 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetoxifying Language Models Risks Marginalizing Minority Voices
Paper and Code
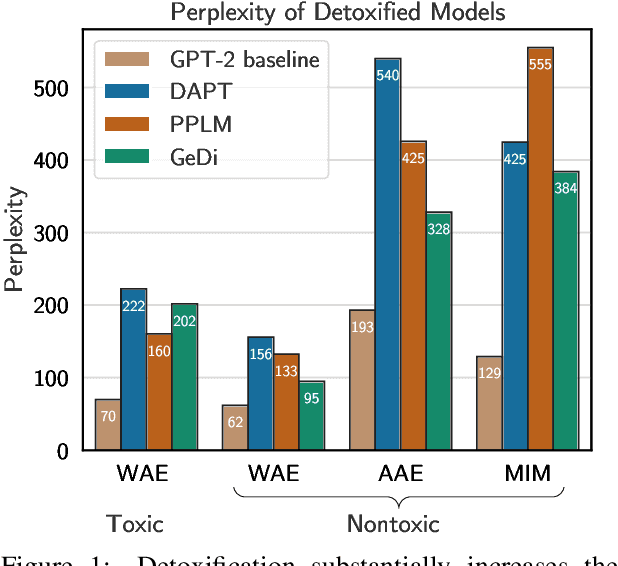



Language models (LMs) must be both safe and equitable to be responsibly deployed in practice. With safety in mind, numerous detoxification techniques (e.g., Dathathri et al. 2020; Krause et al. 2020) have been proposed to mitigate toxic LM generations. In this work, we show that current detoxification techniques hurt equity: they decrease the utility of LMs on language used by marginalized groups (e.g., African-American English and minority identity mentions). In particular, we perform automatic and human evaluations of text generation quality when LMs are conditioned on inputs with different dialects and group identifiers. We find that detoxification makes LMs more brittle to distribution shift, especially on language used by marginalized groups. We identify that these failures stem from detoxification methods exploiting spurious correlations in toxicity datasets. Overall, our results highlight the tension between the controllability and distributional robustness of LMs.