 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Intervene: Detecting Abnormal Mood using Everyday Smartphone Conversations
Oct 03, 2019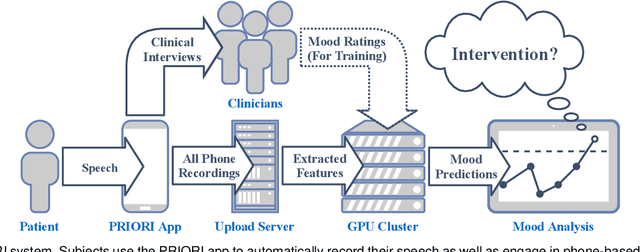
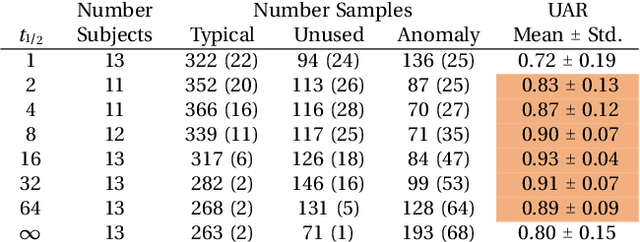
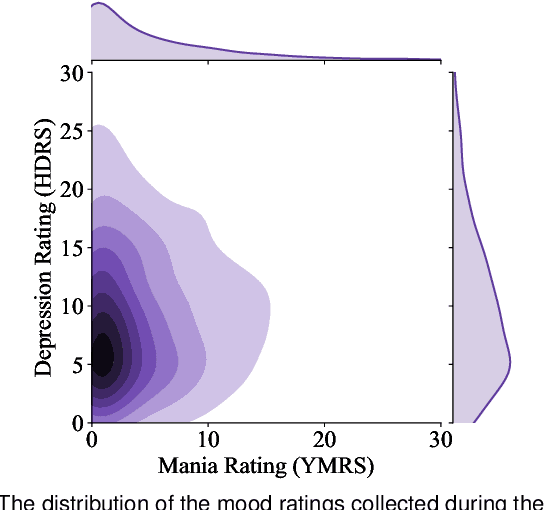

Bipolar disorder (BPD) is a chronic mental illness characterized by extreme mood and energy changes from mania to depression. These changes drive behaviors that often lead to devastating personal or social consequences. BPD is managed clinically with regular interactions with care providers, who assess mood, energy levels, and the form and content of speech. Recent work has proposed smartphones for monitoring mood using speech. However, these works do not predict when to intervene. Predicting when to intervene is challenging because there is not a single measure that is relevant for every person: different individuals may have different levels of symptom severity considered typical. Additionally, this typical mood, or baseline, may change over time, making a single symptom threshold insufficient. This work presents an innovative approach that expands clinical mood monitoring to predict when interventions are necessary using an anomaly detection framework, which we call Temporal Normalization. We first validate the model using a dataset annotated for clinical interventions and then incorporate this method in a deep learning framework to predict mood anomalies from natural, unstructured, telephone speech data. The combination of these approaches provides a framework to enable real-world speech-focused mood monitoring.
Jointly Aligning and Predicting Continuous Emotion Annotations
Jul 18, 2019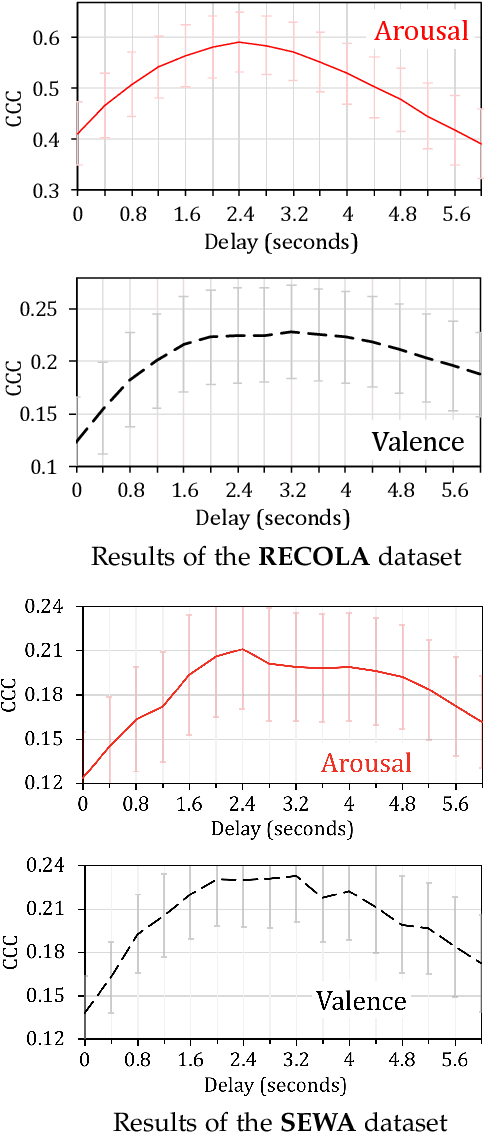
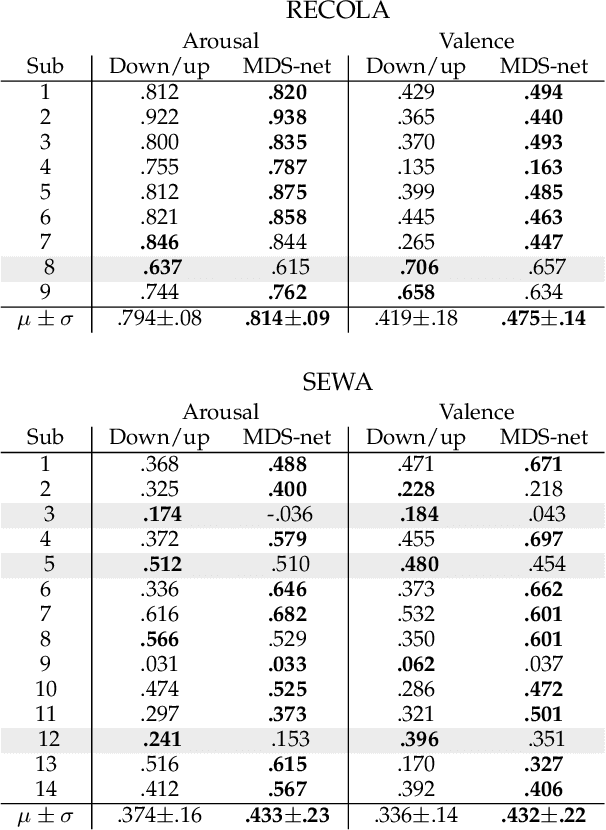
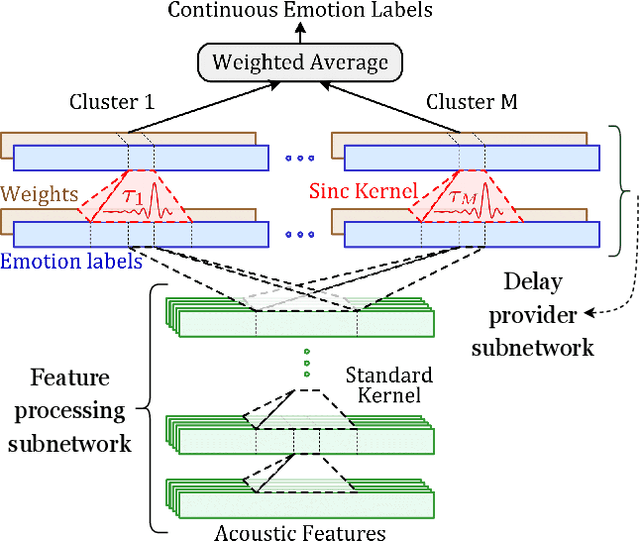
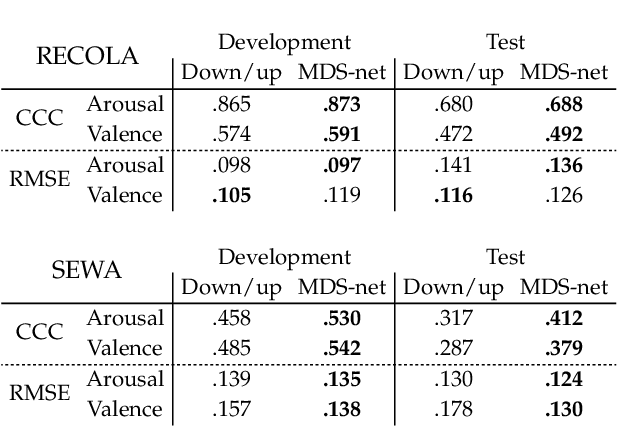
Time-continuous dimensional descriptions of emotions (e.g., arousal, valence) allow researchers to characterize short-time changes and to capture long-term trends in emotion expression. However, continuous emotion labels are generally not synchronized with the input speech signal due to delays caused by reaction-time, which is inherent in human evaluations. To deal with this challenge, we introduce a new convolutional neural network (multi-delay sinc network) that is able to simultaneously align and predict labels in an end-to-end manner. The proposed network is a stack of convolutional layers followed by an aligner network that aligns the speech signal and emotion labels. This network is implemented using a new convolutional layer that we introduce, the delayed sinc layer. It is a time-shifted low-pass (sinc) filter that uses a gradient-based algorithm to learn a single delay. Multiple delayed sinc layers can be used to compensate for a non-stationary delay that is a function of the acoustic space. We test the efficacy of this system on two common emotion datasets, RECOLA and SEWA, and show that this approach obtains state-of-the-art speech-only results by learning time-varying delays while predicting dimensional descriptors of emotions.
Barking up the Right Tree: Improving Cross-Corpus Speech Emotion Recognition with Adversarial Discriminative Domain Generalization
Mar 28, 2019
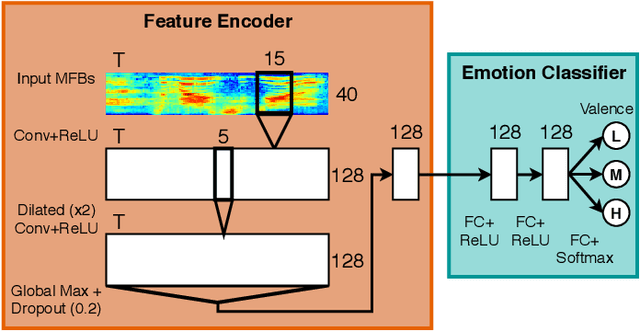
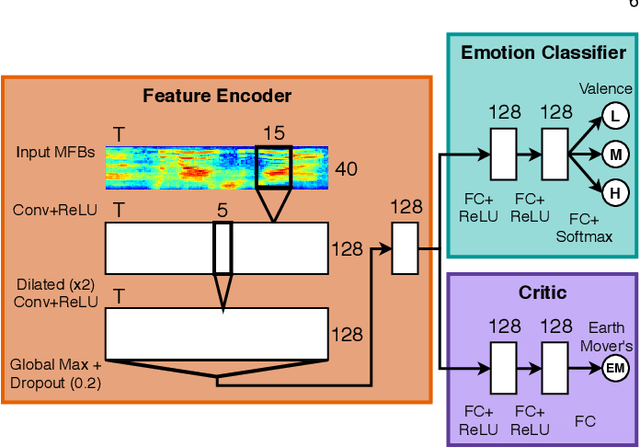
Automatic speech emotion recognition provides computers with critical context to enable user understanding. While methods trained and tested within the same dataset have been shown successful, they often fail when applied to unseen datasets. To address this, recent work has focused on adversarial methods to find more generalized representations of emotional speech. However, many of these methods have issues converging, and only involve datasets collected in laboratory conditions. In this paper, we introduce Adversarial Discriminative Domain Generalization (ADDoG), which follows an easier to train "meet in the middle" approach. The model iteratively moves representations learned for each dataset closer to one another, improving cross-dataset generalization. We also introduce Multiclass ADDoG, or MADDoG, which is able to extend the proposed method to more than two datasets, simultaneously. Our results show consistent convergence for the introduced methods, with significantly improved results when not using labels from the target dataset. We also show how, in most cases, ADDoG and MADDoG can be used to improve upon baseline state-of-the-art methods when target dataset labels are added and in-the-wild data are considered. Even though our experiments focus on cross-corpus speech emotion, these methods could be used to remove unwanted factors of variation in other settings.
Trainable Time Warping: Aligning Time-Series in the Continuous-Time Domain
Mar 21, 2019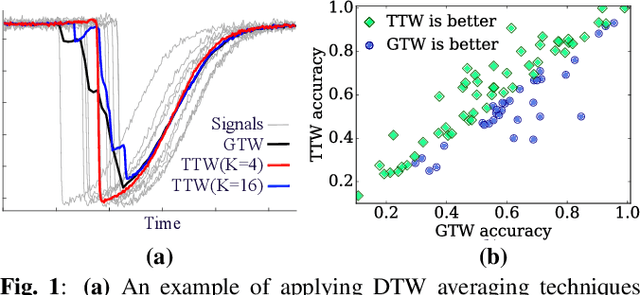
DTW calculates the similarity or alignment between two signals, subject to temporal warping. However, its computational complexity grows exponentially with the number of time-series. Although there have been algorithms developed that are linear in the number of time-series, they are generally quadratic in time-series length. The exception is generalized time warping (GTW), which has linear computational cost. Yet, it can only identify simple time warping functions. There is a need for a new fast, high-quality multisequence alignment algorithm. We introduce trainable time warping (TTW), whose complexity is linear in both the number and the length of time-series. TTW performs alignment in the continuous-time domain using a sinc convolutional kernel and a gradient-based optimization technique. We compare TTW and GTW on 85 UCR datasets in time-series averaging and classification. TTW outperforms GTW on 67.1% of the datasets for the averaging tasks, and 61.2% of the datasets for the classification tasks.