 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental Analysis of Productive Interaction Strategy with ChatGPT: User Study on Function and Project-level Code Generation Tasks
Aug 06, 2025The application of Large Language Models (LLMs) is growing in the productive completion of Software Engineering tasks. Yet, studies investigating the productive prompting techniques often employed a limited problem space, primarily focusing on well-known prompting patterns and mainly targeting function-level SE practices. We identify significant gaps in real-world workflows that involve complexities beyond class-level (e.g., multi-class dependencies) and different features that can impact Human-LLM Interactions (HLIs) processes in code generation. To address these issues, we designed an experiment that comprehensively analyzed the HLI features regarding the code generation productivity. Our study presents two project-level benchmark tasks, extending beyond function-level evaluations. We conducted a user study with 36 participants from diverse backgrounds, asking them to solve the assigned tasks by interacting with the GPT assistant using specific prompting patterns. We also examined the participants' experience and their behavioral features during interactions by analyzing screen recordings and GPT chat logs. Our statistical and empirical investigation revealed (1) that three out of 15 HLI features significantly impacted the productivity in code generation; (2) five primary guidelines for enhancing productivity for HLI processes; and (3) a taxonomy of 29 runtime and logic errors that can occur during HLI processes, along with suggested mitigation plans.
Trend Filtered Mixture of Experts for Automated Gating of High-Frequency Flow Cytometry Data
Apr 16, 2025Ocean microbes are critical to both ocean ecosystems and the global climate. Flow cytometry, which measures cell optical properties in fluid samples, is routinely used in oceanographic research. Despite decades of accumulated data, identifying key microbial populations (a process known as ``gating'') remains a significant analytical challenge. To address this, we focus on gating multidimensional, high-frequency flow cytometry data collected {\it continuously} on board oceanographic research vessels, capturing time- and space-wise variations in the dynamic ocean. Our paper proposes a novel mixture-of-experts model in which both the gating function and the experts are given by trend filtering. The model leverages two key assumptions: (1) Each snapshot of flow cytometry data is a mixture of multivariate Gaussians and (2) the parameters of these Gaussians vary smoothly over time. Our method uses regularization and a constraint to ensure smoothness and that cluster means match biologically distinct microbe types. We demonstrate, using flow cytometry data from the North Pacific Ocean, that our proposed model accurately matches human-annotated gating and corrects significant errors.
DDPT: Diffusion-Driven Prompt Tuning for Large Language Model Code Generation
Apr 06, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation. However, the quality of the generated code is heavily dependent on the structure and composition of the prompts used. Crafting high-quality prompts is a challenging task that requires significant knowledge and skills of prompt engineering. To advance the automation support for the prompt engineering for LLM-based code generation, we propose a novel solution Diffusion-Driven Prompt Tuning (DDPT) that learns how to generate optimal prompt embedding from Gaussian Noise to automate the prompt engineering for code generation. We evaluate the feasibility of diffusion-based optimization and abstract the optimal prompt embedding as a directional vector toward the optimal embedding. We use the code generation loss given by the LLMs to help the diffusion model capture the distribution of optimal prompt embedding during training. The trained diffusion model can build a path from the noise distribution to the optimal distribution at the sampling phrase, the evaluation result demonstrates that DDPT helps improve the prompt optimization for code generation.
METAL: Metamorphic Testing Framework for Analyzing Large-Language Model Qualities
Dec 11, 2023

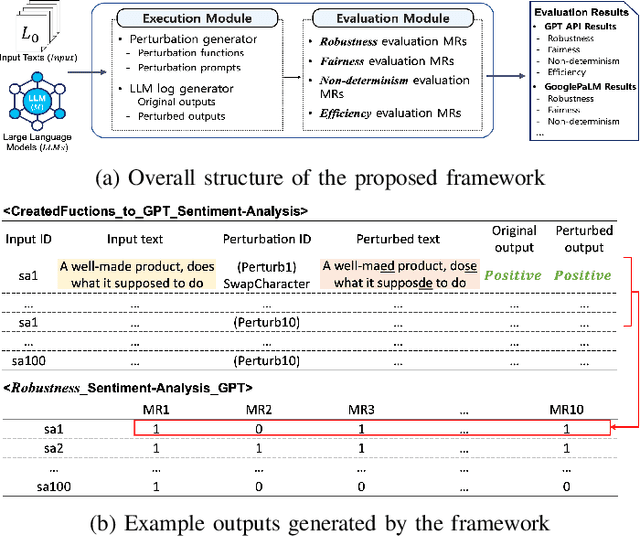
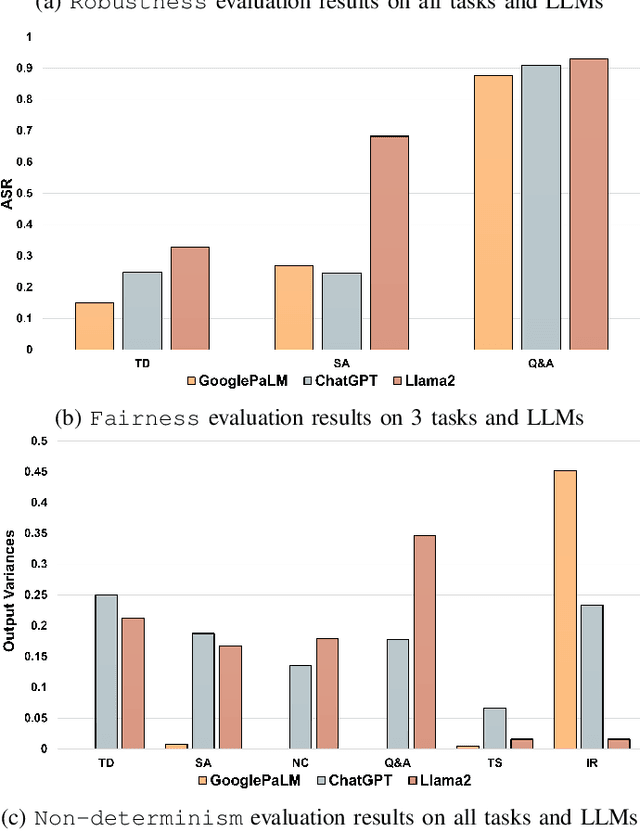
Large-Language Models (LLMs) have shifted the paradigm of natural language data processing. However, their black-boxed and probabilistic characteristics can lead to potential risks in the quality of outputs in diverse LLM applications. Recent studies have tested Quality Attributes (QAs), such as robustness or fairness, of LLMs by generating adversarial input texts. However, existing studies have limited their coverage of QAs and tasks in LLMs and are difficult to extend. Additionally, these studies have only used one evaluation metric, Attack Success Rate (ASR), to assess the effectiveness of their approaches. We propose a MEtamorphic Testing for Analyzing LLMs (METAL) framework to address these issues by applying Metamorphic Testing (MT) techniques. This approach facilitates the systematic testing of LLM qualities by defining Metamorphic Relations (MRs), which serve as modularized evaluation metrics. The METAL framework can automatically generate hundreds of MRs from templates that cover various QAs and tasks. In addition, we introduced novel metrics that integrate the ASR method into the semantic qualities of text to assess the effectiveness of MRs accurately. Through the experiments conducted with three prominent LLMs, we have confirmed that the METAL framework effectively evaluates essential QAs on primary LLM tasks and reveals the quality risks in LLMs. Moreover, the newly proposed metrics can guide the optimal MRs for testing each task and suggest the most effective method for generating MRs.
Modeling Cell Populations Measured By Flow Cytometry With Covariates Using Sparse Mixture of Regressions
Aug 25, 2020

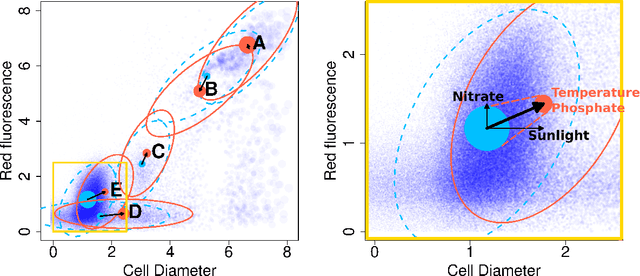
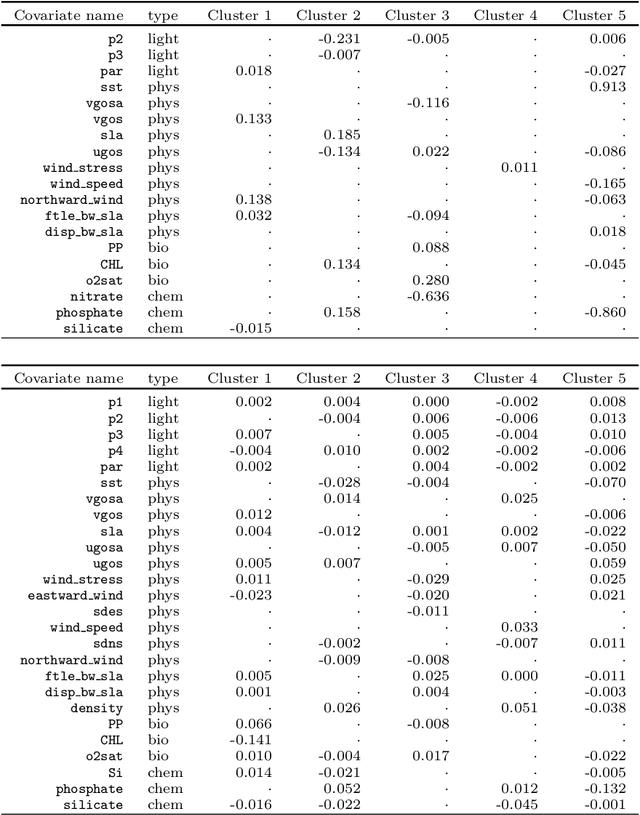
The ocean is filled with microscopic microalgae called phytoplankton, which together are responsible for as much photosynthesis as all plants on land combined. Our ability to predict their response to the warming ocean relies on understanding how the dynamics of phytoplankton populations is influenced by changes in environmental conditions. One powerful technique to study the dynamics of phytoplankton is flow cytometry, which measures the optical properties of thousands of individual cells per second. Today, oceanographers are able to collect flow cytometry data in real-time onboard a moving ship, providing them with fine-scale resolution of the distribution of phytoplankton across thousands of kilometers. One of the current challenges is to understand how these small and large scale variations relate to environmental conditions, such as nutrient availability, temperature, light and ocean currents. In this paper, we propose a novel sparse mixture of multivariate regressions model to estimate the time-varying phytoplankton subpopulations while simultaneously identifying the specific environmental covariates that are predictive of the observed changes to these subpopulations. We demonstrate the usefulness and interpretability of the approach using both synthetic data and real observations collected on an oceanographic cruise conducted in the north-east Pacific in the spring of 2017.