 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Guided Inference of Transformer for High-resolution Image Synthesis
Oct 11, 2022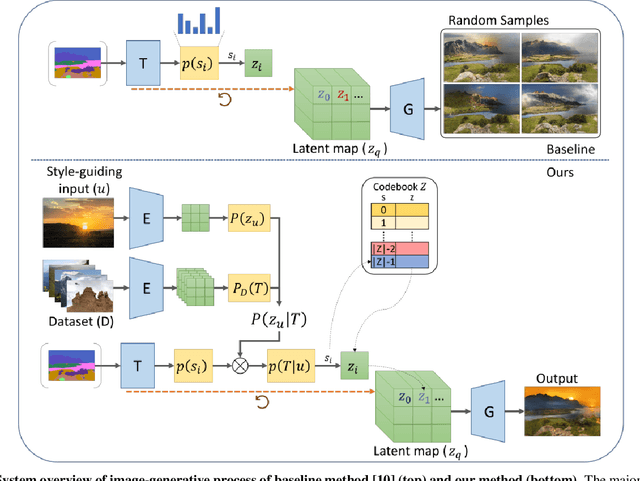


Transformer is eminently suitable for auto-regressive image synthesis which predicts discrete value from the past values recursively to make up full image. Especially, combined with vector quantised latent representation, the state-of-the-art auto-regressive transformer displays realistic high-resolution images. However, sampling the latent code from discrete probability distribution makes the output unpredictable. Therefore, it requires to generate lots of diverse samples to acquire desired outputs. To alleviate the process of generating lots of samples repetitively, in this article, we propose to take a desired output, a style image, as an additional condition without re-training the transformer. To this end, our method transfers the style to a probability constraint to re-balance the prior, thereby specifying the target distribution instead of the original prior. Thus, generated samples from the re-balanced prior have similar styles to reference style. In practice, we can choose either an image or a category of images as an additional condition. In our qualitative assessment, we show that styles of majority of outputs are similar to the input style.
StyLandGAN: A StyleGAN based Landscape Image Synthesis using Depth-map
May 13, 2022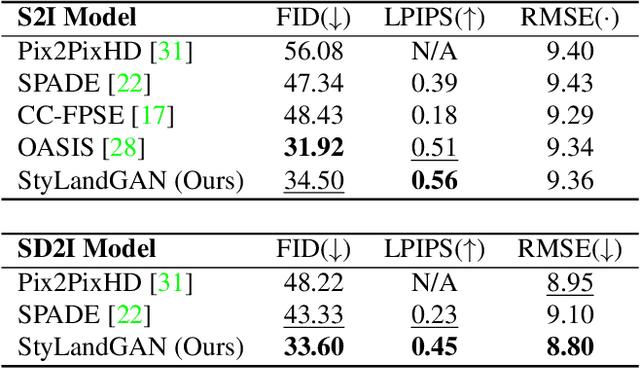

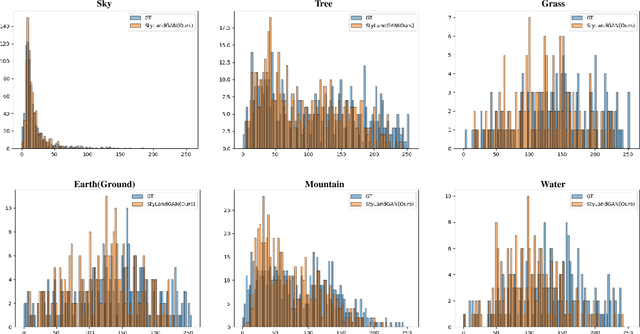
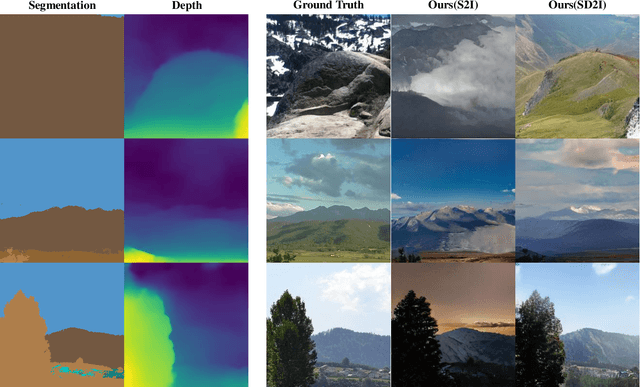
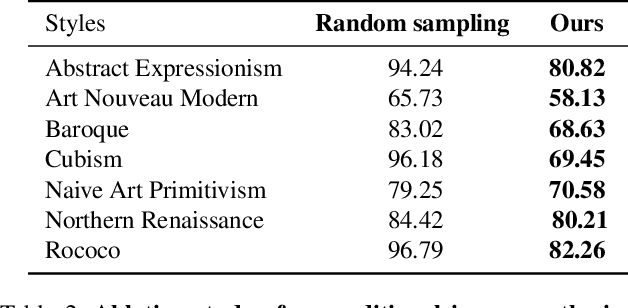
Despite recent success in conditional image synthesis, prevalent input conditions such as semantics and edges are not clear enough to express `Linear (Ridges)' and `Planar (Scale)' representations. To address this problem, we propose a novel framework StyLandGAN, which synthesizes desired landscape images using a depth map which has higher expressive power. Our StyleLandGAN is extended from the unconditional generation model to accept input conditions. We also propose a '2-phase inference' pipeline which generates diverse depth maps and shifts local parts so that it can easily reflect user's intend. As a comparison, we modified the existing semantic image synthesis models to accept a depth map as well. Experimental results show that our method is superior to existing methods in quality, diversity, and depth-accuracy.
Learning Boost by Exploiting the Auxiliary Task in Multi-task Domain
Aug 05, 2020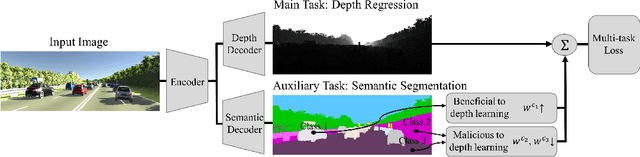



Learning two tasks in a single shared function has some benefits. Firstly by acquiring information from the second task, the shared function leverages useful information that could have been neglected or underestimated in the first task. Secondly, it helps to generalize the function that can be learned using generally applicable information for both tasks. To fully enjoy these benefits, Multi-task Learning (MTL) has long been researched in various domains such as computer vision, language understanding, and speech synthesis. While MTL benefits from the positive transfer of information from multiple tasks, in a real environment, tasks inevitably have a conflict between them during the learning phase, called negative transfer. The negative transfer hampers function from achieving the optimality and degrades the performance. To solve the problem of the task conflict, previous works only suggested partial solutions that are not fundamental, but ad-hoc. A common approach is using a weighted sum of losses. The weights are adjusted to induce positive transfer. Paradoxically, this kind of solution acknowledges the problem of negative transfer and cannot remove it unless the weight of the task is set to zero. Therefore, these previous methods had limited success. In this paper, we introduce a novel approach that can drive positive transfer and suppress negative transfer by leveraging class-wise weights in the learning process. The weights act as an arbitrator of the fundamental unit of information to determine its positive or negative status to the main task.
Filter Style Transfer between Photos
Jul 15, 2020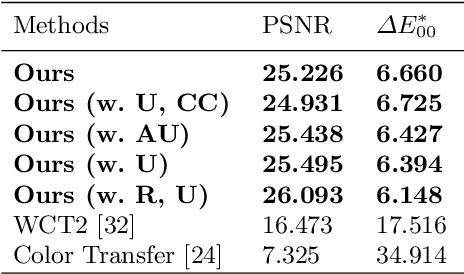
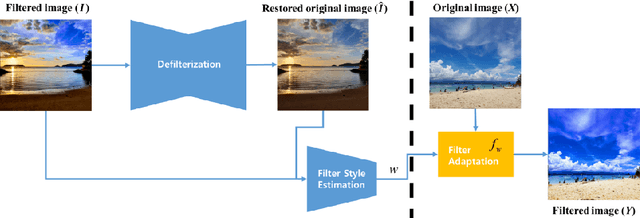


Over the past few years, image-to-image style transfer has risen to the frontiers of neural image processing. While conventional methods were successful in various tasks such as color and texture transfer between images, none could effectively work with the custom filter effects that are applied by users through various platforms like Instagram. In this paper, we introduce a new concept of style transfer, Filter Style Transfer (FST). Unlike conventional style transfer, new technique FST can extract and transfer custom filter style from a filtered style image to a content image. FST first infers the original image from a filtered reference via image-to-image translation. Then it estimates filter parameters from the difference between them. To resolve the ill-posed nature of reconstructing the original image from the reference, we represent each pixel color of an image to class mean and deviation. Besides, to handle the intra-class color variation, we propose an uncertainty based weighted least square method for restoring an original image. To the best of our knowledge, FST is the first style transfer method that can transfer custom filter effects between FHD image under 2ms on a mobile device without any textual context loss.
One-Shot Item Search with Multimodal Data
Nov 28, 2018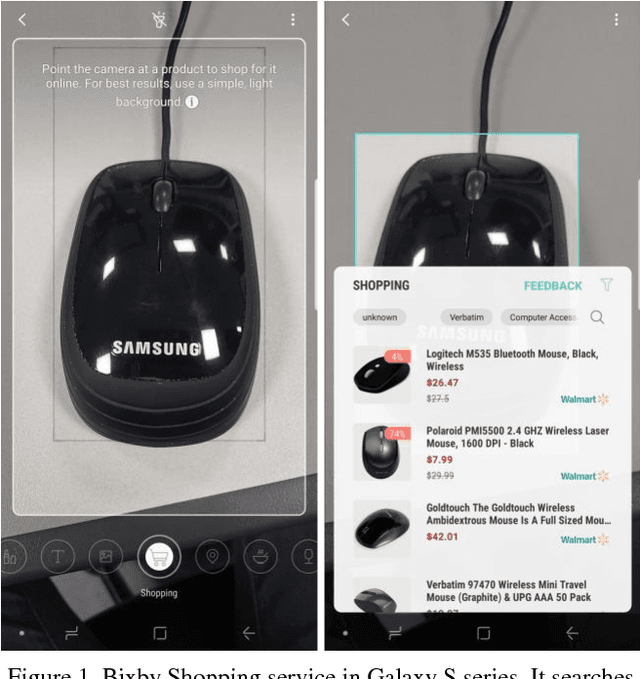
In the task of near similar image search, features from Deep Neural Network is often used to compare images and measure similarity. In the past, we only focused visual search in image dataset without text data. However, since deep neural network emerged, the performance of visual search becomes high enough to apply it in many industries from 3D data to multimodal data. Compared to the needs of multimodal search, there has not been sufficient researches. In this paper, we present a method of near similar search with image and text multimodal dataset. Earlier time, similar image search, especially when searching shopping items, treated image and text separately to search similar items and reorder the results. This regards two tasks of image search and text matching as two different tasks. Our method, however, explore the vast data to compute k-nearest neighbors using both image and text. In our experiment of similar item search, our system using multimodal data shows better performance than single data while it only increases minute computing time. For the experiment, we collected more than 15 million of accessory and six million of digital product items from online shopping websites, in which the product item comprises item images, titles, categories, and descriptions. Then we compare the performance of multimodal searching to single space searching in these datasets.
Investigating the feature collection for semantic segmentation via single skip connection
Oct 23, 2017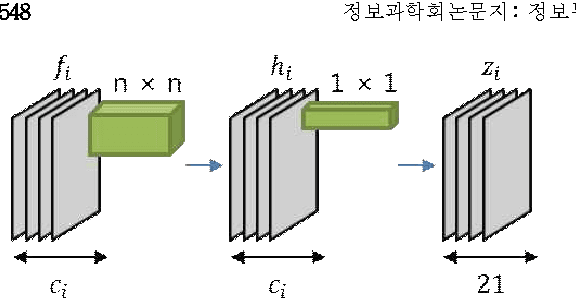
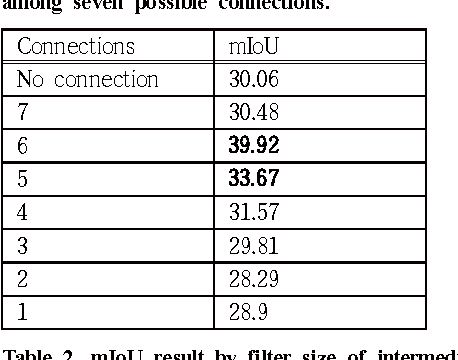
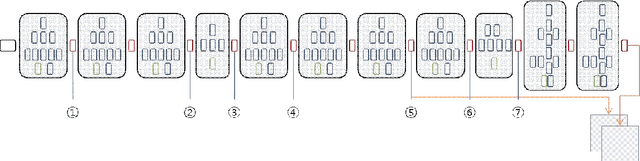
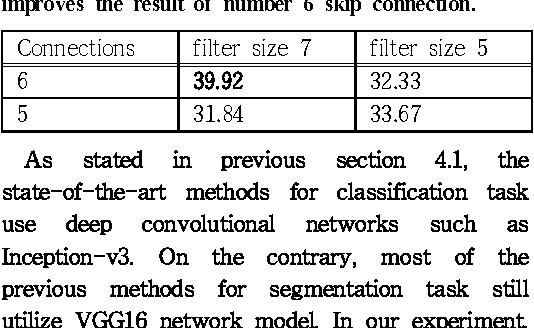
Since the study of deep convolutional neural network became prevalent, one of the important discoveries is that a feature map from a convolutional network can be extracted before going into the fully connected layer and can be used as a saliency map for object detection. Furthermore, the model can use features from each different layer for accurate object detection: the features from different layers can have different properties. As the model goes deeper, it has many latent skip connections and feature maps to elaborate object detection. Although there are many intermediate layers that we can use for semantic segmentation through skip connection, still the characteristics of each skip connection and the best skip connection for this task are uncertain. Therefore, in this study, we exhaustively research skip connections of state-of-the-art deep convolutional networks and investigate the characteristics of the features from each intermediate layer. In addition, this study would suggest how to use a recent deep neural network model for semantic segmentation and it would therefore become a cornerstone for later studies with the state-of-the-art network models.
Enhancing the Performance of Convolutional Neural Networks on Quality Degraded Datasets
Oct 18, 2017
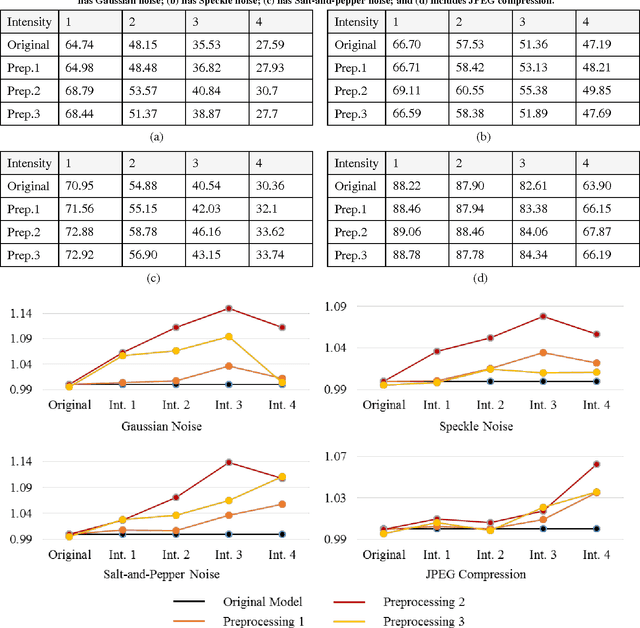

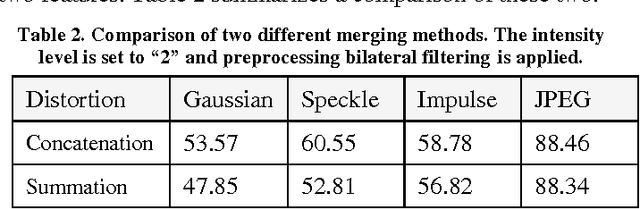
Despite the appeal of deep neural networks that largely replace the traditional handmade filters, they still suffer from isolated cases that cannot be properly handled only by the training of convolutional filters. Abnormal factors, including real-world noise, blur, or other quality degradations, ruin the output of a neural network. These unexpected problems can produce critical complications, and it is surprising that there has only been minimal research into the effects of noise in the deep neural network model. Therefore, we present an exhaustive investigation into the effect of noise in image classification and suggest a generalized architecture of a dual-channel model to treat quality degraded input images. We compare the proposed dual-channel model with a simple single model and show it improves the overall performance of neural networks on various types of quality degraded input datasets.