 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPNet: Towards Minimal Face Detector
Mar 17, 2020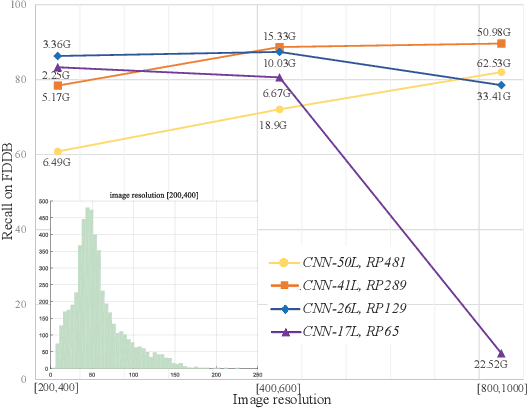

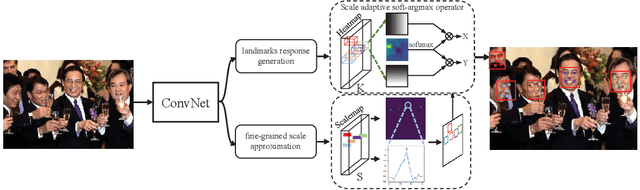
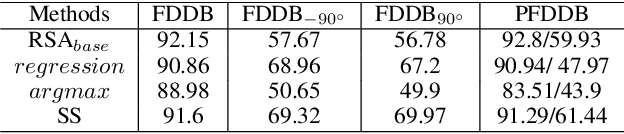
The small receptive field and capacity of minimal neural networks limit their performance when using them to be the backbone of detectors. In this work, we find that the appearance feature of a generic face is discriminative enough for a tiny and shallow neural network to verify from the background. And the essential barriers behind us are 1) the vague definition of the face bounding box and 2) tricky design of anchor-boxes or receptive field. Unlike most top-down methods for joint face detection and alignment, the proposed KPNet detects small facial keypoints instead of the whole face by in a bottom-up manner. It first predicts the facial landmarks from a low-resolution image via the well-designed fine-grained scale approximation and scale adaptive soft-argmax operator. Finally, the precise face bounding boxes, no matter how we define it, can be inferred from the keypoints. Without any complex head architecture or meticulous network designing, the KPNet achieves state-of-the-art accuracy on generic face detection and alignment benchmarks with only $\sim1M$ parameters, which runs at 1000fps on GPU and is easy to perform real-time on most modern front-end chips.
ODN: Opening the Deep Network for Open-set Action Recognition
Jan 23, 2019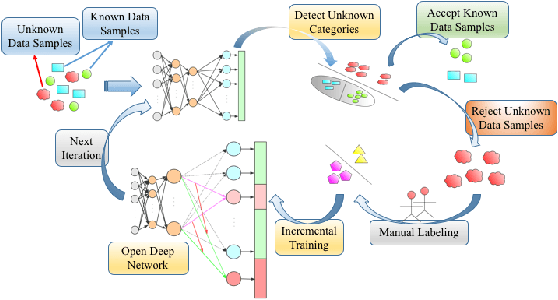
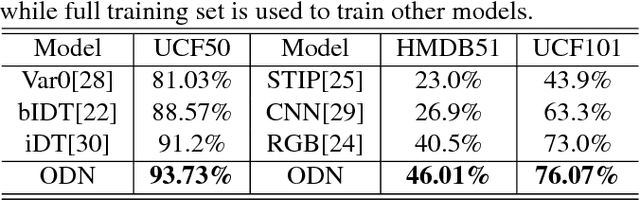

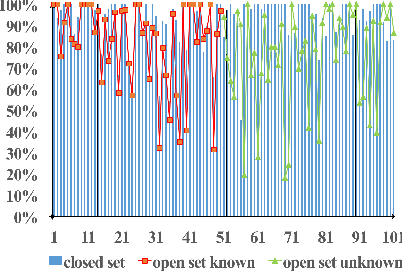
In recent years, the performance of action recognition has been significantly improved with the help of deep neural networks. Most of the existing action recognition works hold the \textit{closed-set} assumption that all action categories are known beforehand while deep networks can be well trained for these categories. However, action recognition in the real world is essentially an \textit{open-set} problem, namely, it is impossible to know all action categories beforehand and consequently infeasible to prepare sufficient training samples for those emerging categories. In this case, applying closed-set recognition methods will definitely lead to unseen-category errors. To address this challenge, we propose the Open Deep Network (ODN) for the open-set action recognition task. Technologically, ODN detects new categories by applying a multi-class triplet thresholding method, and then dynamically reconstructs the classification layer and "opens" the deep network by adding predictors for new categories continually. In order to transfer the learned knowledge to the new category, two novel methods, Emphasis Initialization and Allometry Training, are adopted to initialize and incrementally train the new predictor so that only few samples are needed to fine-tune the model. Extensive experiments show that ODN can effectively detect and recognize new categories with little human intervention, thus applicable to the open-set action recognition tasks in the real world. Moreover, ODN can even achieve comparable performance to some closed-set methods.