 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseLaneSTP: Leveraging Spatio-Temporal Priors with Sparse Transformers for 3D Lane Detection
Jan 08, 20263D lane detection has emerged as a critical challenge in autonomous driving, encompassing identification and localization of lane markings and the 3D road surface. Conventional 3D methods detect lanes from dense birds-eye-viewed (BEV) features, though erroneous transformations often result in a poor feature representation misaligned with the true 3D road surface. While recent sparse lane detectors have surpassed dense BEV approaches, they completely disregard valuable lane-specific priors. Furthermore, existing methods fail to utilize historic lane observations, which yield the potential to resolve ambiguities in situations of poor visibility. To address these challenges, we present SparseLaneSTP, a novel method that integrates both geometric properties of the lane structure and temporal information into a sparse lane transformer. It introduces a new lane-specific spatio-temporal attention mechanism, a continuous lane representation tailored for sparse architectures as well as temporal regularization. Identifying weaknesses of existing 3D lane datasets, we also introduce a precise and consistent 3D lane dataset using a simple yet effective auto-labeling strategy. Our experimental section proves the benefits of our contributions and demonstrates state-of-the-art performance across all detection and error metrics on existing 3D lane detection benchmarks as well as on our novel dataset.
LaneCPP: Continuous 3D Lane Detection using Physical Priors
Jun 12, 2024

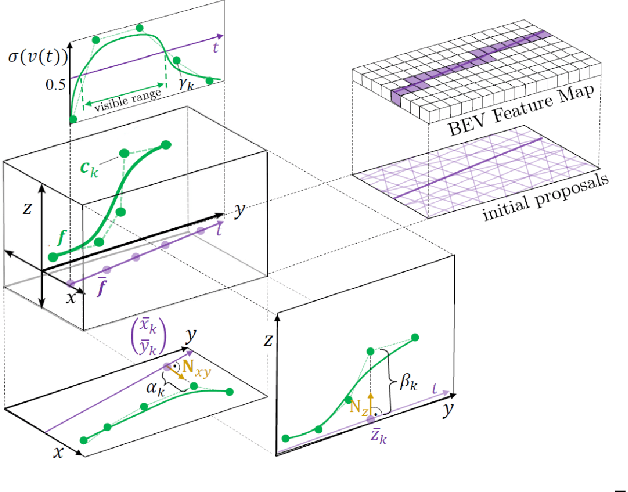

Monocular 3D lane detection has become a fundamental problem in the context of autonomous driving, which comprises the tasks of finding the road surface and locating lane markings. One major challenge lies in a flexible but robust line representation capable of modeling complex lane structures, while still avoiding unpredictable behavior. While previous methods rely on fully data-driven approaches, we instead introduce a novel approach LaneCPP that uses a continuous 3D lane detection model leveraging physical prior knowledge about the lane structure and road geometry. While our sophisticated lane model is capable of modeling complex road structures, it also shows robust behavior since physical constraints are incorporated by means of a regularization scheme that can be analytically applied to our parametric representation. Moreover, we incorporate prior knowledge about the road geometry into the 3D feature space by modeling geometry-aware spatial features, guiding the network to learn an internal road surface representation. In our experiments, we show the benefits of our contributions and prove the meaningfulness of using priors to make 3D lane detection more robust. The results show that LaneCPP achieves state-of-the-art performance in terms of F-Score and geometric errors.
Self-Supervised Linear Motion Deblurring
Feb 10, 2020
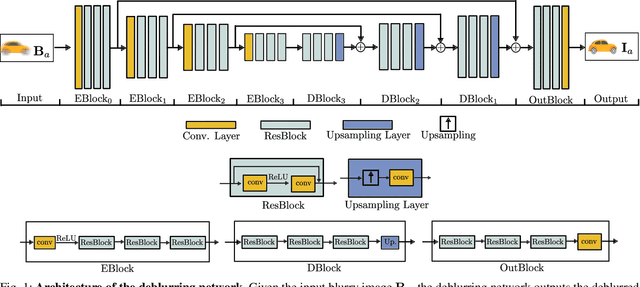


Motion blurry images challenge many computer vision algorithms, e.g, feature detection, motion estimation, or object recognition. Deep convolutional neural networks are state-of-the-art for image deblurring. However, obtaining training data with corresponding sharp and blurry image pairs can be difficult. In this paper, we present a differentiable reblur model for self-supervised motion deblurring, which enables the network to learn from real-world blurry image sequences without relying on sharp images for supervision. Our key insight is that motion cues obtained from consecutive images yield sufficient information to inform the deblurring task. We therefore formulate deblurring as an inverse rendering problem, taking into account the physical image formation process: we first predict two deblurred images from which we estimate the corresponding optical flow. Using these predictions, we re-render the blurred images and minimize the difference with respect to the original blurry inputs. We use both synthetic and real dataset for experimental evaluations. Our experiments demonstrate that self-supervised single image deblurring is really feasible and leads to visually compelling results.
Attacking Optical Flow
Oct 22, 2019


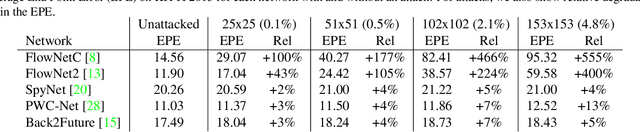
Deep neural nets achieve state-of-the-art performance on the problem of optical flow estimation. Since optical flow is used in several safety-critical applications like self-driving cars, it is important to gain insights into the robustness of those techniques. Recently, it has been shown that adversarial attacks easily fool deep neural networks to misclassify objects. The robustness of optical flow networks to adversarial attacks, however, has not been studied so far. In this paper, we extend adversarial patch attacks to optical flow networks and show that such attacks can compromise their performance. We show that corrupting a small patch of less than 1% of the image size can significantly affect optical flow estimates. Our attacks lead to noisy flow estimates that extend significantly beyond the region of the attack, in many cases even completely erasing the motion of objects in the scene. While networks using an encoder-decoder architecture are very sensitive to these attacks, we found that networks using a spatial pyramid architecture are less affected. We analyse the success and failure of attacking both architectures by visualizing their feature maps and comparing them to classical optical flow techniques which are robust to these attacks. We also demonstrate that such attacks are practical by placing a printed pattern into real scenes.
Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art
Apr 18, 2017
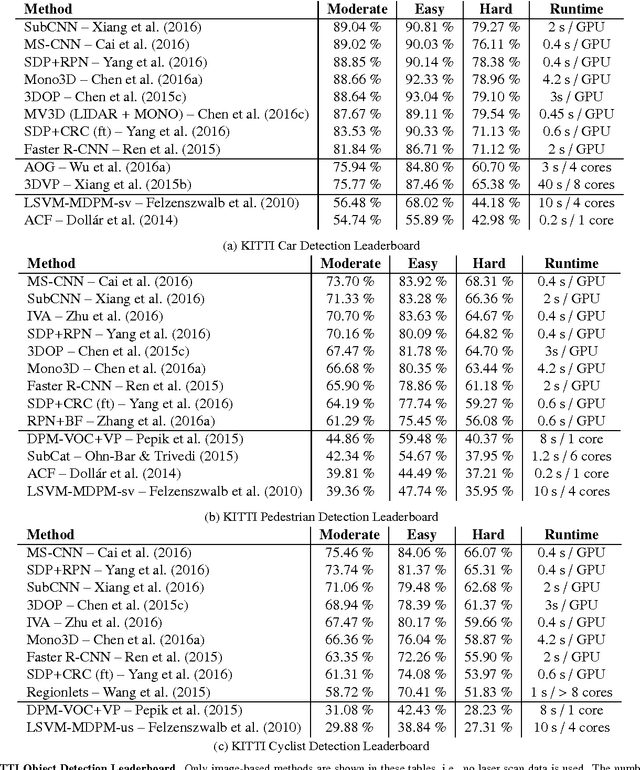

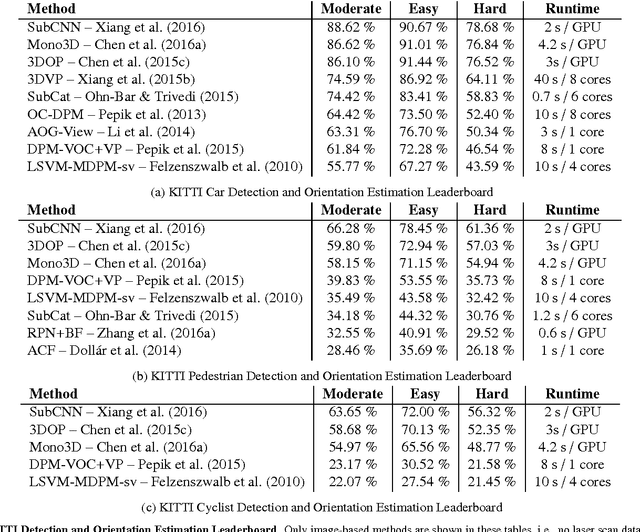
Recent years have witnessed amazing progress in AI related fields such as computer vision, machine learning and autonomous vehicles. As with any rapidly growing field, however, it becomes increasingly difficult to stay up-to-date or enter the field as a beginner. While several topic specific survey papers have been written, to date no general survey on problems, datasets and methods in computer vision for autonomous vehicles exists. This paper attempts to narrow this gap by providing a state-of-the-art survey on this topic. Our survey includes both the historically most relevant literature as well as the current state-of-the-art on several specific topics, including recognition, reconstruction, motion estimation, tracking, scene understanding and end-to-end learning. Towards this goal, we first provide a taxonomy to classify each approach and then analyze the performance of the state-of-the-art on several challenging benchmarking datasets including KITTI, ISPRS, MOT and Cityscapes. Besides, we discuss open problems and current research challenges. To ease accessibility and accommodate missing references, we will also provide an interactive platform which allows to navigate topics and methods, and provides additional information and project links for each paper.