 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Discovery
Sep 10, 2025The substantial data volumes encountered in modern particle physics and other domains of fundamental physics research allow (and require) the use of increasingly complex data analysis tools and workflows. While the use of machine learning (ML) tools for data analysis has recently proliferated, these tools are typically special-purpose algorithms that rely, for example, on encoded physics knowledge to reach optimal performance. In this work, we investigate a new and orthogonal direction: Using recent progress in large language models (LLMs) to create a team of agents -- instances of LLMs with specific subtasks -- that jointly solve data analysis-based research problems in a way similar to how a human researcher might: by creating code to operate standard tools and libraries (including ML systems) and by building on results of previous iterations. If successful, such agent-based systems could be deployed to automate routine analysis components to counteract the increasing complexity of modern tool chains. To investigate the capabilities of current-generation commercial LLMs, we consider the task of anomaly detection via the publicly available and highly-studied LHC Olympics dataset. Several current models by OpenAI (GPT-4o, o4-mini, GPT-4.1, and GPT-5) are investigated and their stability tested. Overall, we observe the capacity of the agent-based system to solve this data analysis problem. The best agent-created solutions mirror the performance of human state-of-the-art results.
OmniJet-${α_{ C}}$: Learning point cloud calorimeter simulations using generative transformers
Jan 09, 2025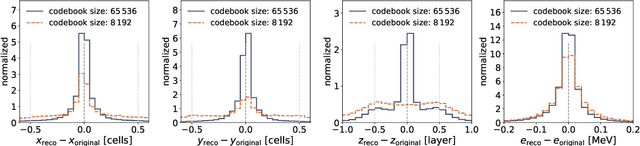
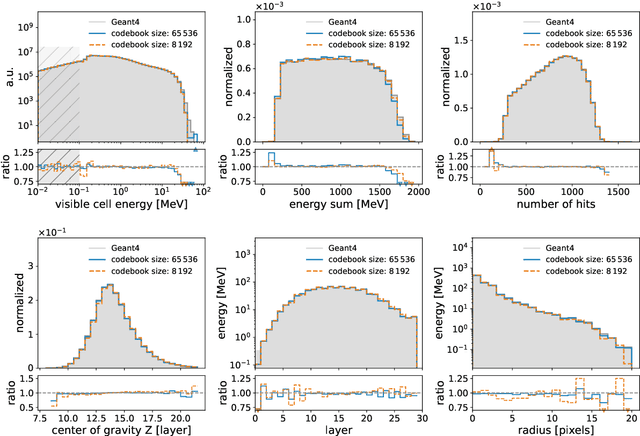
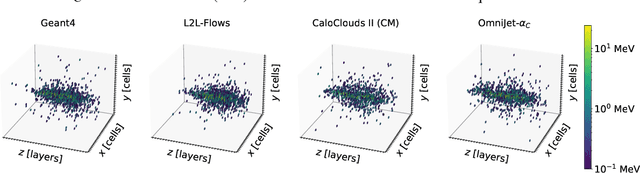
We show the first use of generative transformers for generating calorimeter showers as point clouds in a high-granularity calorimeter. Using the tokenizer and generative part of the OmniJet-${\alpha}$ model, we represent the hits in the detector as sequences of integers. This model allows variable-length sequences, which means that it supports realistic shower development and does not need to be conditioned on the number of hits. Since the tokenization represents the showers as point clouds, the model learns the geometry of the showers without being restricted to any particular voxel grid.
Aspen Open Jets: Unlocking LHC Data for Foundation Models in Particle Physics
Dec 13, 2024Foundation models are deep learning models pre-trained on large amounts of data which are capable of generalizing to multiple datasets and/or downstream tasks. This work demonstrates how data collected by the CMS experiment at the Large Hadron Collider can be useful in pre-training foundation models for HEP. Specifically, we introduce the AspenOpenJets dataset, consisting of approximately 180M high $p_T$ jets derived from CMS 2016 Open Data. We show how pre-training the OmniJet-$\alpha$ foundation model on AspenOpenJets improves performance on generative tasks with significant domain shift: generating boosted top and QCD jets from the simulated JetClass dataset. In addition to demonstrating the power of pre-training of a jet-based foundation model on actual proton-proton collision data, we provide the ML-ready derived AspenOpenJets dataset for further public use.
Universal New Physics Latent Space
Jul 29, 2024

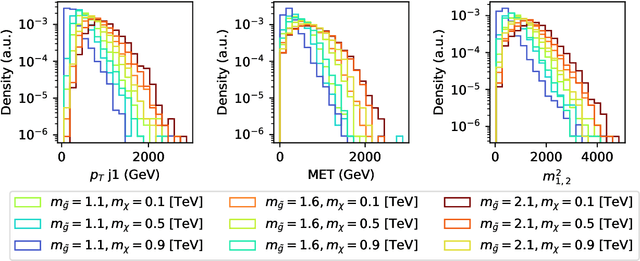

We develop a machine learning method for mapping data originating from both Standard Model processes and various theories beyond the Standard Model into a unified representation (latent) space while conserving information about the relationship between the underlying theories. We apply our method to three examples of new physics at the LHC of increasing complexity, showing that models can be clustered according to their LHC phenomenology: different models are mapped to distinct regions in latent space, while indistinguishable models are mapped to the same region. This opens interesting new avenues on several fronts, such as model discrimination, selection of representative benchmark scenarios, and identifying gaps in the coverage of model space.
OmniJet-$α$: The first cross-task foundation model for particle physics
Mar 08, 2024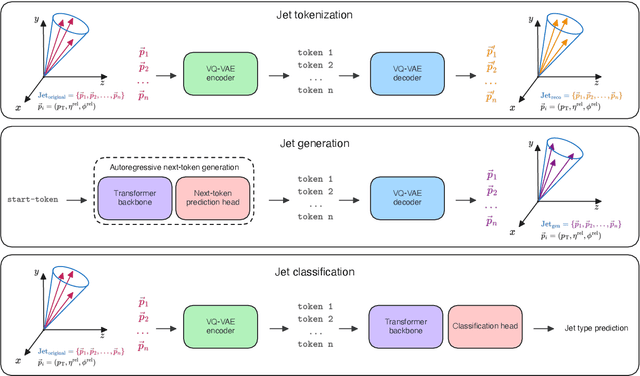
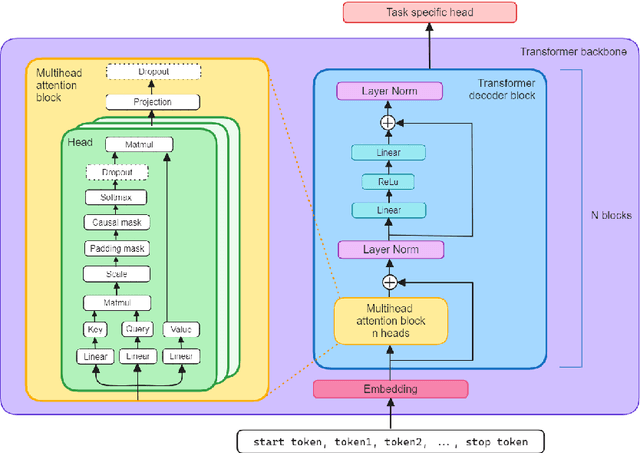
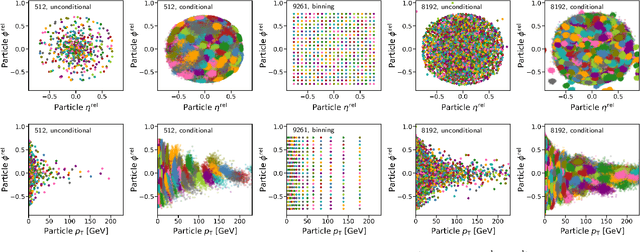
Foundation models are multi-dataset and multi-task machine learning methods that once pre-trained can be fine-tuned for a large variety of downstream applications. The successful development of such general-purpose models for physics data would be a major breakthrough as they could improve the achievable physics performance while at the same time drastically reduce the required amount of training time and data. We report significant progress on this challenge on several fronts. First, a comprehensive set of evaluation methods is introduced to judge the quality of an encoding from physics data into a representation suitable for the autoregressive generation of particle jets with transformer architectures (the common backbone of foundation models). These measures motivate the choice of a higher-fidelity tokenization compared to previous works. Finally, we demonstrate transfer learning between an unsupervised problem (jet generation) and a classic supervised task (jet tagging) with our new OmniJet-$\alpha$ model. This is the first successful transfer between two different and actively studied classes of tasks and constitutes a major step in the building of foundation models for particle physics.