 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSPP: A Unified Benchmarking Tool for Time-series Forecasting
Jan 08, 2024



While machine learning has witnessed significant advancements, the emphasis has largely been on data acquisition and model creation. However, achieving a comprehensive assessment of machine learning solutions in real-world settings necessitates standardization throughout the entire pipeline. This need is particularly acute in time series forecasting, where diverse settings impede meaningful comparisons between various methods. To bridge this gap, we propose a unified benchmarking framework that exposes the crucial modelling and machine learning decisions involved in developing time series forecasting models. This framework fosters seamless integration of models and datasets, aiding both practitioners and researchers in their development efforts. We benchmark recently proposed models within this framework, demonstrating that carefully implemented deep learning models with minimal effort can rival gradient-boosting decision trees requiring extensive feature engineering and expert knowledge.
Heterogenous Ensemble of Models for Molecular Property Prediction
Nov 20, 2022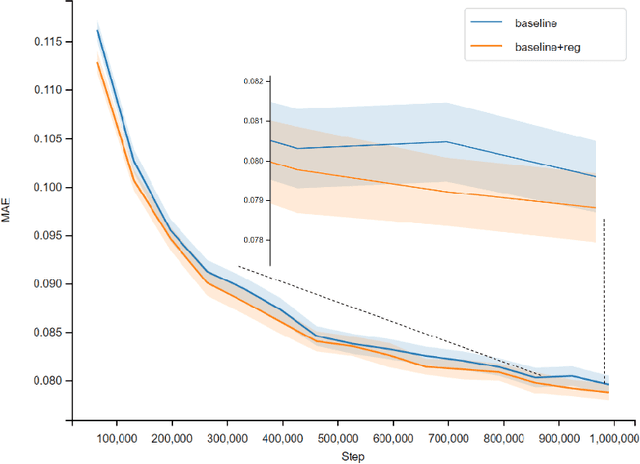
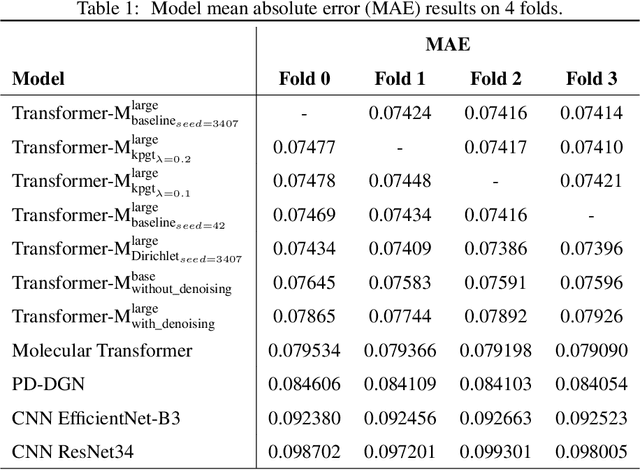
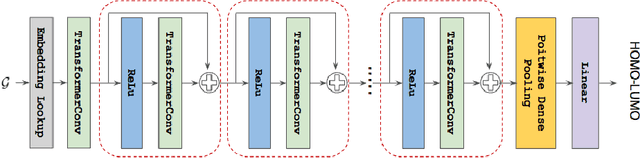
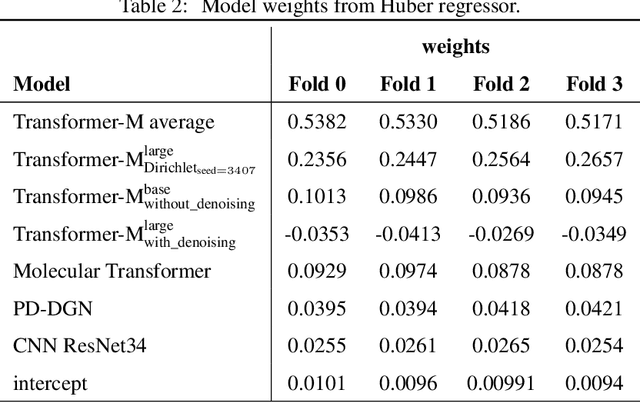
Previous works have demonstrated the importance of considering different modalities on molecules, each of which provide a varied granularity of information for downstream property prediction tasks. Our method combines variants of the recent TransformerM architecture with Transformer, GNN, and ResNet backbone architectures. Models are trained on the 2D data, 3D data, and image modalities of molecular graphs. We ensemble these models with a HuberRegressor. The models are trained on 4 different train/validation splits of the original train + valid datasets. This yields a winning solution to the 2\textsuperscript{nd} edition of the OGB Large-Scale Challenge (2022) on the PCQM4Mv2 molecular property prediction dataset. Our proposed method achieves a test-challenge MAE of $0.0723$ and a validation MAE of $0.07145$. Total inference time for our solution is less than 2 hours. We open-source our code at https://github.com/jfpuget/NVIDIA-PCQM4Mv2.
GPU Accelerated Exhaustive Search for Optimal Ensemble of Black-Box Optimization Algorithms
Dec 12, 2020
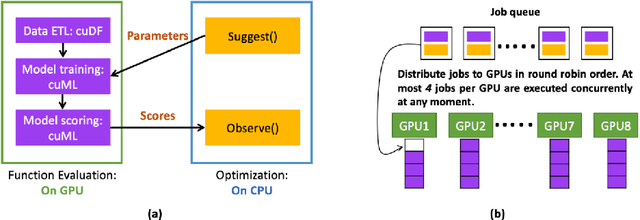

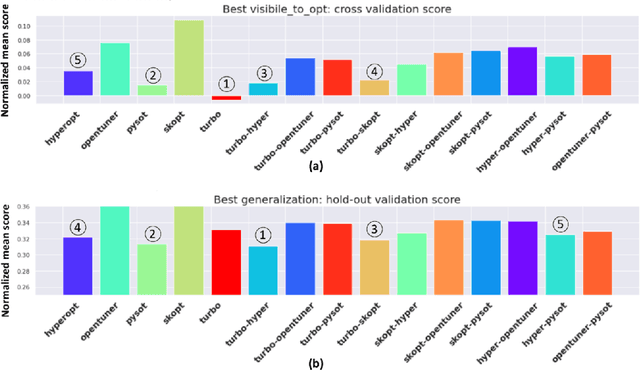
Black-box optimization is essential for tuning complex machine learning algorithms which are easier to experiment with than to understand. In this paper, we show that a simple ensemble of black-box optimization algorithms can outperform any single one of them. However, searching for such an optimal ensemble requires a large number of experiments. We propose a Multi-GPU-optimized framework to accelerate a brute force search for the optimal ensemble of black-box optimization algorithms by running many experiments in parallel. The lightweight optimizations are performed by CPU while expensive model training and evaluations are assigned to GPUs. We evaluate 15 optimizers by training 2.7 million models and running 541,440 optimizations. On a DGX-1, the search time is reduced from more than 10 days on two 20-core CPUs to less than 24 hours on 8-GPUs. With the optimal ensemble found by GPU-accelerated exhaustive search, we won the 2nd place of NeurIPS 2020 black-box optimization challenge.