 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised machine learning techniques for data matching based on similarity metrics
Paper and Code
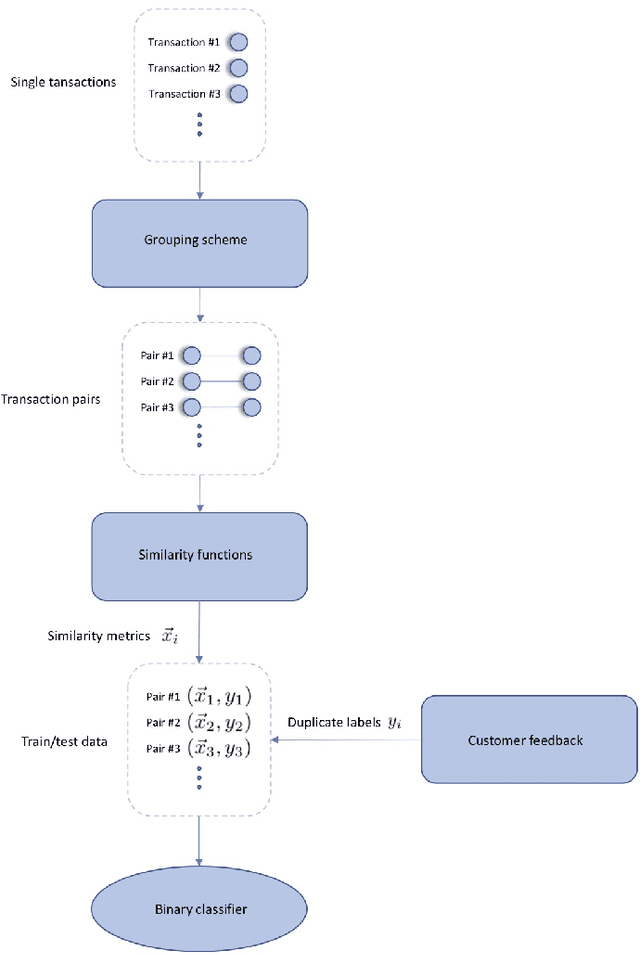


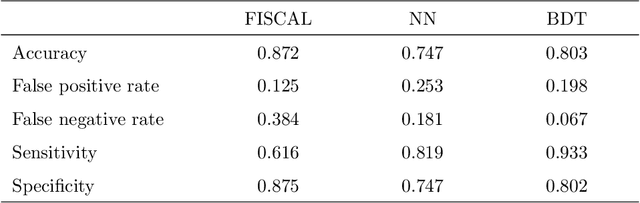
Businesses, governmental bodies and NGO's have an ever-increasing amount of data at their disposal from which they try to extract valuable information. Often, this needs to be done not only accurately but also within a short time frame. Clean and consistent data is therefore crucial. Data matching is the field that tries to identify instances in data that refer to the same real-world entity. In this study, machine learning techniques are combined with string similarity functions to the field of data matching. A dataset of invoices from a variety of businesses and organizations was preprocessed with a grouping scheme to reduce pair dimensionality and a set of similarity functions was used to quantify similarity between invoice pairs. The resulting invoice pair dataset was then used to train and validate a neural network and a boosted decision tree. The performance was compared with a solution from FISCAL Technologies as a benchmark against currently available deduplication solutions. Both the neural network and boosted decision tree showed equal to better performance.