 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Efficient Visual Abstractions for Autonomous Driving
May 20, 2020
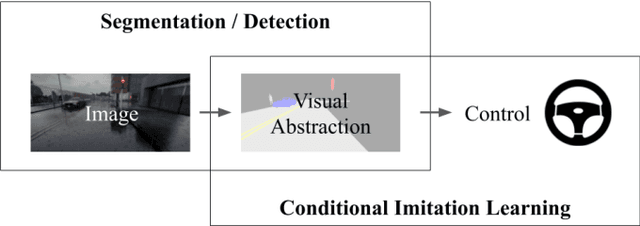
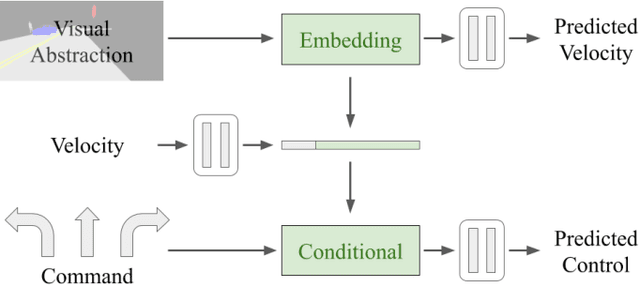
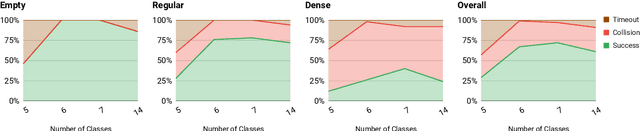
It is well known that semantic segmentation can be used as an effective intermediate representation for learning driving policies. However, the task of street scene semantic segmentation requires expensive annotations. Furthermore, segmentation algorithms are often trained irrespective of the actual driving task, using auxiliary image-space loss functions which are not guaranteed to maximize driving metrics such as safety or distance traveled per intervention. In this work, we seek to quantify the impact of reducing segmentation annotation costs on learned behavior cloning agents. We analyze several segmentation-based intermediate representations. We use these visual abstractions to systematically study the trade-off between annotation efficiency and driving performance, i.e., the types of classes labeled, the number of image samples used to learn the visual abstraction model, and their granularity (e.g., object masks vs. 2D bounding boxes). Our analysis uncovers several practical insights into how segmentation-based visual abstractions can be exploited in a more label efficient manner. Surprisingly, we find that state-of-the-art driving performance can be achieved with orders of magnitude reduction in annotation cost. Beyond label efficiency, we find several additional training benefits when leveraging visual abstractions, such as a significant reduction in the variance of the learned policy when compared to state-of-the-art end-to-end driving models.
PointFlowNet: Learning Representations for 3D Scene Flow Estimation from Point Clouds
Sep 17, 2018



Despite significant progress in image-based 3D scene flow estimation, the performance of such approaches has not yet reached the fidelity required by many applications. Simultaneously, these applications are often not restricted to image-based estimation: laser scanners provide a popular alternative to traditional cameras, for example in the context of self-driving cars, as they directly yield a 3D point cloud. In this paper, we propose to estimate 3D scene flow from such unstructured point clouds using a deep neural network. In a single forward pass, our model jointly predicts 3D scene flow as well as the 3D bounding box and rigid body motion of objects in the scene. While the prospect of estimating 3D scene flow from unstructured point clouds is promising, it is also a challenging task. We show that the traditional global representation of rigid body motion prohibits inference by CNNs, and propose a translation equivariant representation to circumvent this problem. For training our deep network, a large dataset is required. Because of this, we augment real scans from KITTI with virtual objects, realistically modeling occlusions and simulating sensor noise. A thorough comparison with classic and learning-based techniques highlights the robustness of the proposed approach.
Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art
Apr 18, 2017
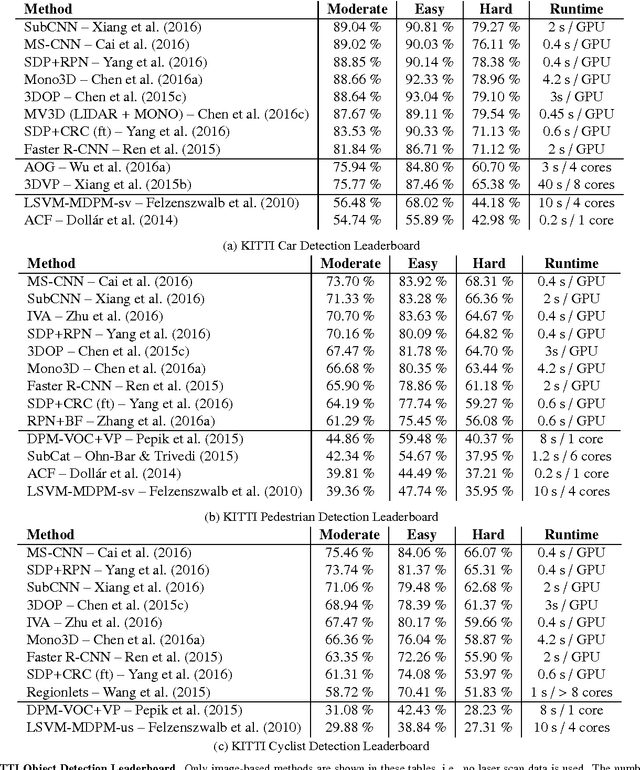

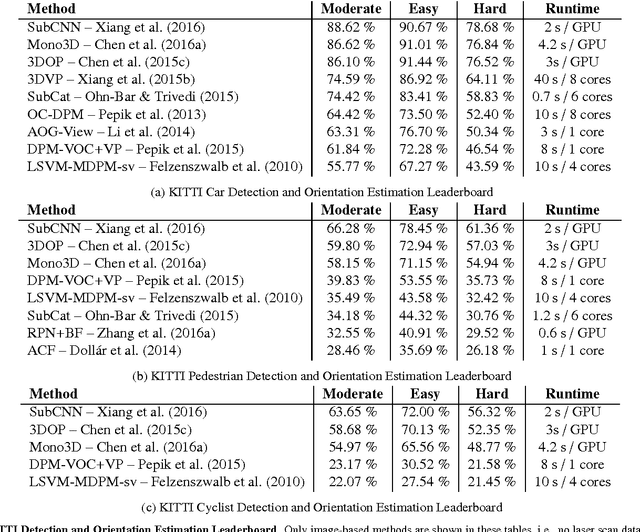
Recent years have witnessed amazing progress in AI related fields such as computer vision, machine learning and autonomous vehicles. As with any rapidly growing field, however, it becomes increasingly difficult to stay up-to-date or enter the field as a beginner. While several topic specific survey papers have been written, to date no general survey on problems, datasets and methods in computer vision for autonomous vehicles exists. This paper attempts to narrow this gap by providing a state-of-the-art survey on this topic. Our survey includes both the historically most relevant literature as well as the current state-of-the-art on several specific topics, including recognition, reconstruction, motion estimation, tracking, scene understanding and end-to-end learning. Towards this goal, we first provide a taxonomy to classify each approach and then analyze the performance of the state-of-the-art on several challenging benchmarking datasets including KITTI, ISPRS, MOT and Cityscapes. Besides, we discuss open problems and current research challenges. To ease accessibility and accommodate missing references, we will also provide an interactive platform which allows to navigate topics and methods, and provides additional information and project links for each paper.