 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Contour-Guided 3D Face Reconstruction with Occlusions
Mar 16, 2025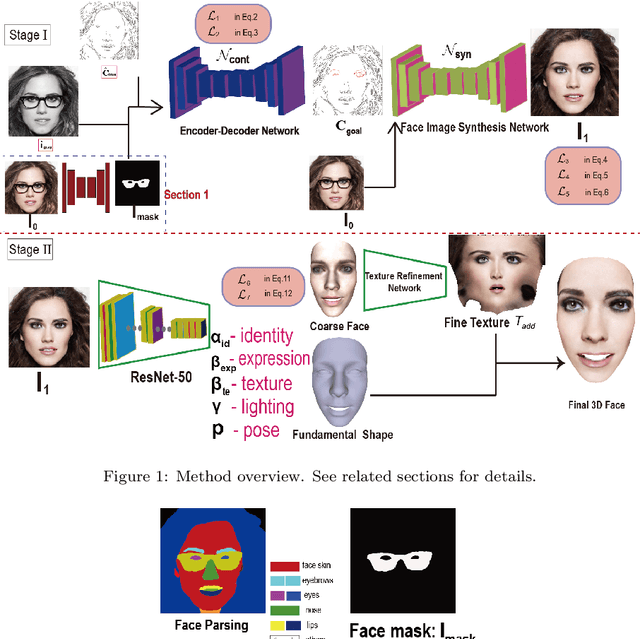

Recently, deep learning-based 3D face reconstruction methods have demonstrated promising advancements in terms of quality and efficiency. Nevertheless, these techniques face challenges in effectively handling occluded scenes and fail to capture intricate geometric facial details. Inspired by the principles of GANs and bump mapping, we have successfully addressed these issues. Our approach aims to deliver comprehensive 3D facial reconstructions, even in the presence of occlusions.While maintaining the overall shape's robustness, we introduce a mid-level shape refinement to the fundamental structure. Furthermore, we illustrate how our method adeptly extends to generate plausible details for obscured facial regions. We offer numerous examples that showcase the effectiveness of our framework in producing realistic results, where traditional methods often struggle. To substantiate the superior adaptability of our approach, we have conducted extensive experiments in the context of general 3D face reconstruction tasks, serving as concrete evidence of its regulatory prowess compared to manual occlusion removal methods.
Geometry-Aware Face Reconstruction Under Occluded Scenes
Mar 16, 2025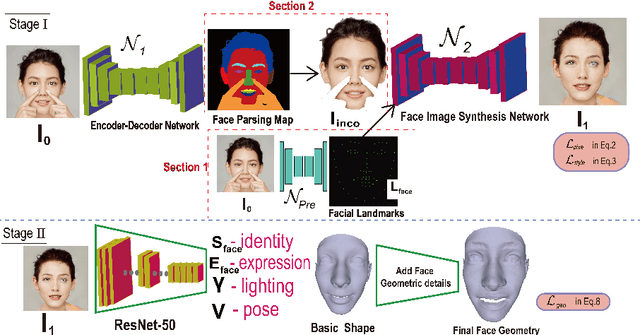


Recently, deep learning-based 3D face reconstruction methods have demonstrated promising advancements in terms of quality and efficiency. Nevertheless, these techniques face challenges in effectively handling occluded scenes and fail to capture intricate geometric facial details. Inspired by the principles of GANs and bump mapping, we have successfully addressed these issues. Our approach aims to deliver comprehensive 3D facial reconstructions, even in the presence of occlusions.While maintaining the overall shape's robustness, we introduce a mid-level shape refinement to the fundamental structure. Furthermore, we illustrate how our method adeptly extends to generate plausible details for obscured facial regions. We offer numerous examples that showcase the effectiveness of our framework in producing realistic results, where traditional methods often struggle. To substantiate the superior adaptability of our approach, we have conducted extensive experiments in the context of general 3D face reconstruction tasks, serving as concrete evidence of its regulatory prowess compared to manual occlusion removal methods.
Generative Landmarks Guided Eyeglasses Removal 3D Face Reconstruction
Dec 25, 2024



Single-view 3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the input is unobstructed faces which makes their method not suitable for in-the-wild conditions. We present a method for performing a 3D face that removes eyeglasses from a single image. Existing facial reconstruction methods fail to remove eyeglasses automatically for generating a photo-realistic 3D face "in-the-wild".The innovation of our method lies in a process for identifying the eyeglasses area robustly and remove it intelligently. In this work, we estimate the 2D face structure of the reasonable position of the eyeglasses area, which is used for the construction of 3D texture. An excellent anti-eyeglasses face reconstruction method should ensure the authenticity of the output, including the topological structure between the eyes, nose, and mouth. We achieve this via a deep learning architecture that performs direct regression of a 3DMM representation of the 3D facial geometry from a single 2D image. We also demonstrate how the related face parsing task can be incorporated into the proposed framework and help improve reconstruction quality. We conduct extensive experiments on existing 3D face reconstruction tasks as concrete examples to demonstrate the method's superior regulation ability over existing methods often break down.
Generative Face Parsing Map Guided 3D Face Reconstruction Under Occluded Scenes
Dec 25, 2024Over the past few years, single-view 3D face reconstruction methods can produce beautiful 3D models. Nevertheless,the input of these works is unobstructed faces.We describe a system designed to reconstruct convincing face texture in the case of occlusion.Motivated by parsing facial features,we propose a complete face parsing map generation method guided by landmarks.We estimate the 2D face structure of the reasonable position of the occlusion area,which is used for the construction of 3D texture.An excellent anti-occlusion face reconstruction method should ensure the authenticity of the output,including the topological structure between the eyes,nose, and mouth. We extensively tested our method and its components, qualitatively demonstrating the rationality of our estimated facial structure. We conduct extensive experiments on general 3D face reconstruction tasks as concrete examples to demonstrate the method's superior regulation ability over existing methods often break down.We further provide numerous quantitative examples showing that our method advances both the quality and the robustness of 3D face reconstruction under occlusion scenes.
Predicting Human Trajectories by Learning and Matching Patterns
May 20, 2021
Thesis document of the degree of Master of Science in Robotics of Carnegie Mellon University School of Computer Science.
Core Challenges of Social Robot Navigation: A Survey
Mar 17, 2021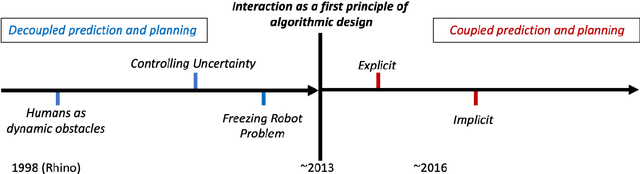



Robot navigation in crowded public spaces is a complex task that requires addressing a variety of engineering and human factors challenges. These challenges have motivated a great amount of research resulting in important developments for the fields of robotics and human-robot interaction over the past three decades. Despite the significant progress and the massive recent interest, we observe a number of significant remaining challenges that prohibit the seamless deployment of autonomous robots in public pedestrian environments. In this survey article, we organize existing challenges into a set of categories related to broader open problems in motion planning, behavior design, and evaluation methodologies. Within these categories, we review past work, and offer directions for future research. Our work builds upon and extends earlier survey efforts by a) taking a critical perspective and diagnosing fundamental limitations of adopted practices in the field and b) offering constructive feedback and ideas that we aspire will drive research in the field over the coming decade.
Noticing Motion Patterns: Temporal CNN with a Novel Convolution Operator for Human Trajectory Prediction
Jul 02, 2020



We propose a novel way to learn, detect and extract patterns in sequential data, and successfully applied it to the problem of human trajectory prediction. Our model, Social Pattern Extraction Convolution (Social-PEC), when compared to existing methods, achieves the best performance in terms of Average/Final Displacement Error. In addition, the proposed approach avoids the obscurity in the previous use of pooling layer, presenting intuitive and explainable decision making processes.
A real-time multi-constraints obstacle avoidance method based on LiDAR
May 30, 2020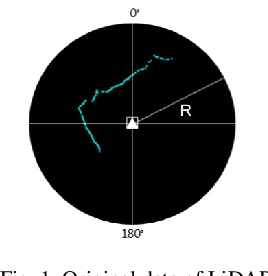



Obstacle avoidance is one of the essential and indispensable functions for autonomous mobile robots. Most of the existing solutions are typically based on single condition constraint and cannot incorporate sensor data in a real-time manner, which often fail to respond to unexpected moving obstacles in dynamic unknown environments. In this paper, a novel real-time multi-constraints obstacle avoidance method based on Light Detection and Ranging(LiDAR) is proposed, which is able to, based on the latest estimation of the robot pose and environment, find the sub-goal defined by a multi-constraints function within the explored region and plan a corresponding optimal trajectory at each time step iteratively, so that the robot approaches the goal over time. Meanwhile, at each time step, the improved Ant Colony Optimization(ACO) algorithm is also used to re-plan optimal paths from the latest robot pose to the latest defined sub-goal position. While ensuring convergence, planning in this method is done by repeated local optimizations, so that the latest sensor data from LiDAR and derived environment information can be fully utilized at each step until the robot reaches the desired position. This method facilitates real-time performance, also has little requirement on memory space or computational power due to its nature, thus our method has huge potentials to benefit small low-cost autonomous platforms. The method is evaluated against several existing technologies in both simulation and real-world experiments.
High Precision In-Pipe Robot Localization with Reciprocal Sensor Fusion
Feb 27, 2020
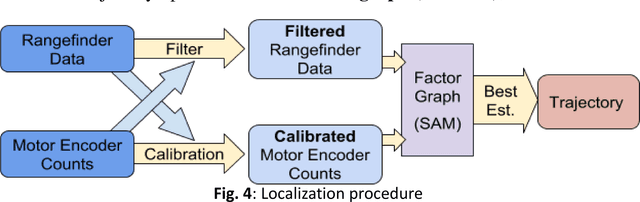
The huge advantage of in-pipe robots is that they are able to measure from inside the pipes, and to sense the geometry, appearance and radiometry directly. The downside is the inability to know precise, absolute position of the measurements in very long pipe runs. This paper develops the unprecedented localization required for this purpose.
* 12 pages, "Superior Paper Award" on WM Symposia 2019