the ad-hoc neighbor selector is learned on top of the annotations from the matching network.
A Mutually Reinforced Framework for Pretrained Sentence Embeddings
Feb 28, 2022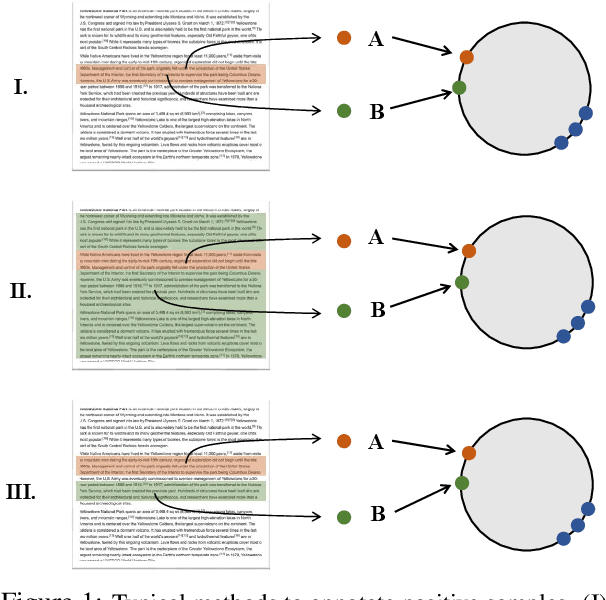
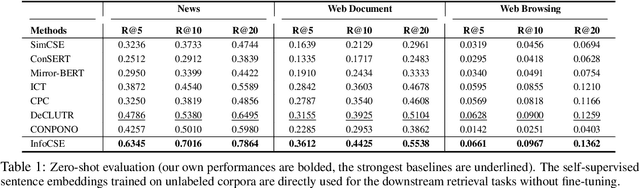

The lack of labeled data is a major obstacle to learning high-quality sentence embeddings. Recently, self-supervised contrastive learning (SCL) is regarded as a promising way to address this problem. However, the existing works mainly rely on hand-crafted data annotation heuristics to generate positive training samples, which not only call for domain expertise and laborious tuning, but are also prone to the following unfavorable cases: 1) trivial positives, 2) coarse-grained positives, and 3) false positives. As a result, the self-supervision's quality can be severely limited in reality. In this work, we propose a novel framework InfoCSE to address the above problems. Instead of relying on annotation heuristics defined by humans, it leverages the sentence representation model itself and realizes the following iterative self-supervision process: on one hand, the improvement of sentence representation may contribute to the quality of data annotation; on the other hand, more effective data annotation helps to generate high-quality positive samples, which will further improve the current sentence representation model. In other words, the representation learning and data annotation become mutually reinforced, where a strong self-supervision effect can be derived. Extensive experiments are performed based on three benchmark datasets, where notable improvements can be achieved against the existing SCL-based methods.
GraphFormers: GNN-nested Language Models for Linked Text Representation
May 06, 2021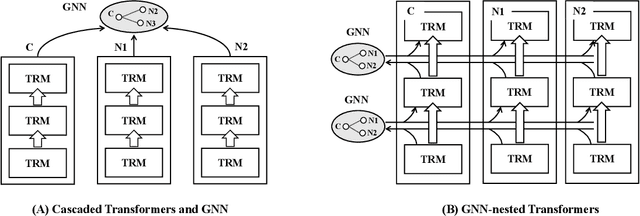
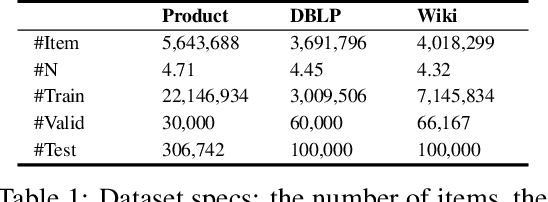


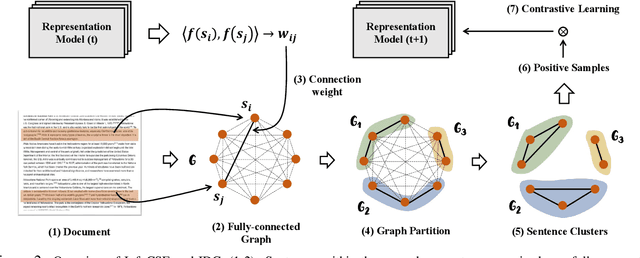
Linked text representation is critical for many intelligent web applications, such as online advertisement and recommender systems. Recent breakthroughs on pretrained language models and graph neural networks facilitate the development of corresponding techniques. However, the existing works mainly rely on cascaded model structures: the texts are independently encoded by language models at first, and the textual embeddings are further aggregated by graph neural networks. We argue that the neighbourhood information is insufficiently utilized within the above process, which restricts the representation quality. In this work, we propose GraphFormers, where graph neural networks are nested alongside each transformer layer of the language models. On top of the above architecture, the linked texts will iteratively extract neighbourhood information for the enhancement of their own semantics. Such an iterative workflow gives rise to more effective utilization of neighbourhood information, which contributes to the representation quality. We further introduce an adaptation called unidirectional GraphFormers, which is much more efficient and comparably effective; and we leverage a pretraining strategy called the neighbourhood-aware masked language modeling to enhance the training effect. We perform extensive experiment studies with three large-scale linked text datasets, whose results verify the effectiveness of our proposed methods.
Hybrid Encoder: Towards Efficient and Precise Native AdsRecommendation via Hybrid Transformer Encoding Networks
Apr 22, 2021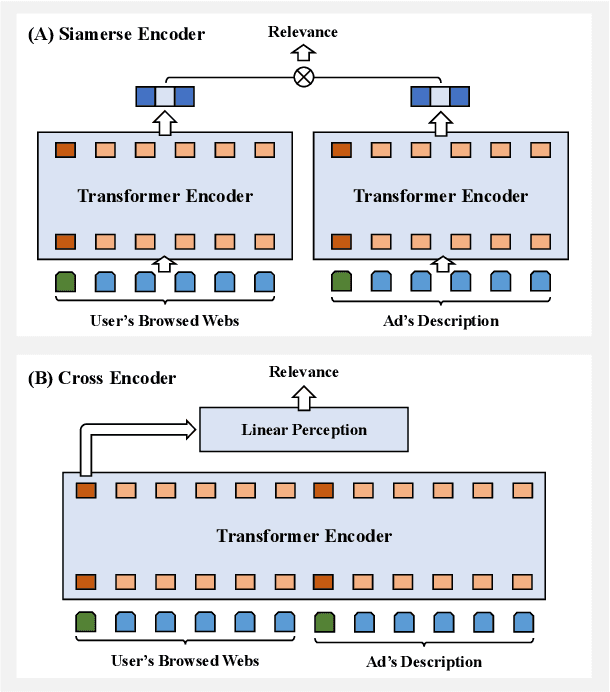
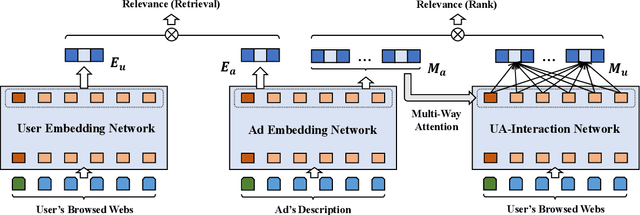
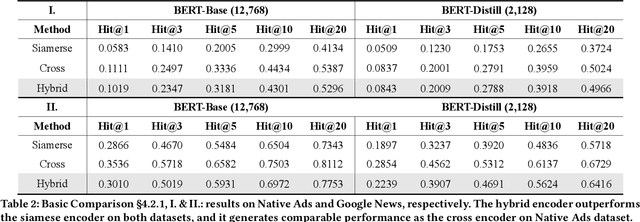
Transformer encoding networks have been proved to be a powerful tool of understanding natural languages. They are playing a critical role in native ads service, which facilitates the recommendation of appropriate ads based on user's web browsing history. For the sake of efficient recommendation, conventional methods would generate user and advertisement embeddings independently with a siamese transformer encoder, such that approximate nearest neighbour search (ANN) can be leveraged. Given that the underlying semantic about user and ad can be complicated, such independently generated embeddings are prone to information loss, which leads to inferior recommendation quality. Although another encoding strategy, the cross encoder, can be much more accurate, it will lead to huge running cost and become infeasible for realtime services, like native ads recommendation. In this work, we propose hybrid encoder, which makes efficient and precise native ads recommendation through two consecutive steps: retrieval and ranking. In the retrieval step, user and ad are encoded with a siamese component, which enables relevant candidates to be retrieved via ANN search. In the ranking step, it further represents each ad with disentangled embeddings and each user with ad-related embeddings, which contributes to the fine-grained selection of high-quality ads from the candidate set. Both steps are light-weighted, thanks to the pre-computed and cached intermedia results. To optimize the hybrid encoder's performance in this two-stage workflow, a progressive training pipeline is developed, which builds up the model's capability in the retrieval and ranking task step-by-step. The hybrid encoder's effectiveness is experimentally verified: with very little additional cost, it outperforms the siamese encoder significantly and achieves comparable recommendation quality as the cross encoder.