 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESSENTIAL: Episodic and Semantic Memory Integration for Video Class-Incremental Learning
Aug 14, 2025In this work, we tackle the problem of video classincremental learning (VCIL). Many existing VCIL methods mitigate catastrophic forgetting by rehearsal training with a few temporally dense samples stored in episodic memory, which is memory-inefficient. Alternatively, some methods store temporally sparse samples, sacrificing essential temporal information and thereby resulting in inferior performance. To address this trade-off between memory-efficiency and performance, we propose EpiSodic and SEmaNTIc memory integrAtion for video class-incremental Learning (ESSENTIAL). ESSENTIAL consists of episodic memory for storing temporally sparse features and semantic memory for storing general knowledge represented by learnable prompts. We introduce a novel memory retrieval (MR) module that integrates episodic memory and semantic prompts through cross-attention, enabling the retrieval of temporally dense features from temporally sparse features. We rigorously validate ESSENTIAL on diverse datasets: UCF-101, HMDB51, and Something-Something-V2 from the TCD benchmark and UCF-101, ActivityNet, and Kinetics-400 from the vCLIMB benchmark. Remarkably, with significantly reduced memory, ESSENTIAL achieves favorable performance on the benchmarks.
MASH-VLM: Mitigating Action-Scene Hallucination in Video-LLMs through Disentangled Spatial-Temporal Representations
Mar 20, 2025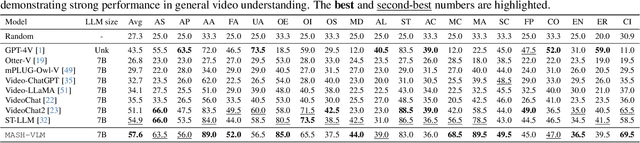
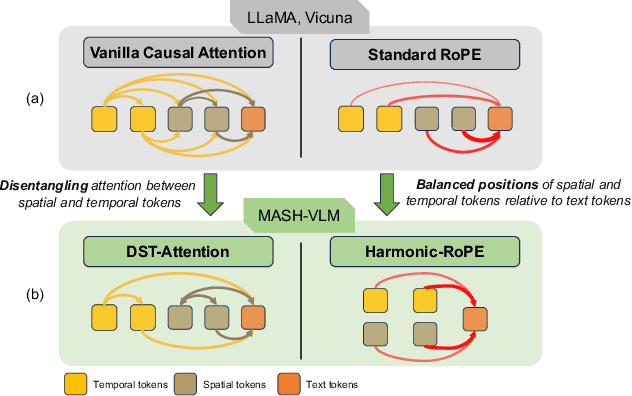
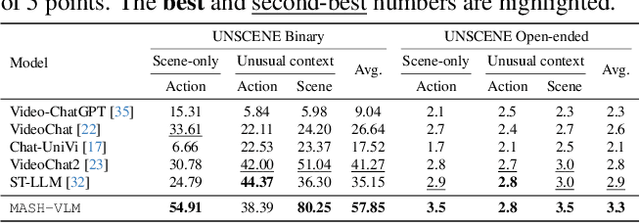
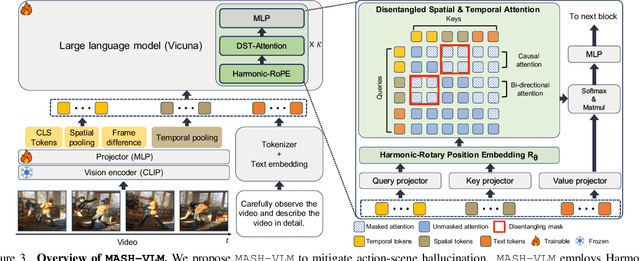
In this work, we tackle action-scene hallucination in Video Large Language Models (Video-LLMs), where models incorrectly predict actions based on the scene context or scenes based on observed actions. We observe that existing Video-LLMs often suffer from action-scene hallucination due to two main factors. First, existing Video-LLMs intermingle spatial and temporal features by applying an attention operation across all tokens. Second, they use the standard Rotary Position Embedding (RoPE), which causes the text tokens to overemphasize certain types of tokens depending on their sequential orders. To address these issues, we introduce MASH-VLM, Mitigating Action-Scene Hallucination in Video-LLMs through disentangled spatial-temporal representations. Our approach includes two key innovations: (1) DST-attention, a novel attention mechanism that disentangles the spatial and temporal tokens within the LLM by using masked attention to restrict direct interactions between the spatial and temporal tokens; (2) Harmonic-RoPE, which extends the dimensionality of the positional IDs, allowing the spatial and temporal tokens to maintain balanced positions relative to the text tokens. To evaluate the action-scene hallucination in Video-LLMs, we introduce the UNSCENE benchmark with 1,320 videos and 4,078 QA pairs. Extensive experiments demonstrate that MASH-VLM achieves state-of-the-art results on the UNSCENE benchmark, as well as on existing video understanding benchmarks.
DEVIAS: Learning Disentangled Video Representations of Action and Scene for Holistic Video Understanding
Nov 30, 2023When watching a video, humans can naturally extract human actions from the surrounding scene context, even when action-scene combinations are unusual. However, unlike humans, video action recognition models often learn scene-biased action representations from the spurious correlation in training data, leading to poor performance in out-of-context scenarios. While scene-debiased models achieve improved performance in out-of-context scenarios, they often overlook valuable scene information in the data. Addressing this challenge, we propose Disentangled VIdeo representations of Action and Scene (DEVIAS), which aims to achieve holistic video understanding. Disentangled action and scene representations with our method could provide flexibility to adjust the emphasis on action or scene information depending on downstream task and dataset characteristics. Disentangled action and scene representations could be beneficial for both in-context and out-of-context video understanding. To this end, we employ slot attention to learn disentangled action and scene representations with a single model, along with auxiliary tasks that further guide slot attention. We validate the proposed method on both in-context datasets: UCF-101 and Kinetics-400, and out-of-context datasets: SCUBA and HAT. Our proposed method shows favorable performance across different datasets compared to the baselines, demonstrating its effectiveness in diverse video understanding scenarios.
GLAD: Global-Local View Alignment and Background Debiasing for Unsupervised Video Domain Adaptation with Large Domain Gap
Nov 22, 2023

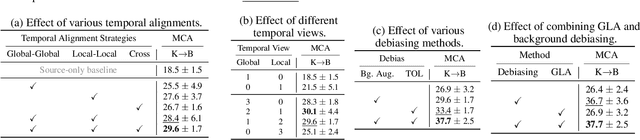
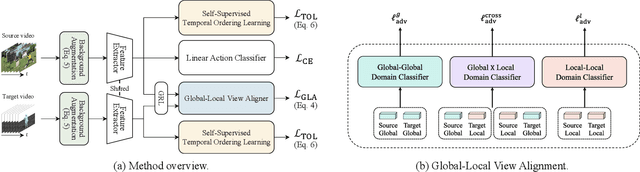
In this work, we tackle the challenging problem of unsupervised video domain adaptation (UVDA) for action recognition. We specifically focus on scenarios with a substantial domain gap, in contrast to existing works primarily deal with small domain gaps between labeled source domains and unlabeled target domains. To establish a more realistic setting, we introduce a novel UVDA scenario, denoted as Kinetics->BABEL, with a more considerable domain gap in terms of both temporal dynamics and background shifts. To tackle the temporal shift, i.e., action duration difference between the source and target domains, we propose a global-local view alignment approach. To mitigate the background shift, we propose to learn temporal order sensitive representations by temporal order learning and background invariant representations by background augmentation. We empirically validate that the proposed method shows significant improvement over the existing methods on the Kinetics->BABEL dataset with a large domain gap. The code is available at https://github.com/KHUVLL/GLAD.