 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Multimodal Fusion for Driver Behavior Prediction Tasks using Gated Recurrent Fusion Units
Oct 01, 2019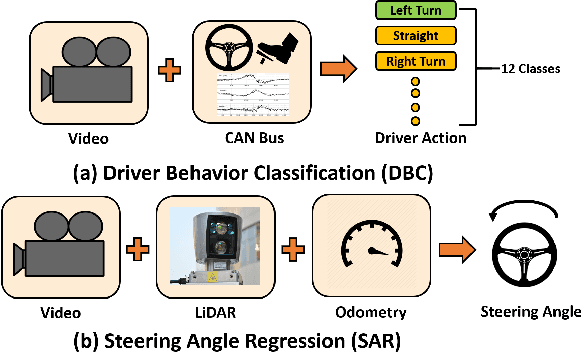
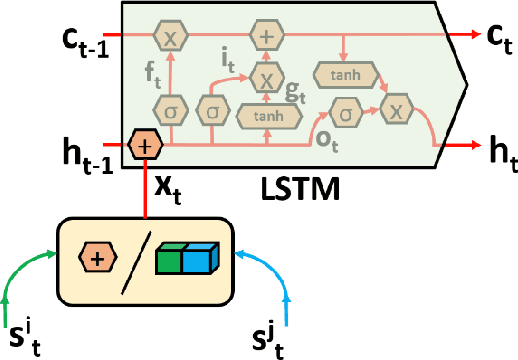

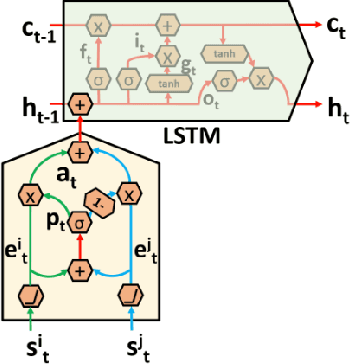
The Tactical Driver Behavior modeling problem requires understanding of driver actions in complicated urban scenarios from a rich multi modal signals including video, LiDAR and CAN bus data streams. However, the majority of deep learning research is focused either on learning the vehicle/environment state (sensor fusion) or the driver policy (from temporal data), but not both. Learning both tasks end-to-end offers the richest distillation of knowledge, but presents challenges in formulation and successful training. In this work, we propose promising first steps in this direction. Inspired by the gating mechanisms in LSTM, we propose gated recurrent fusion units (GRFU) that learn fusion weighting and temporal weighting simultaneously. We demonstrate it's superior performance over multimodal and temporal baselines in supervised regression and classification tasks, all in the realm of autonomous navigation. We note a 10% improvement in the mAP score over state-of-the-art for tactical driver behavior classification in HDD dataset and a 20% drop in overall Mean squared error for steering action regression on TORCS dataset.
Deep Visual Perception for Dynamic Walking on Discrete Terrain
Dec 04, 2017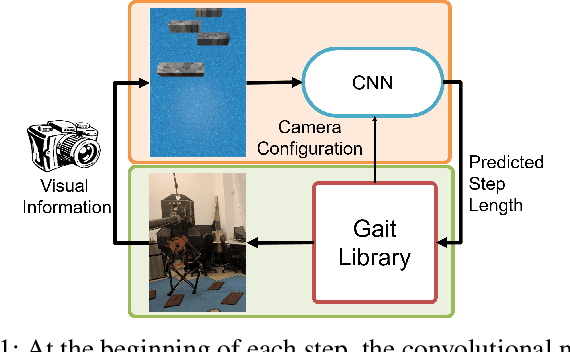
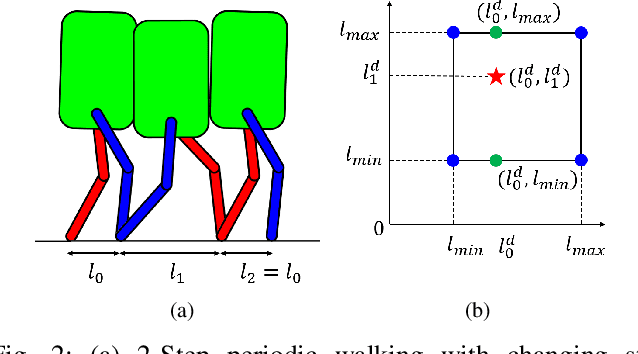


Dynamic bipedal walking on discrete terrain, like stepping stones, is a challenging problem requiring feedback controllers to enforce safety-critical constraints. To enforce such constraints in real-world experiments, fast and accurate perception for foothold detection and estimation is needed. In this work, a deep visual perception model is designed to accurately estimate step length of the next step, which serves as input to the feedback controller to enable vision-in-the-loop dynamic walking on discrete terrain. In particular, a custom convolutional neural network architecture is designed and trained to predict step length to the next foothold using a sampled image preview of the upcoming terrain at foot impact. The visual input is offered only at the beginning of each step and is shown to be sufficient for the job of dynamically stepping onto discrete footholds. Through extensive numerical studies, we show that the robot is able to successfully autonomously walk for over 100 steps without failure on a discrete terrain with footholds randomly positioned within a step length range of 45-85 centimeters.
Learning End-to-end Multimodal Sensor Policies for Autonomous Navigation
Nov 01, 2017
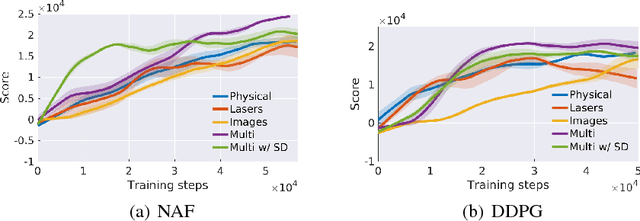


Multisensory polices are known to enhance both state estimation and target tracking. However, in the space of end-to-end sensorimotor control, this multi-sensor outlook has received limited attention. Moreover, systematic ways to make policies robust to partial sensor failure are not well explored. In this work, we propose a specific customization of Dropout, called \textit{Sensor Dropout}, to improve multisensory policy robustness and handle partial failure in the sensor-set. We also introduce an additional auxiliary loss on the policy network in order to reduce variance in the band of potential multi- and uni-sensory policies to reduce jerks during policy switching triggered by an abrupt sensor failure or deactivation/activation. Finally, through the visualization of gradients, we show that the learned policies are conditioned on the same latent states representation despite having diverse observations spaces - a hallmark of true sensor-fusion. Simulation results of the multisensory policy, as visualized in TORCS racing game, can be seen here: https://youtu.be/QAK2lcXjNZc.