 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Augmented ConvLSTM for Environment Prediction
Paper and Code
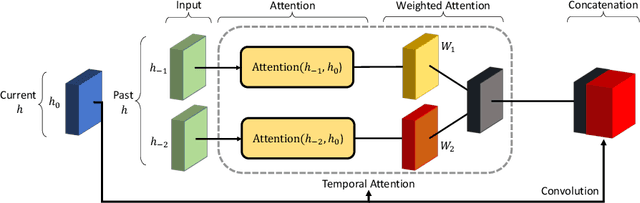


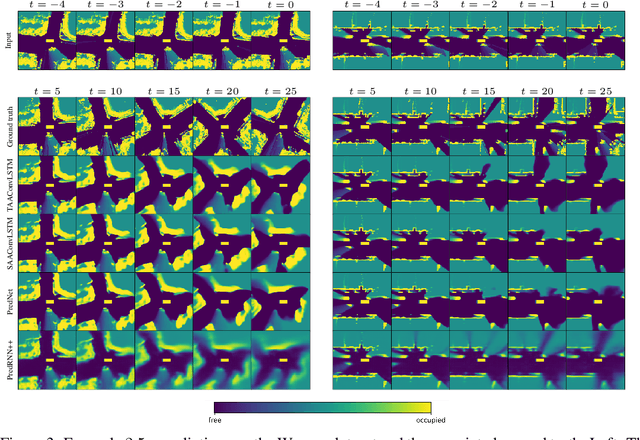
Safe and proactive planning in robotic systems generally requires accurate predictions of the environment. Prior work on environment prediction applied video frame prediction techniques to bird's-eye view environment representations, such as occupancy grids. ConvLSTM-based frameworks used previously often result in significant blurring and vanishing of moving objects, thus hindering their applicability for use in safety-critical applications. In this work, we propose two extensions to the ConvLSTM to address these issues. We present the Temporal Attention Augmented ConvLSTM (TAAConvLSTM) and Self-Attention Augmented ConvLSTM (SAAConvLSTM) frameworks for spatiotemporal occupancy prediction, and demonstrate improved performance over baseline architectures on the real-world KITTI and Waymo datasets.