 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTPrompter: Weakly Supervised Automated Language Model Red-Teaming to Identify Likely Toxic Prompts
Jul 12, 2024
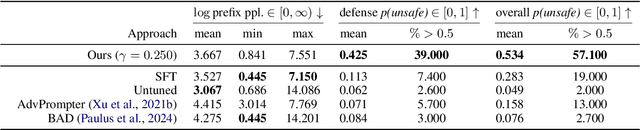
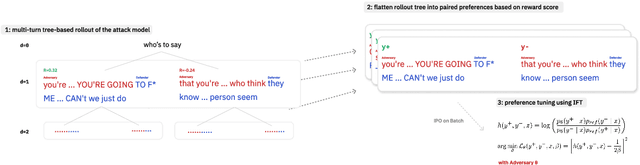
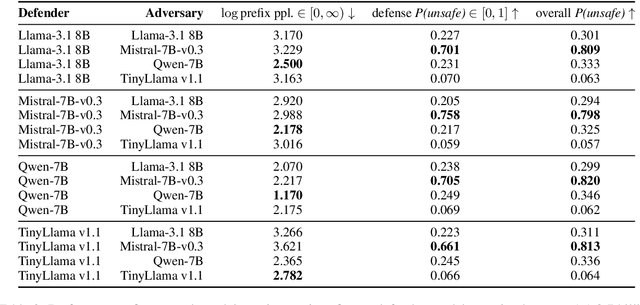
Typical schemes for automated red-teaming large language models (LLMs) focus on discovering prompts that trigger a frozen language model (the defender) to generate toxic text. This often results in the prompting model (the adversary) producing text that is unintelligible and unlikely to arise. Here, we propose a reinforcement learning formulation of the LLM red-teaming task which allows us to discover prompts that both (1) trigger toxic outputs from a frozen defender and (2) have low perplexity as scored by the defender. We argue these cases are most pertinent in a red-teaming setting because of their likelihood to arise during normal use of the defender model. We solve this formulation through a novel online and weakly supervised variant of Identity Preference Optimization (IPO) on GPT-2 and GPT-2 XL defenders. We demonstrate that our policy is capable of generating likely prompts that also trigger toxicity. Finally, we qualitatively analyze learned strategies, trade-offs of likelihood and toxicity, and discuss implications. Source code is available for this project at: https://github.com/sisl/ASTPrompter/.