 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning End-to-end Multimodal Sensor Policies for Autonomous Navigation
Paper and Code
Nov 01, 2017
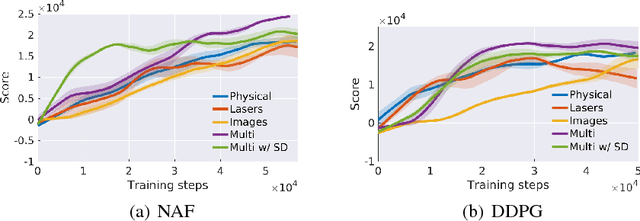


Multisensory polices are known to enhance both state estimation and target tracking. However, in the space of end-to-end sensorimotor control, this multi-sensor outlook has received limited attention. Moreover, systematic ways to make policies robust to partial sensor failure are not well explored. In this work, we propose a specific customization of Dropout, called \textit{Sensor Dropout}, to improve multisensory policy robustness and handle partial failure in the sensor-set. We also introduce an additional auxiliary loss on the policy network in order to reduce variance in the band of potential multi- and uni-sensory policies to reduce jerks during policy switching triggered by an abrupt sensor failure or deactivation/activation. Finally, through the visualization of gradients, we show that the learned policies are conditioned on the same latent states representation despite having diverse observations spaces - a hallmark of true sensor-fusion. Simulation results of the multisensory policy, as visualized in TORCS racing game, can be seen here: https://youtu.be/QAK2lcXjNZc.