 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Supporting Formal Email Exchange by Answering AI-Generated Questions
Feb 06, 2025



Replying to formal emails is time-consuming and cognitively demanding, as it requires polite phrasing and ensuring an adequate response to the sender's demands. Although systems with Large Language Models (LLM) were designed to simplify the email replying process, users still needed to provide detailed prompts to obtain the expected output. Therefore, we proposed and evaluated an LLM-powered question-and-answer (QA)-based approach for users to reply to emails by answering a set of simple and short questions generated from the incoming email. We developed a prototype system, ResQ, and conducted controlled and field experiments with 12 and 8 participants. Our results demonstrated that QA-based approach improves the efficiency of replying to emails and reduces workload while maintaining email quality compared to a conventional prompt-based approach that requires users to craft appropriate prompts to obtain email drafts. We discuss how QA-based approach influences the email reply process and interpersonal relationship dynamics, as well as the opportunities and challenges associated with using a QA-based approach in AI-mediated communication.
Redirection Controller Using Reinforcement Learning
Oct 16, 2019

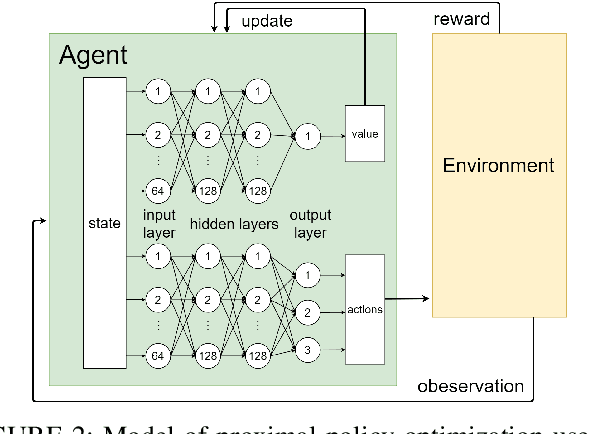

There is a growing demand for planning redirected walking techniques and applying them to physical environments with obstacles. Such techniques are mainly managed using three kinds of methods: direct scripting, generalized controller, and physical- or virtual-environment analysis to determine user redirection. The first approach is effective when a user's path and both physical and virtual environments are fixed; however, it is difficult to handle irregular movements and reuse other environments. The second approach has the potential of reusing any environment but is less optimized. The last approach is highly anticipated and versatile, although it has not been sufficiently developed. In this study, we propose a novel redirection controller using reinforcement learning with advanced plannability/versatility. Our simulation experiments show that the proposed strategy can reduce the number of resets by 20.3% for physical-space conditions with multiple obstacles.