 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLM: Removing the GPU Memory Barrier for 3D Gaussian Splatting
Nov 07, 20253D Gaussian Splatting (3DGS) is an increasingly popular novel view synthesis approach due to its fast rendering time, and high-quality output. However, scaling 3DGS to large (or intricate) scenes is challenging due to its large memory requirement, which exceed most GPU's memory capacity. In this paper, we describe CLM, a system that allows 3DGS to render large scenes using a single consumer-grade GPU, e.g., RTX4090. It does so by offloading Gaussians to CPU memory, and loading them into GPU memory only when necessary. To reduce performance and communication overheads, CLM uses a novel offloading strategy that exploits observations about 3DGS's memory access pattern for pipelining, and thus overlap GPU-to-CPU communication, GPU computation and CPU computation. Furthermore, we also exploit observation about the access pattern to reduce communication volume. Our evaluation shows that the resulting implementation can render a large scene that requires 100 million Gaussians on a single RTX4090 and achieve state-of-the-art reconstruction quality.
On Scaling Up 3D Gaussian Splatting Training
Jun 26, 2024

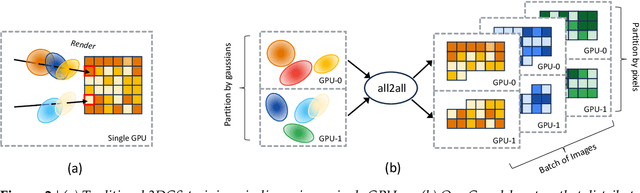

3D Gaussian Splatting (3DGS) is increasingly popular for 3D reconstruction due to its superior visual quality and rendering speed. However, 3DGS training currently occurs on a single GPU, limiting its ability to handle high-resolution and large-scale 3D reconstruction tasks due to memory constraints. We introduce Grendel, a distributed system designed to partition 3DGS parameters and parallelize computation across multiple GPUs. As each Gaussian affects a small, dynamic subset of rendered pixels, Grendel employs sparse all-to-all communication to transfer the necessary Gaussians to pixel partitions and performs dynamic load balancing. Unlike existing 3DGS systems that train using one camera view image at a time, Grendel supports batched training with multiple views. We explore various optimization hyperparameter scaling strategies and find that a simple sqrt(batch size) scaling rule is highly effective. Evaluations using large-scale, high-resolution scenes show that Grendel enhances rendering quality by scaling up 3DGS parameters across multiple GPUs. On the Rubble dataset, we achieve a test PSNR of 27.28 by distributing 40.4 million Gaussians across 16 GPUs, compared to a PSNR of 26.28 using 11.2 million Gaussians on a single GPU. Grendel is an open-source project available at: https://github.com/nyu-systems/Grendel-GS
On Optimizing the Communication of Model Parallelism
Nov 10, 2022

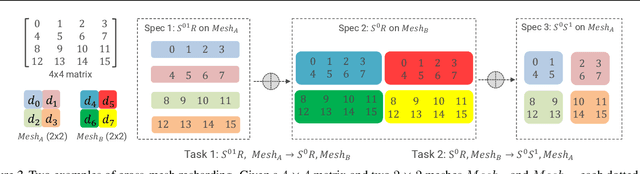

We study a novel and important communication pattern in large-scale model-parallel deep learning (DL), which we call cross-mesh resharding. This pattern emerges when the two paradigms of model parallelism - intra-operator and inter-operator parallelism - are combined to support large models on large clusters. In cross-mesh resharding, a sharded tensor needs to be sent from a source device mesh to a destination device mesh, on which the tensor may be distributed with the same or different layouts. We formalize this as a many-to-many multicast communication problem, and show that existing approaches either are sub-optimal or do not generalize to different network topologies or tensor layouts, which result from different model architectures and parallelism strategies. We then propose two contributions to address cross-mesh resharding: an efficient broadcast-based communication system, and an "overlapping-friendly" pipeline schedule. On microbenchmarks, our overall system outperforms existing ones by up to 10x across various tensor and mesh layouts. On end-to-end training of two large models, GPT-3 and U-Transformer, we improve throughput by 10% and 50%, respectively.
Fully Hyperbolic Neural Networks
May 31, 2021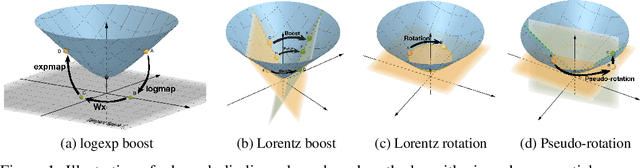
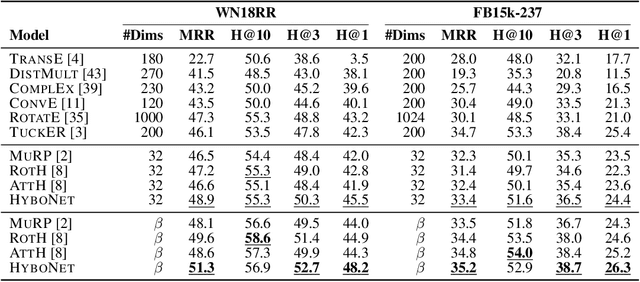
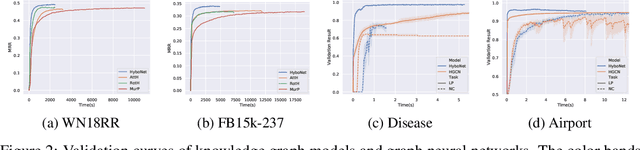
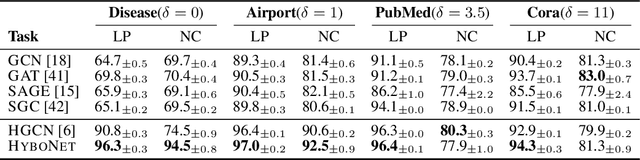
Hyperbolic neural networks have shown great potential for modeling complex data. However, existing hyperbolic networks are not completely hyperbolic, as they encode features in a hyperbolic space yet formalize most of their operations in the tangent space (a Euclidean subspace) at the origin of the hyperbolic space. This hybrid method greatly limits the modeling ability of networks. In this paper, we propose a fully hyperbolic framework to build hyperbolic networks based on the Lorentz model by adapting the Lorentz transformations (including boost and rotation) to formalize essential operations of neural networks. Moreover, we also prove that linear transformation in tangent spaces used by existing hyperbolic networks is a relaxation of the Lorentz rotation and does not include the boost, implicitly limiting the capabilities of existing hyperbolic networks. The experimental results on four NLP tasks show that our method has better performance for building both shallow and deep networks. Our code will be released to facilitate follow-up research.