 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning with Cross Attention for Keyword Spotting
Paper and Code
Jul 15, 2021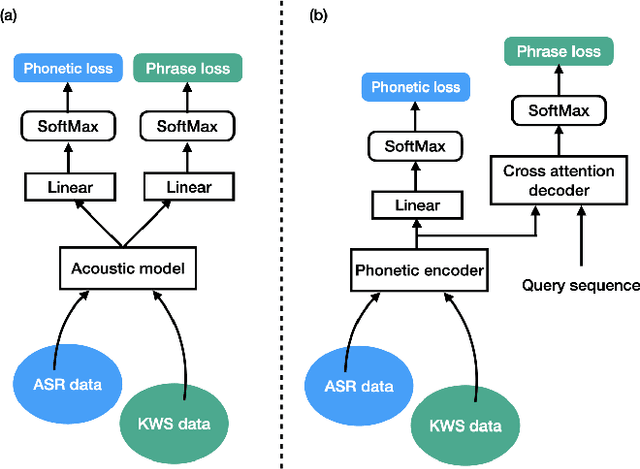
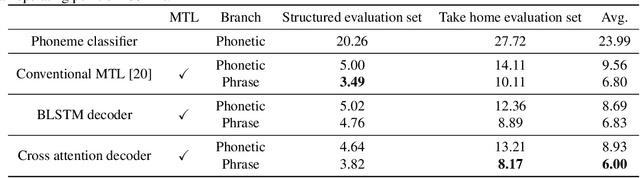
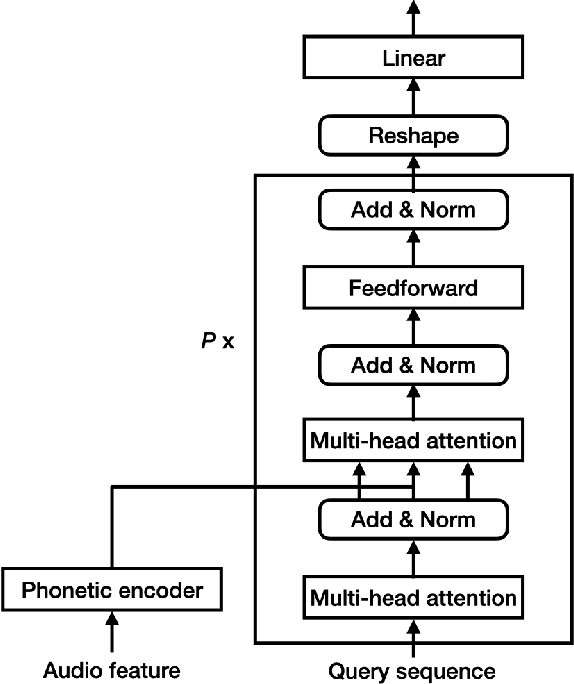
Keyword spotting (KWS) is an important technique for speech applications, which enables users to activate devices by speaking a keyword phrase. Although a phoneme classifier can be used for KWS, exploiting a large amount of transcribed data for automatic speech recognition (ASR), there is a mismatch between the training criterion (phoneme recognition) and the target task (KWS). Recently, multi-task learning has been applied to KWS to exploit both ASR and KWS training data. In this approach, an output of an acoustic model is split into two branches for the two tasks, one for phoneme transcription trained with the ASR data and one for keyword classification trained with the KWS data. In this paper, we introduce a cross attention decoder in the multi-task learning framework. Unlike the conventional multi-task learning approach with the simple split of the output layer, the cross attention decoder summarizes information from a phonetic encoder by performing cross attention between the encoder outputs and a trainable query sequence to predict a confidence score for the KWS task. Experimental results on KWS tasks show that the proposed approach outperformed the conventional multi-task learning with split branches and a bi-directional long short-team memory decoder by 12% on average.