 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Keyword Extraction for Full-sentence VQA
Paper and Code
Nov 23, 2019
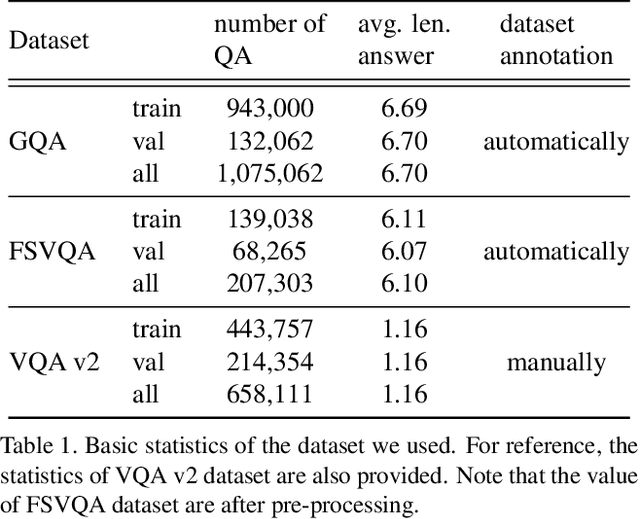
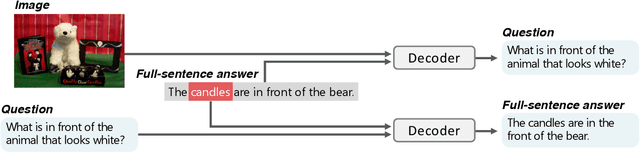

In existing studies on Visual Question Answering (VQA), which aims to train an intelligent system to be able to answer questions about images, the answers corresponding to the questions consists of short, almost single words. However, considering the natural conversation with humans, the answers would more likely to be sentences, rather than single words. In such a situation, the system needs to focus on a keyword, i.e., the most important word in the sentence, to answer the question. Therefore, we have proposed a novel keyword extraction method for VQA. Because collecting keywords and full-sentence annotations for VQA can be highly costly, we perform the keyword extraction in an unsupervised manner. Our key insight is that the full-sentence answer can be decomposed into two parts: the part contains new information for the question and the part only contains information already included in the question. Since the keyword is considered as the part which contains new information as the answer, we need to identify which words in the full-sentence answer are the part of new information and which words are not. To ensure such decomposition, we extracted two features from the full-sentence answers, and designed discriminative decoders to make each feature to include the information of the question and answers respectively. We conducted experiments on existing VQA datasets, which contains full-sentence annotations, and show that our proposed model can correctly extract the keyword without any keyword annotations.