 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Multi-future Occupancy Forecasting for Autonomous Driving
Paper and Code
Jul 30, 2024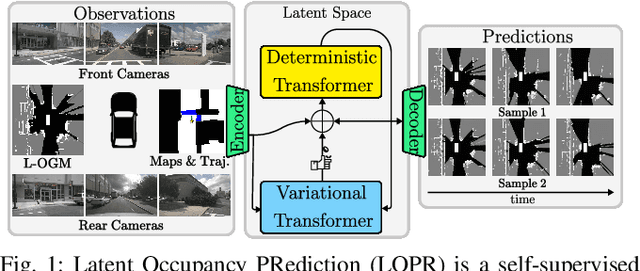

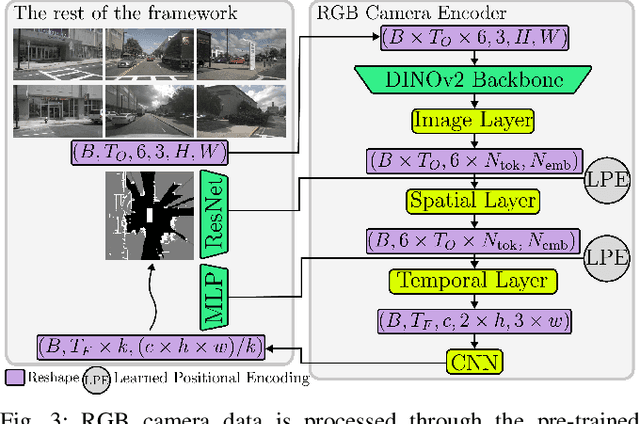
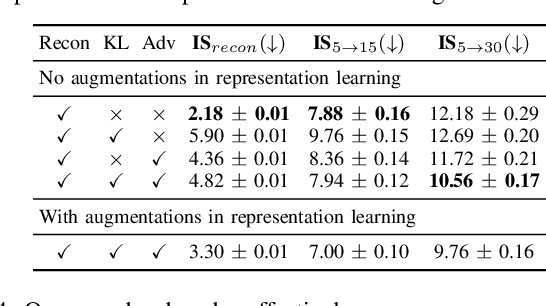
Environment prediction frameworks are critical for the safe navigation of autonomous vehicles (AVs) in dynamic settings. LiDAR-generated occupancy grid maps (L-OGMs) offer a robust bird's-eye view for the scene representation, enabling self-supervised joint scene predictions while exhibiting resilience to partial observability and perception detection failures. Prior approaches have focused on deterministic L-OGM prediction architectures within the grid cell space. While these methods have seen some success, they frequently produce unrealistic predictions and fail to capture the stochastic nature of the environment. Additionally, they do not effectively integrate additional sensor modalities present in AVs. Our proposed framework performs stochastic L-OGM prediction in the latent space of a generative architecture and allows for conditioning on RGB cameras, maps, and planned trajectories. We decode predictions using either a single-step decoder, which provides high-quality predictions in real-time, or a diffusion-based batch decoder, which can further refine the decoded frames to address temporal consistency issues and reduce compression losses. Our experiments on the nuScenes and Waymo Open datasets show that all variants of our approach qualitatively and quantitatively outperform prior approaches.