 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Environmental Sound Recognition: Performance versus Computational Cost
Paper and Code
Jul 15, 2016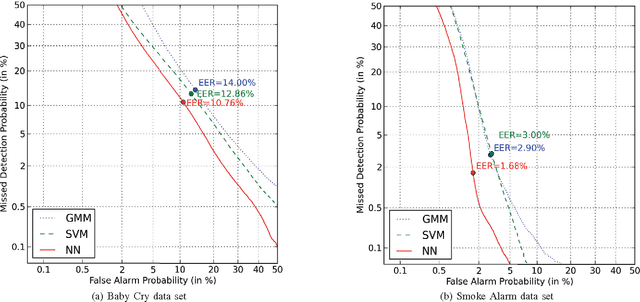
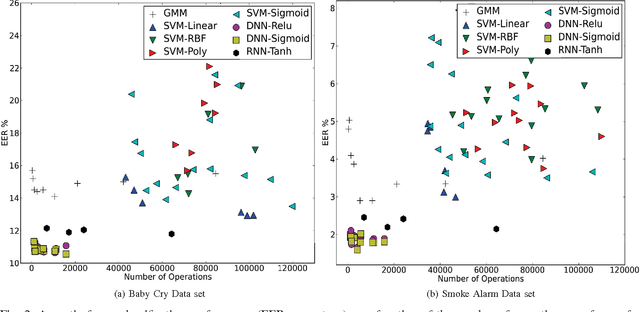
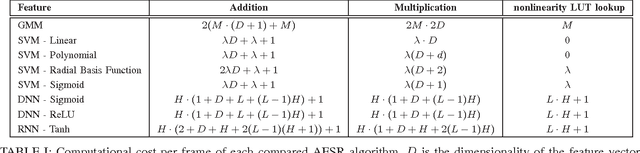

In the context of the Internet of Things (IoT), sound sensing applications are required to run on embedded platforms where notions of product pricing and form factor impose hard constraints on the available computing power. Whereas Automatic Environmental Sound Recognition (AESR) algorithms are most often developed with limited consideration for computational cost, this article seeks which AESR algorithm can make the most of a limited amount of computing power by comparing the sound classification performance em as a function of its computational cost. Results suggest that Deep Neural Networks yield the best ratio of sound classification accuracy across a range of computational costs, while Gaussian Mixture Models offer a reasonable accuracy at a consistently small cost, and Support Vector Machines stand between both in terms of compromise between accuracy and computational cost.