 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMA: Single Interpolated Generative Model for Anomalies
Oct 27, 2024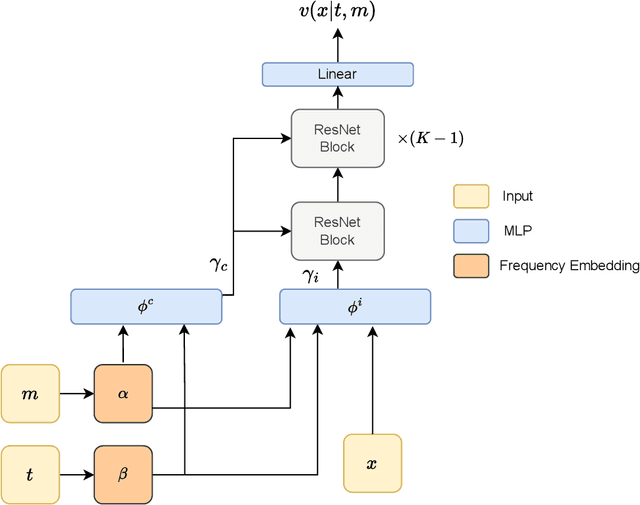
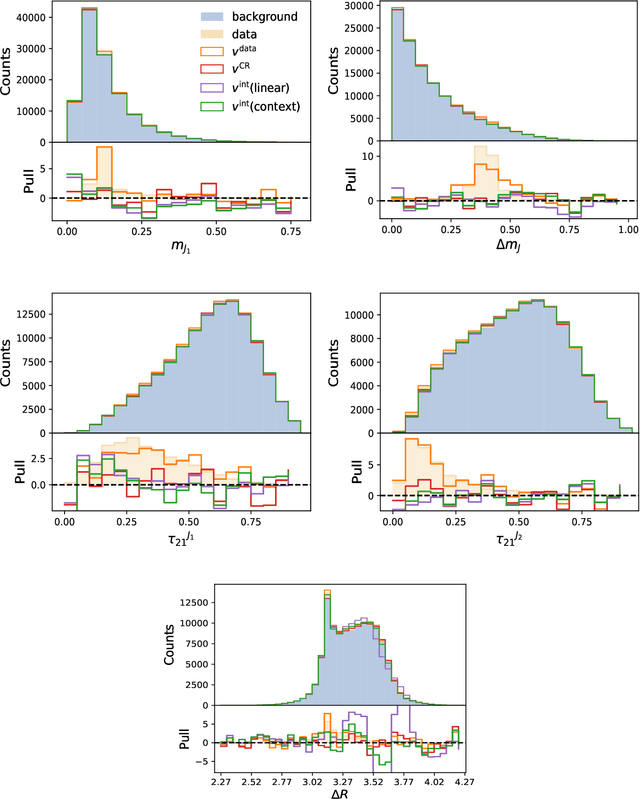
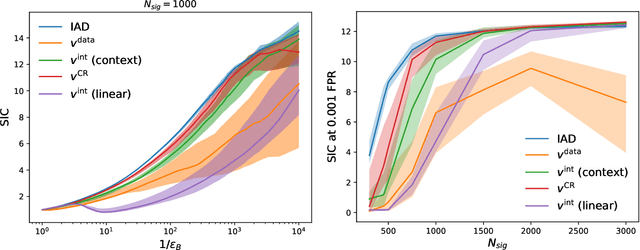
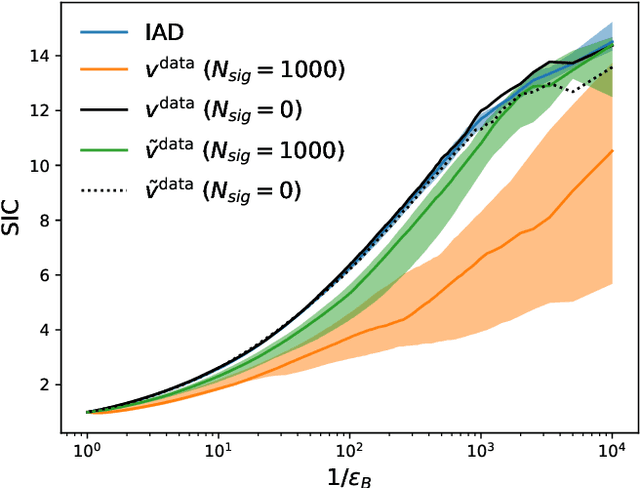
A key step in any resonant anomaly detection search is accurate modeling of the background distribution in each signal region. Data-driven methods like CATHODE accomplish this by training separate generative models on the complement of each signal region, and interpolating them into their corresponding signal regions. Having to re-train the generative model on essentially the entire dataset for each signal region is a major computational cost in a typical sliding window search with many signal regions. Here, we present SIGMA, a new, fully data-driven, computationally-efficient method for estimating background distributions. The idea is to train a single generative model on all of the data and interpolate its parameters in sideband regions in order to obtain a model for the background in the signal region. The SIGMA method significantly reduces the computational cost compared to previous approaches, while retaining a similar high quality of background modeling and sensitivity to anomalous signals.
Residual ANODE
Dec 18, 2023We present R-ANODE, a new method for data-driven, model-agnostic resonant anomaly detection that raises the bar for both performance and interpretability. The key to R-ANODE is to enhance the inductive bias of the anomaly detection task by fitting a normalizing flow directly to the small and unknown signal component, while holding fixed a background model (also a normalizing flow) learned from sidebands. In doing so, R-ANODE is able to outperform all classifier-based, weakly-supervised approaches, as well as the previous ANODE method which fit a density estimator to all of the data in the signal region instead of just the signal. We show that the method works equally well whether the unknown signal fraction is learned or fixed, and is even robust to signal fraction misspecification. Finally, with the learned signal model we can sample and gain qualitative insights into the underlying anomaly, which greatly enhances the interpretability of resonant anomaly detection and offers the possibility of simultaneously discovering and characterizing the new physics that could be hiding in the data.
Feature Selection with Distance Correlation
Nov 30, 2022



Choosing which properties of the data to use as input to multivariate decision algorithms -- a.k.a. feature selection -- is an important step in solving any problem with machine learning. While there is a clear trend towards training sophisticated deep networks on large numbers of relatively unprocessed inputs (so-called automated feature engineering), for many tasks in physics, sets of theoretically well-motivated and well-understood features already exist. Working with such features can bring many benefits, including greater interpretability, reduced training and run time, and enhanced stability and robustness. We develop a new feature selection method based on Distance Correlation (DisCo), and demonstrate its effectiveness on the tasks of boosted top- and $W$-tagging. Using our method to select features from a set of over 7,000 energy flow polynomials, we show that we can match the performance of much deeper architectures, by using only ten features and two orders-of-magnitude fewer model parameters.