 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mutually Reinforced Framework for Pretrained Sentence Embeddings
Paper and Code
Feb 28, 2022
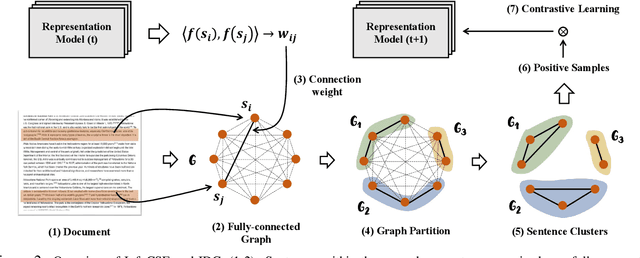

The lack of labeled data is a major obstacle to learning high-quality sentence embeddings. Recently, self-supervised contrastive learning (SCL) is regarded as a promising way to address this problem. However, the existing works mainly rely on hand-crafted data annotation heuristics to generate positive training samples, which not only call for domain expertise and laborious tuning, but are also prone to the following unfavorable cases: 1) trivial positives, 2) coarse-grained positives, and 3) false positives. As a result, the self-supervision's quality can be severely limited in reality. In this work, we propose a novel framework InfoCSE to address the above problems. Instead of relying on annotation heuristics defined by humans, it leverages the sentence representation model itself and realizes the following iterative self-supervision process: on one hand, the improvement of sentence representation may contribute to the quality of data annotation; on the other hand, more effective data annotation helps to generate high-quality positive samples, which will further improve the current sentence representation model. In other words, the representation learning and data annotation become mutually reinforced, where a strong self-supervision effect can be derived. Extensive experiments are performed based on three benchmark datasets, where notable improvements can be achieved against the existing SCL-based methods.