 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Self-supervised learning for ASR
Nov 04, 2022Self-supervised learning via masked prediction pre-training (MPPT) has shown impressive performance on a range of speech-processing tasks. This paper proposes a method to bias self-supervised learning towards a specific task. The core idea is to slightly finetune the model that is used to obtain the target sequence. This leads to better performance and a substantial increase in training speed. Furthermore, this paper proposes a variant of MPPT that allows low-footprint streaming models to be trained effectively by computing the MPPT loss on masked and unmasked frames. These approaches are evaluated for automatic speech recognition on the Librispeech corpus, where 100 hours of data served as the labelled data and 860 hours as the unlabelled data. The biased training outperforms the unbiased training by 15.5% after 250k updates and 23.8% after 100k updates on test-other. For the streaming models, the pre-training approach yields a reduction in word error rate of 44.1%.
A Distributed Optimisation Framework Combining Natural Gradient with Hessian-Free for Discriminative Sequence Training
Mar 12, 2021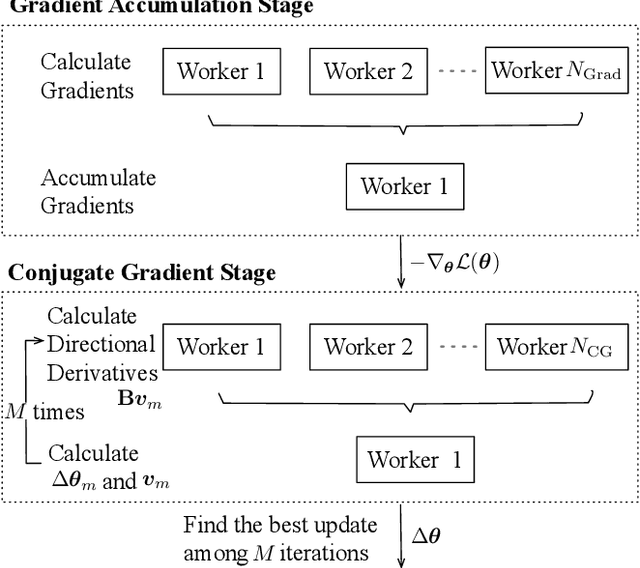

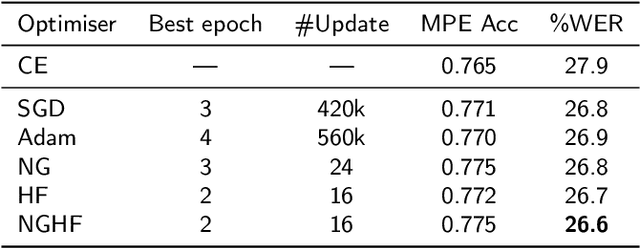
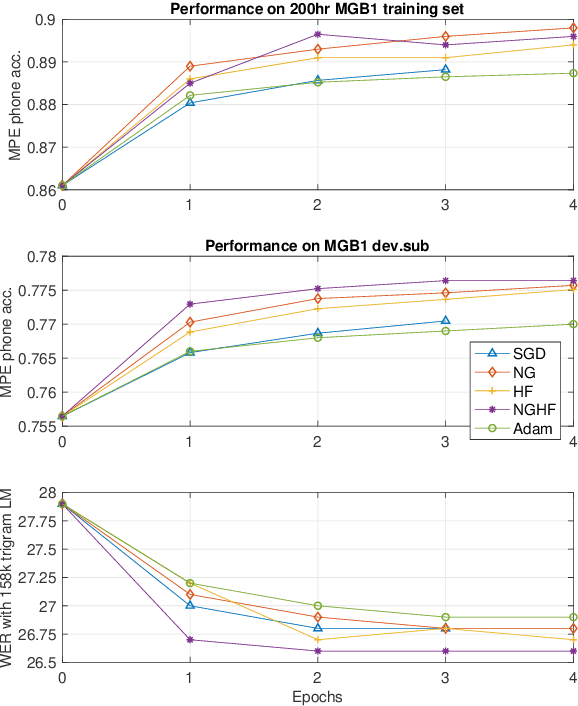
This paper presents a novel natural gradient and Hessian-free (NGHF) optimisation framework for neural network training that can operate efficiently in a distributed manner. It relies on the linear conjugate gradient (CG) algorithm to combine the natural gradient (NG) method with local curvature information from Hessian-free (HF) or other second-order methods. A solution to a numerical issue in CG allows effective parameter updates to be generated with far fewer CG iterations than usually used (e.g. 5-8 instead of 200). This work also presents a novel preconditioning approach to improve the progress made by individual CG iterations for models with shared parameters. Although applicable to other training losses and model structures, NGHF is investigated in this paper for lattice-based discriminative sequence training for hybrid hidden Markov model acoustic models using a standard recurrent neural network, long short-term memory, and time delay neural network models for output probability calculation. Automatic speech recognition experiments are reported on the multi-genre broadcast data set for a range of different acoustic model types. These experiments show that NGHF achieves larger word error rate reductions than standard stochastic gradient descent or Adam, while requiring orders of magnitude fewer parameter updates.
Discriminative Neural Clustering for Speaker Diarisation
Oct 22, 2019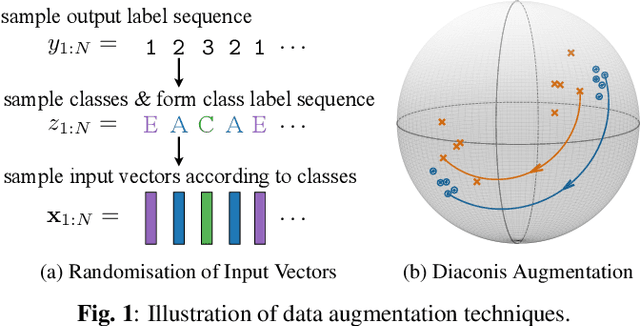

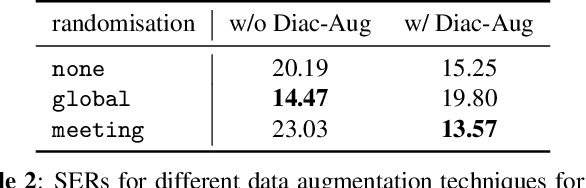
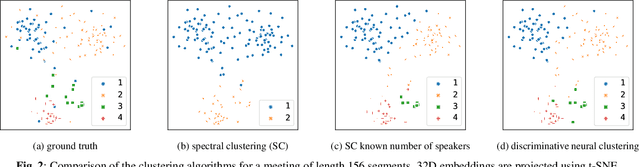
This paper proposes a novel method for supervised data clustering. The clustering procedure is modelled by a discriminative sequence-to-sequence neural network that learns from examples. The effectiveness of the Transformer-based Discriminative Neural Clustering (DNC) model is validated on a speaker diarisation task using the challenging AMI data set, where audio segments need to be clustered into an unknown number of speakers. The AMI corpus contains only 147 meetings as training examples for the DNC model, which is very limited for training an encoder-decoder neural network. Data scarcity is mitigated through three data augmentation schemes proposed in this paper, including Diaconis Augmentation, a novel technique proposed for discriminative embeddings trained using cosine similarities. Comparing between DNC and the commonly used spectral clustering algorithm for speaker diarisation shows that the DNC approach outperforms its unsupervised counterpart by 29.4% relative. Furthermore, DNC requires no explicit definition of a similarity measure between samples, which is a significant advantage considering that such a measure might be difficult to specify.