 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecontextualization Mitigates Specification Gaming without Modifying the Specification
Dec 22, 2025Developers often struggle to specify correct training labels and rewards. Perhaps they don't need to. We propose recontextualization, which reduces how often language models "game" training signals, performing misbehaviors those signals mistakenly reinforce. We show recontextualization prevents models from learning to 1) prioritize evaluation metrics over chat response quality; 2) special-case code to pass incorrect tests; 3) lie to users; and 4) become sycophantic. Our method works by generating completions from prompts discouraging misbehavior and then recontextualizing them as though they were in response to prompts permitting misbehavior. Recontextualization trains language models to resist misbehavior even when instructions permit it. This mitigates the reinforcement of misbehavior from misspecified training signals, reducing specification gaming without improving the supervision signal.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Unifying and Verifying Mechanistic Interpretations: A Case Study with Group Operations
Oct 09, 2024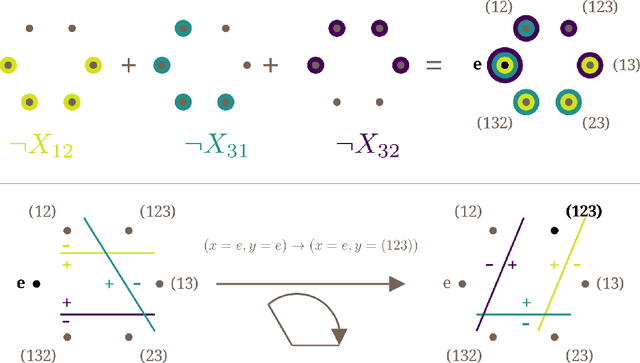
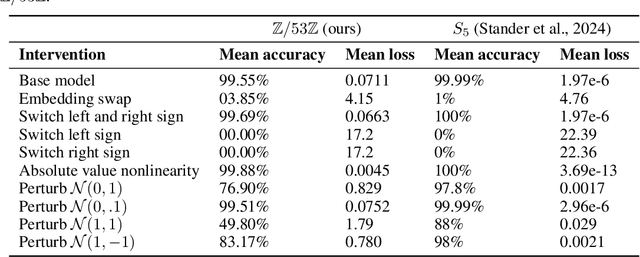
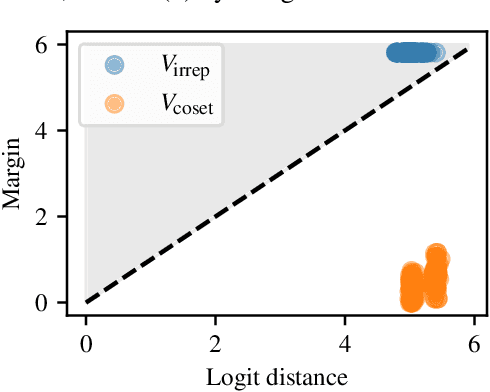

A recent line of work in mechanistic interpretability has focused on reverse-engineering the computation performed by neural networks trained on the binary operation of finite groups. We investigate the internals of one-hidden-layer neural networks trained on this task, revealing previously unidentified structure and producing a more complete description of such models that unifies the explanations of previous works. Notably, these models approximate equivariance in each input argument. We verify that our explanation applies to a large fraction of networks trained on this task by translating it into a compact proof of model performance, a quantitative evaluation of model understanding. In particular, our explanation yields a guarantee of model accuracy that runs in 30% the time of brute force and gives a >=95% accuracy bound for 45% of the models we trained. We were unable to obtain nontrivial non-vacuous accuracy bounds using only explanations from previous works.