 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Moment Retrieval with Text Query Considering Many-to-Many Correspondence Using Potentially Relevant Pair
Jun 25, 2021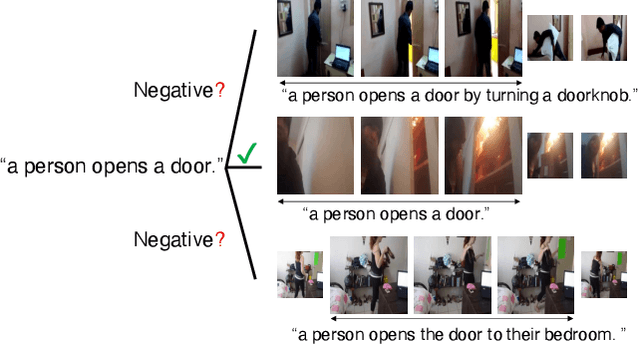
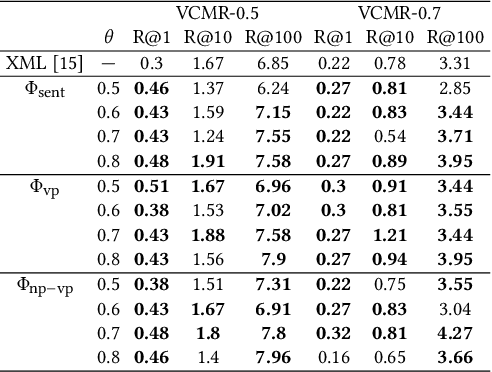
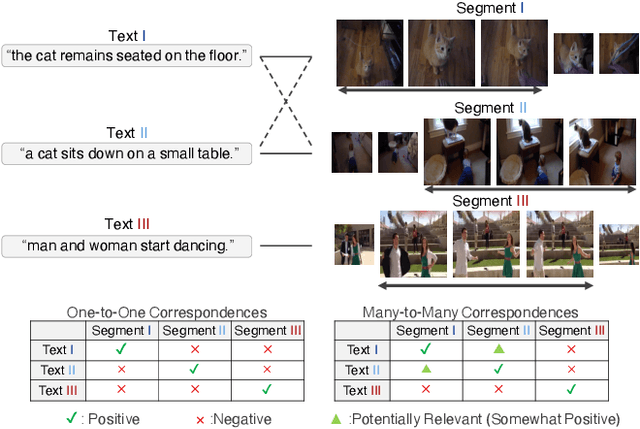
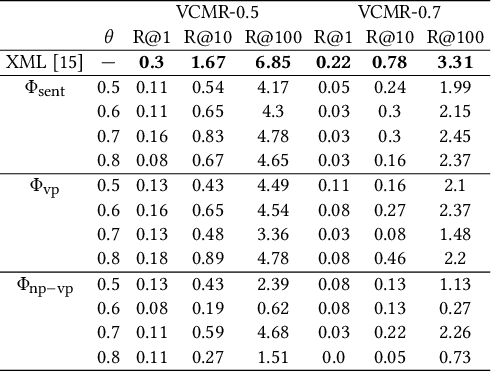
In this paper we undertake the task of text-based video moment retrieval from a corpus of videos. To train the model, text-moment paired datasets were used to learn the correct correspondences. In typical training methods, ground-truth text-moment pairs are used as positive pairs, whereas other pairs are regarded as negative pairs. However, aside from the ground-truth pairs, some text-moment pairs should be regarded as positive. In this case, one text annotation can be positive for many video moments. Conversely, one video moment can be corresponded to many text annotations. Thus, there are many-to-many correspondences between the text annotations and video moments. Based on these correspondences, we can form potentially relevant pairs, which are not given as ground truth yet are not negative; effectively incorporating such relevant pairs into training can improve the retrieval performance. The text query should describe what is happening in a video moment. Hence, different video moments annotated with similar texts, which contain a similar action, are likely to hold the similar action, thus these pairs can be considered as potentially relevant pairs. In this paper, we propose a novel training method that takes advantage of potentially relevant pairs, which are detected based on linguistic analysis about text annotation. Experiments on two benchmark datasets revealed that our method improves the retrieval performance both quantitatively and qualitatively.
Interactive Video Retrieval with Dialog
May 07, 2019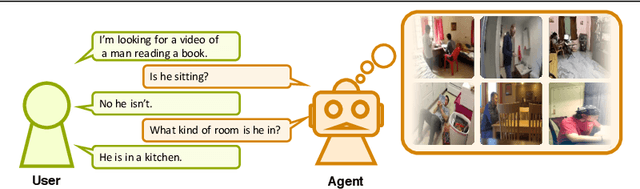

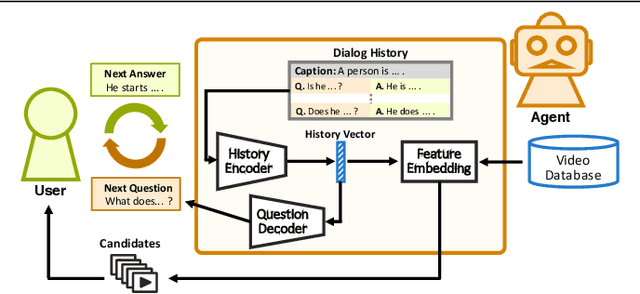

Now that everyone can easily record videos, the quantity of which is continuously increasing, research on methods for improved video retrieval is important in the contemporary world. In cases where target videos are to be identified within a large collection gathered by individuals, the appropriate information must be obtained to retrieve the correct video within a large number of similar items in the target database. The purpose of this research is to retrieve target videos in such cases by introducing an interaction, or a dialog, between the system and the user. We propose a system to retrieve videos by asking questions about the content of the videos and leveraging the user's responses to the questions. Additionally, we confirmed the usefulness of the proposed system through experiments using the dataset called AVSD which includes videos and dialogs about the videos.