 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Companion Learning: Enhancing Generalization Through Historical Consistency
Jul 26, 2024



We propose Deep Companion Learning (DCL), a novel training method for Deep Neural Networks (DNNs) that enhances generalization by penalizing inconsistent model predictions compared to its historical performance. To achieve this, we train a deep-companion model (DCM), by using previous versions of the model to provide forecasts on new inputs. This companion model deciphers a meaningful latent semantic structure within the data, thereby providing targeted supervision that encourages the primary model to address the scenarios it finds most challenging. We validate our approach through both theoretical analysis and extensive experimentation, including ablation studies, on a variety of benchmark datasets (CIFAR-100, Tiny-ImageNet, ImageNet-1K) using diverse architectural models (ShuffleNetV2, ResNet, Vision Transformer, etc.), demonstrating state-of-the-art performance.
Learning to Drive Anywhere
Sep 25, 2023



Human drivers can seamlessly adapt their driving decisions across geographical locations with diverse conditions and rules of the road, e.g., left vs. right-hand traffic. In contrast, existing models for autonomous driving have been thus far only deployed within restricted operational domains, i.e., without accounting for varying driving behaviors across locations or model scalability. In this work, we propose AnyD, a single geographically-aware conditional imitation learning (CIL) model that can efficiently learn from heterogeneous and globally distributed data with dynamic environmental, traffic, and social characteristics. Our key insight is to introduce a high-capacity geo-location-based channel attention mechanism that effectively adapts to local nuances while also flexibly modeling similarities among regions in a data-driven manner. By optimizing a contrastive imitation objective, our proposed approach can efficiently scale across inherently imbalanced data distributions and location-dependent events. We demonstrate the benefits of our AnyD agent across multiple datasets, cities, and scalable deployment paradigms, i.e., centralized, semi-supervised, and distributed agent training. Specifically, AnyD outperforms CIL baselines by over 14% in open-loop evaluation and 30% in closed-loop testing on CARLA.
Fine-grained Few-shot Recognition by Deep Object Parsing
Jul 14, 2022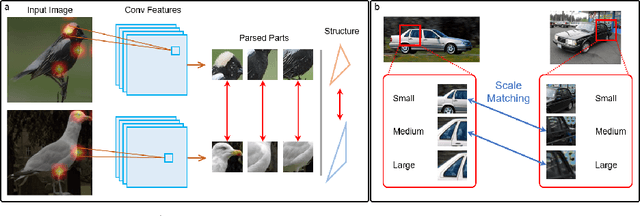
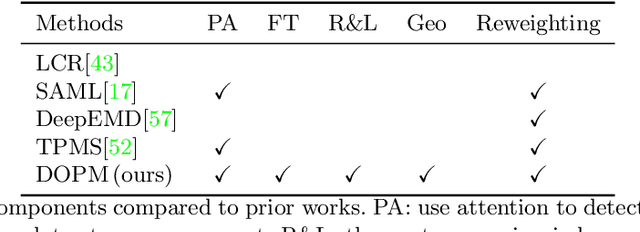
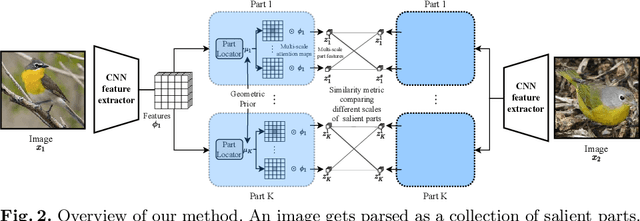
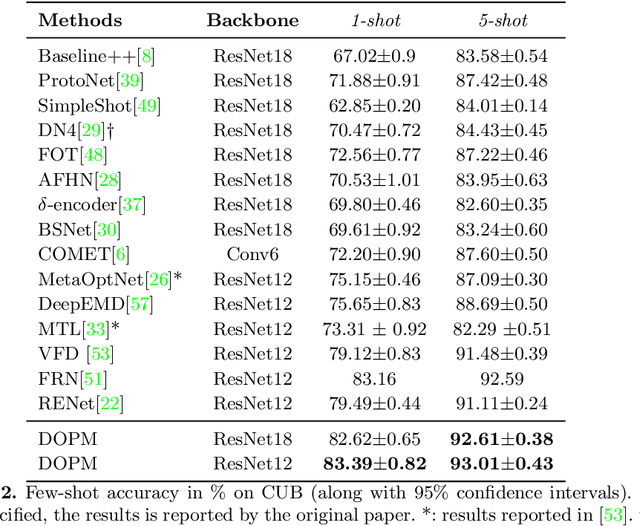
In our framework, an object is made up of K distinct parts or units, and we parse a test instance by inferring the K parts, where each part occupies a distinct location in the feature space, and the instance features at this location, manifest as an active subset of part templates shared across all instances. We recognize test instances by comparing its active templates and the relative geometry of its part locations against those of the presented few-shot instances. We propose an end-to-end training method to learn part templates on-top of a convolutional backbone. To combat visual distortions such as orientation, pose and size, we learn multi-scale templates, and at test-time parse and match instances across these scales. We show that our method is competitive with the state-of-the-art, and by virtue of parsing enjoys interpretability as well.
SelfD: Self-Learning Large-Scale Driving Policies From the Web
Apr 21, 2022
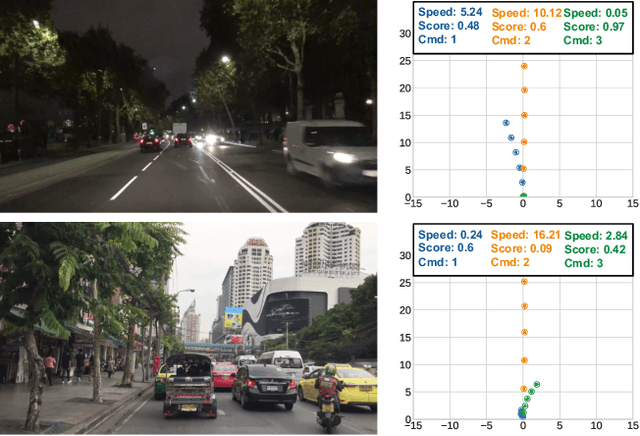
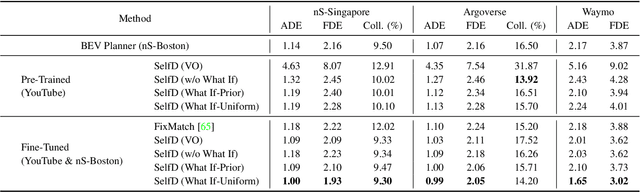

Effectively utilizing the vast amounts of ego-centric navigation data that is freely available on the internet can advance generalized intelligent systems, i.e., to robustly scale across perspectives, platforms, environmental conditions, scenarios, and geographical locations. However, it is difficult to directly leverage such large amounts of unlabeled and highly diverse data for complex 3D reasoning and planning tasks. Consequently, researchers have primarily focused on its use for various auxiliary pixel- and image-level computer vision tasks that do not consider an ultimate navigational objective. In this work, we introduce SelfD, a framework for learning scalable driving by utilizing large amounts of online monocular images. Our key idea is to leverage iterative semi-supervised training when learning imitative agents from unlabeled data. To handle unconstrained viewpoints, scenes, and camera parameters, we train an image-based model that directly learns to plan in the Bird's Eye View (BEV) space. Next, we use unlabeled data to augment the decision-making knowledge and robustness of an initially trained model via self-training. In particular, we propose a pseudo-labeling step which enables making full use of highly diverse demonstration data through "hypothetical" planning-based data augmentation. We employ a large dataset of publicly available YouTube videos to train SelfD and comprehensively analyze its generalization benefits across challenging navigation scenarios. Without requiring any additional data collection or annotation efforts, SelfD demonstrates consistent improvements (by up to 24%) in driving performance evaluation on nuScenes, Argoverse, Waymo, and CARLA.