 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarking up the Right Tree: Improving Cross-Corpus Speech Emotion Recognition with Adversarial Discriminative Domain Generalization
Paper and Code
Mar 28, 2019
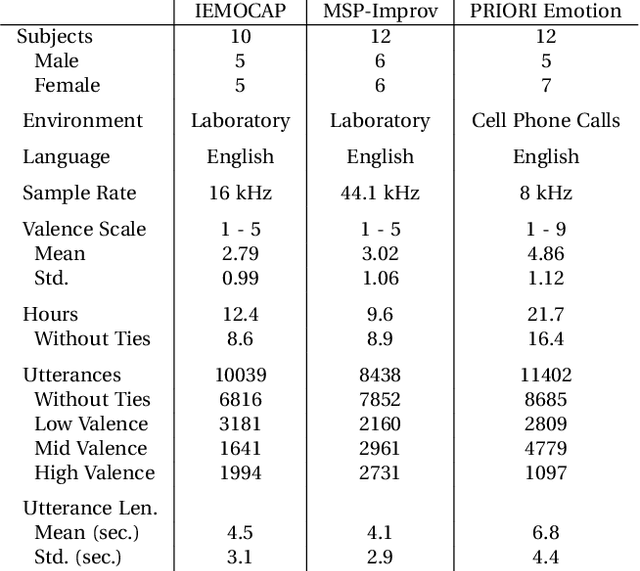
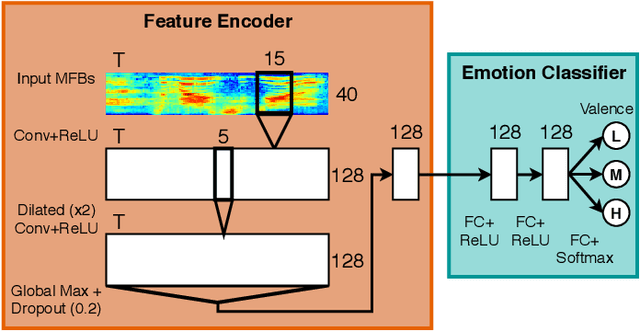
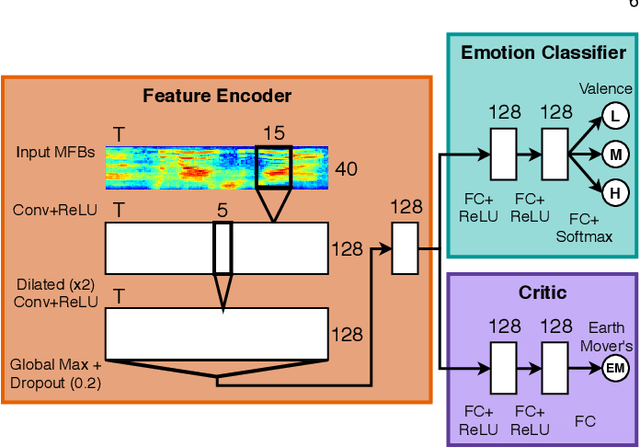
Automatic speech emotion recognition provides computers with critical context to enable user understanding. While methods trained and tested within the same dataset have been shown successful, they often fail when applied to unseen datasets. To address this, recent work has focused on adversarial methods to find more generalized representations of emotional speech. However, many of these methods have issues converging, and only involve datasets collected in laboratory conditions. In this paper, we introduce Adversarial Discriminative Domain Generalization (ADDoG), which follows an easier to train "meet in the middle" approach. The model iteratively moves representations learned for each dataset closer to one another, improving cross-dataset generalization. We also introduce Multiclass ADDoG, or MADDoG, which is able to extend the proposed method to more than two datasets, simultaneously. Our results show consistent convergence for the introduced methods, with significantly improved results when not using labels from the target dataset. We also show how, in most cases, ADDoG and MADDoG can be used to improve upon baseline state-of-the-art methods when target dataset labels are added and in-the-wild data are considered. Even though our experiments focus on cross-corpus speech emotion, these methods could be used to remove unwanted factors of variation in other settings.