 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand-Priming in Object Localization for Assistive Egocentric Vision
Paper and Code
Feb 28, 2020
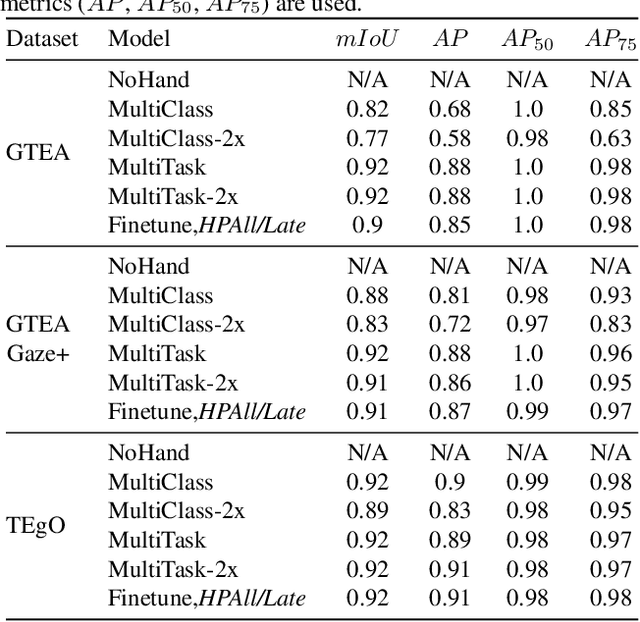
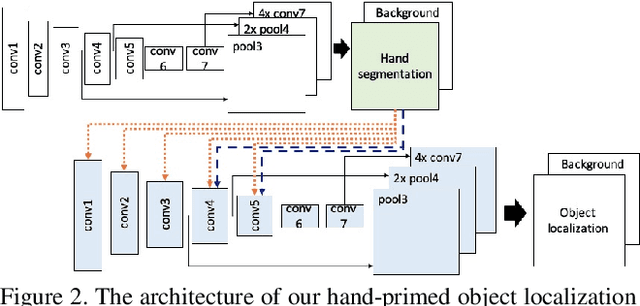
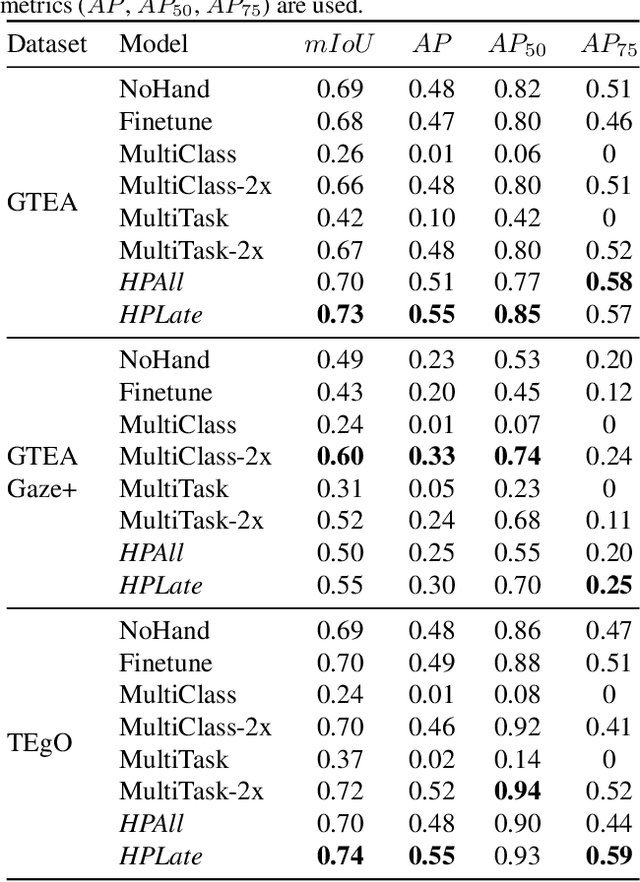
Egocentric vision holds great promises for increasing access to visual information and improving the quality of life for people with visual impairments, with object recognition being one of the daily challenges for this population. While we strive to improve recognition performance, it remains difficult to identify which object is of interest to the user; the object may not even be included in the frame due to challenges in camera aiming without visual feedback. Also, gaze information, commonly used to infer the area of interest in egocentric vision, is often not dependable. However, blind users often tend to include their hand either interacting with the object that they wish to recognize or simply placing it in proximity for better camera aiming. We propose localization models that leverage the presence of the hand as the contextual information for priming the center area of the object of interest. In our approach, hand segmentation is fed to either the entire localization network or its last convolutional layers. Using egocentric datasets from sighted and blind individuals, we show that the hand-priming achieves higher precision than other approaches, such as fine-tuning, multi-class, and multi-task learning, which also encode hand-object interactions in localization.