 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Multi-future Occupancy Forecasting for Autonomous Driving
Jul 30, 2024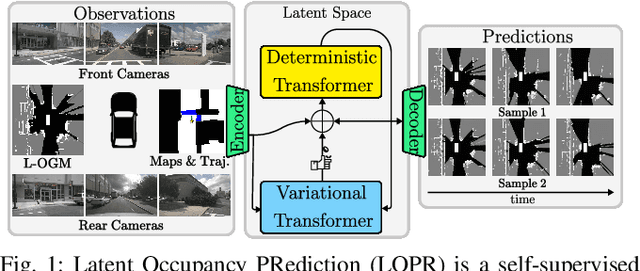

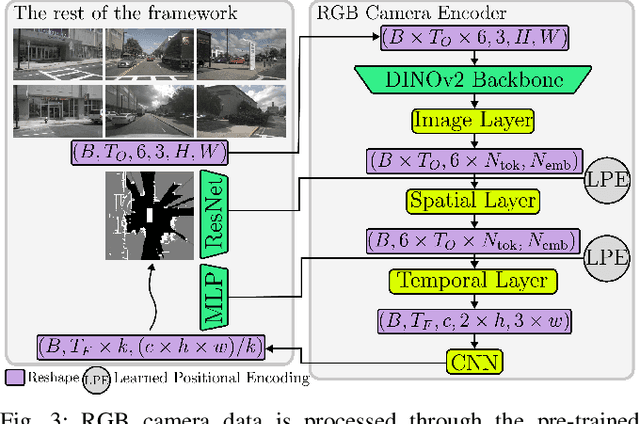
Environment prediction frameworks are critical for the safe navigation of autonomous vehicles (AVs) in dynamic settings. LiDAR-generated occupancy grid maps (L-OGMs) offer a robust bird's-eye view for the scene representation, enabling self-supervised joint scene predictions while exhibiting resilience to partial observability and perception detection failures. Prior approaches have focused on deterministic L-OGM prediction architectures within the grid cell space. While these methods have seen some success, they frequently produce unrealistic predictions and fail to capture the stochastic nature of the environment. Additionally, they do not effectively integrate additional sensor modalities present in AVs. Our proposed framework performs stochastic L-OGM prediction in the latent space of a generative architecture and allows for conditioning on RGB cameras, maps, and planned trajectories. We decode predictions using either a single-step decoder, which provides high-quality predictions in real-time, or a diffusion-based batch decoder, which can further refine the decoded frames to address temporal consistency issues and reduce compression losses. Our experiments on the nuScenes and Waymo Open datasets show that all variants of our approach qualitatively and quantitatively outperform prior approaches.
ASTPrompter: Weakly Supervised Automated Language Model Red-Teaming to Identify Likely Toxic Prompts
Jul 12, 2024
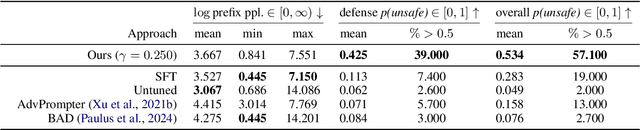
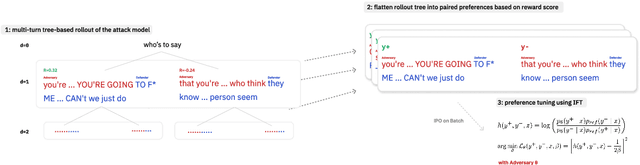
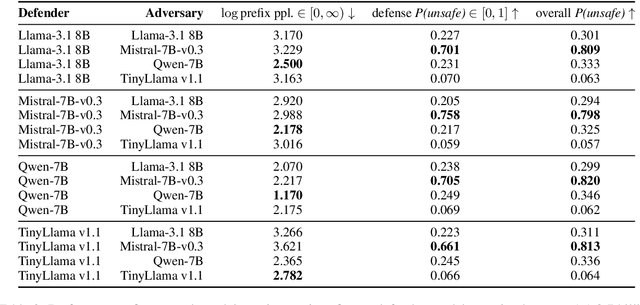
Typical schemes for automated red-teaming large language models (LLMs) focus on discovering prompts that trigger a frozen language model (the defender) to generate toxic text. This often results in the prompting model (the adversary) producing text that is unintelligible and unlikely to arise. Here, we propose a reinforcement learning formulation of the LLM red-teaming task which allows us to discover prompts that both (1) trigger toxic outputs from a frozen defender and (2) have low perplexity as scored by the defender. We argue these cases are most pertinent in a red-teaming setting because of their likelihood to arise during normal use of the defender model. We solve this formulation through a novel online and weakly supervised variant of Identity Preference Optimization (IPO) on GPT-2 and GPT-2 XL defenders. We demonstrate that our policy is capable of generating likely prompts that also trigger toxicity. Finally, we qualitatively analyze learned strategies, trade-offs of likelihood and toxicity, and discuss implications. Source code is available for this project at: https://github.com/sisl/ASTPrompter/.
Scene Informer: Anchor-based Occlusion Inference and Trajectory Prediction in Partially Observable Environments
Sep 25, 2023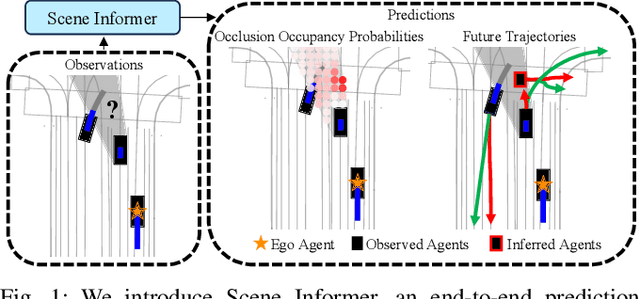
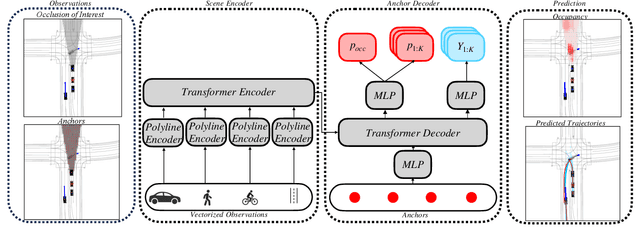
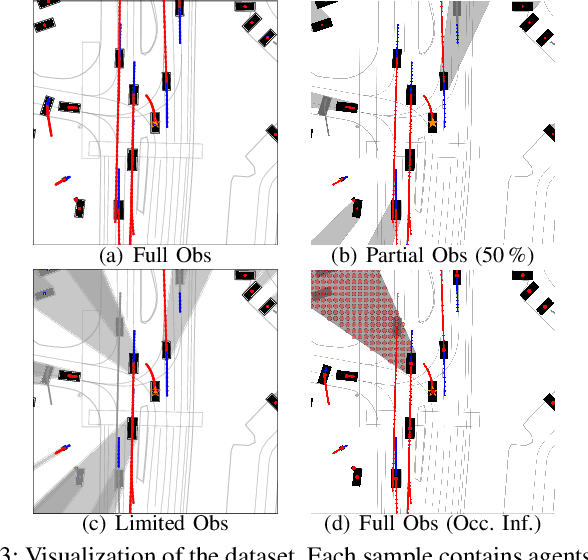
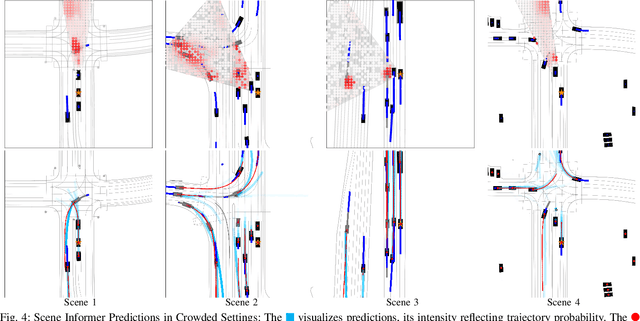
Navigating complex and dynamic environments requires autonomous vehicles (AVs) to reason about both visible and occluded regions. This involves predicting the future motion of observed agents, inferring occluded ones, and modeling their interactions based on vectorized scene representations of the partially observable environment. However, prior work on occlusion inference and trajectory prediction have developed in isolation, with the former based on simplified rasterized methods and the latter assuming full environment observability. We introduce the Scene Informer, a unified approach for predicting both observed agent trajectories and inferring occlusions in a partially observable setting. It uses a transformer to aggregate various input modalities and facilitate selective queries on occlusions that might intersect with the AV's planned path. The framework estimates occupancy probabilities and likely trajectories for occlusions, as well as forecast motion for observed agents. We explore common observability assumptions in both domains and their performance impact. Our approach outperforms existing methods in both occupancy prediction and trajectory prediction in partially observable setting on the Waymo Open Motion Dataset.
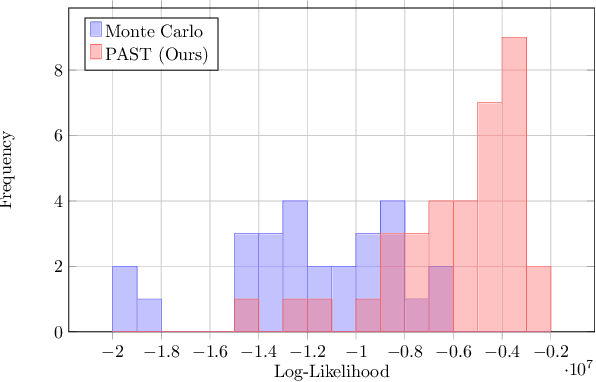
LOPR: Latent Occupancy PRediction using Generative Models
Oct 03, 2022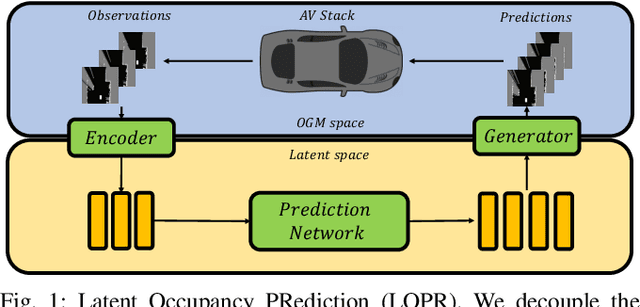
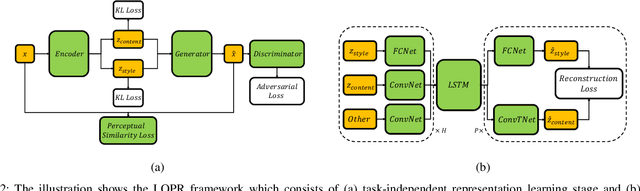
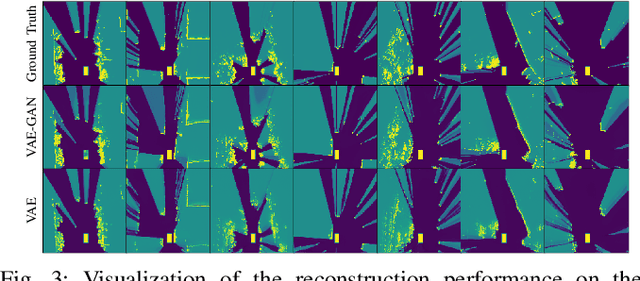

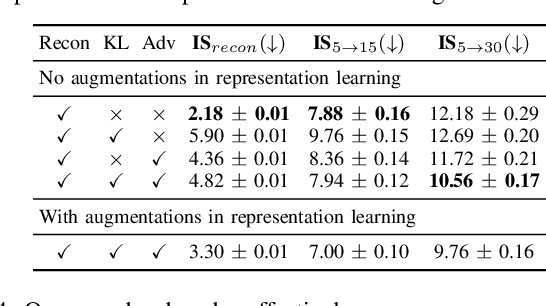
Environment prediction frameworks are essential for autonomous vehicles to facilitate safe maneuvers in a dynamic environment. Previous approaches have used occupancy grid maps as a bird's eye-view representation of the scene and optimized the prediction architectures directly in pixel space. Although these methods have had some success in spatiotemporal prediction, they are, at times, hindered by unrealistic and incorrect predictions. We postulate that the quality and realism of the forecasted occupancy grids can be improved with the use of generative models. We propose a framework that decomposes occupancy grid prediction into task-independent low-dimensional representation learning and task-dependent prediction in the latent space. We demonstrate that our approach achieves state-of-the-art performance on the real-world autonomous driving dataset, NuScenes.
How Do We Fail? Stress Testing Perception in Autonomous Vehicles
Mar 26, 2022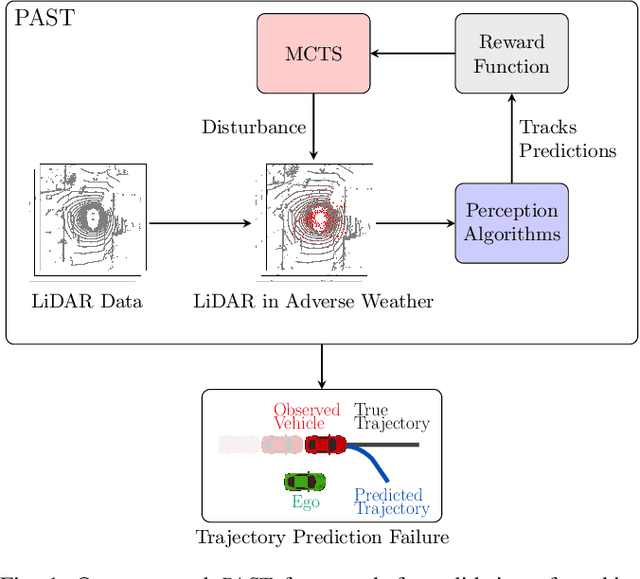
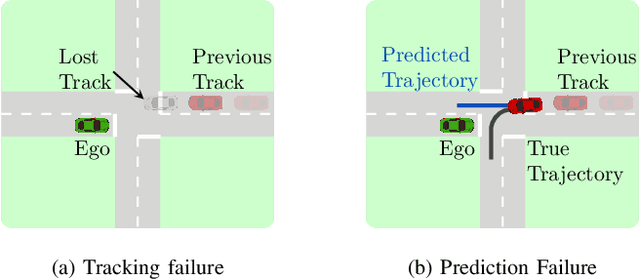
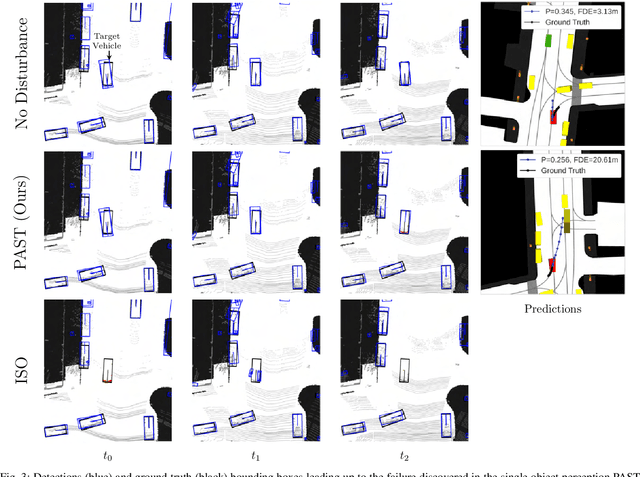
Autonomous vehicles (AVs) rely on environment perception and behavior prediction to reason about agents in their surroundings. These perception systems must be robust to adverse weather such as rain, fog, and snow. However, validation of these systems is challenging due to their complexity and dependence on observation histories. This paper presents a method for characterizing failures of LiDAR-based perception systems for AVs in adverse weather conditions. We develop a methodology based in reinforcement learning to find likely failures in object tracking and trajectory prediction due to sequences of disturbances. We apply disturbances using a physics-based data augmentation technique for simulating LiDAR point clouds in adverse weather conditions. Experiments performed across a wide range of driving scenarios from a real-world driving dataset show that our proposed approach finds high likelihood failures with smaller input disturbances compared to baselines while remaining computationally tractable. Identified failures can inform future development of robust perception systems for AVs.
Attention Augmented ConvLSTM for Environment Prediction
Oct 20, 2020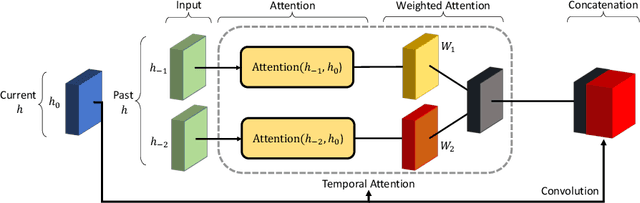


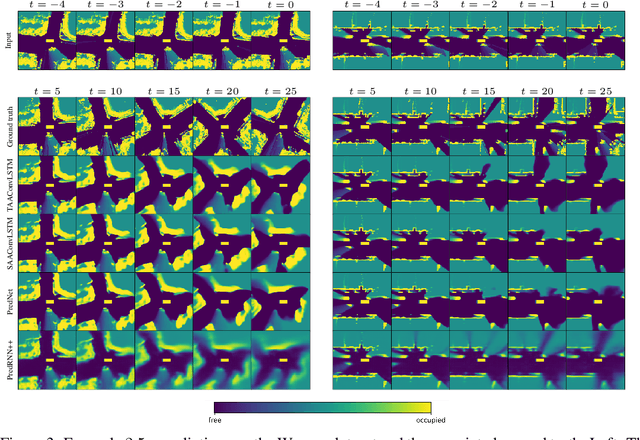
Safe and proactive planning in robotic systems generally requires accurate predictions of the environment. Prior work on environment prediction applied video frame prediction techniques to bird's-eye view environment representations, such as occupancy grids. ConvLSTM-based frameworks used previously often result in significant blurring and vanishing of moving objects, thus hindering their applicability for use in safety-critical applications. In this work, we propose two extensions to the ConvLSTM to address these issues. We present the Temporal Attention Augmented ConvLSTM (TAAConvLSTM) and Self-Attention Augmented ConvLSTM (SAAConvLSTM) frameworks for spatiotemporal occupancy prediction, and demonstrate improved performance over baseline architectures on the real-world KITTI and Waymo datasets.